




 本文介绍了强化学习中的动态规划算法,包括策略迭代和价值迭代。通过走格子问题,详细阐述了如何应用这两种算法来找到从起点到奖杯的最佳路径。在策略迭代中,通过迭代更新每个格子的行动概率以获取最高分数;而在价值迭代中,只考虑最大值,简化了过程。实验证明,在该示例中,价值迭代可能表现更优。
本文介绍了强化学习中的动态规划算法,包括策略迭代和价值迭代。通过走格子问题,详细阐述了如何应用这两种算法来找到从起点到奖杯的最佳路径。在策略迭代中,通过迭代更新每个格子的行动概率以获取最高分数;而在价值迭代中,只考虑最大值,简化了过程。实验证明,在该示例中,价值迭代可能表现更优。
第一篇链接:强化学习入门到不想放弃-1 (qq.com)
上节课我们用CMU的经典问题,多臂老虎机讨论了,无状态物体的探索和利用,这节课我们用走格子来做一下动态规划算法
上节课的问题,我们完全不知道这些老虎机的中奖概率,而这节课我们考虑环境是已知的,说白了,我们可以开启上帝视角,动态规划算法,一般也被定义为有模型的算法
那么先说问题,假如我有一个人物(不是勇者),在一个地图上奔跑为了得到最终的奖杯,因为不是勇者所以看到哥布林打手就会被揍死,所以必须要走没有哥布林的格子才能拿到奖杯
现在再给点附加条件玩家初始只有100分,每经过一个格子会扣1分,要求通过强化学习生成一个模型, 从起点到拿到奖杯,分数保留越高越好
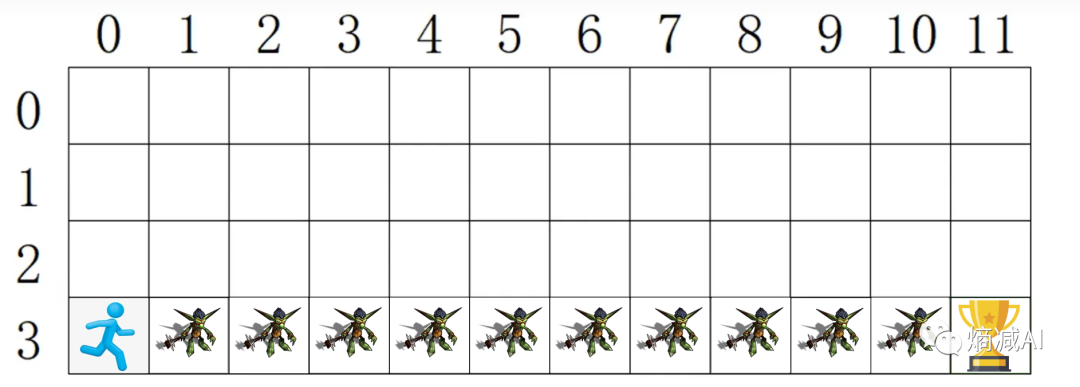
1-策略迭代算法 policy-based
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









