




 本文探讨了微软研究院的Orca模型,该模型通过独特的训练方式学习GPT的推理思路,而非数据。这种方法与传统的指令精调(SFT)不同,它强调学习GPT的思维链(COT)。同时,文章提到了逐步蒸馏的概念,这是一种类似Orca的训练策略,旨在学习大模型的推理过程而非仅关注答案。这两者都展示了在深度学习中权重迁移和效率提升的新途径。
本文探讨了微软研究院的Orca模型,该模型通过独特的训练方式学习GPT的推理思路,而非数据。这种方法与传统的指令精调(SFT)不同,它强调学习GPT的思维链(COT)。同时,文章提到了逐步蒸馏的概念,这是一种类似Orca的训练策略,旨在学习大模型的推理过程而非仅关注答案。这两者都展示了在深度学习中权重迁移和效率提升的新途径。
作为系列的第三章,也算是个小收尾
前两章传送门:
读书人想要点数据,怎么能叫偷呢?要叫借, 也可以叫Self-Instruct (qq.com)
自从Llama诞生以来,几乎已经成为了开源世界的模型标准,而诸多基于Llama重训练和微调的各个版本也应运而生,其中比较有代表性的有以下这些:
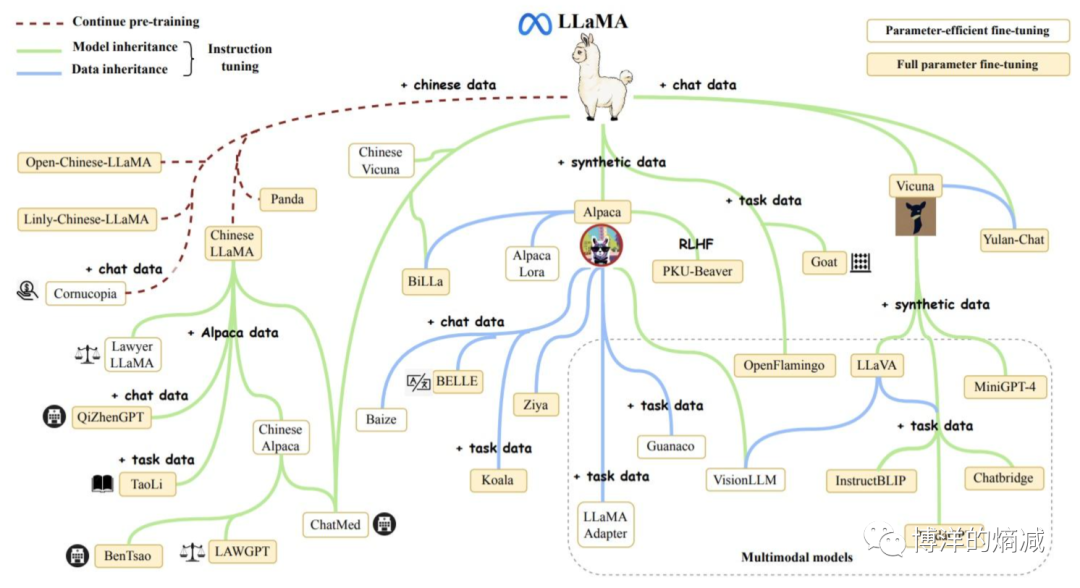
好似庞大的家族图谱一样,说白了,就是基于Llama通过利用不同的数据集,制定差异化的下游任务,不同训练和微调方法产生了多种多样的模型。
然后在羊驼家族里,今年年中的时候混入了一只奇怪的生物Orca,直译就是虎鲸

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 834
834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









