




github开源地址
https://github.com/kortix-ai/suna#
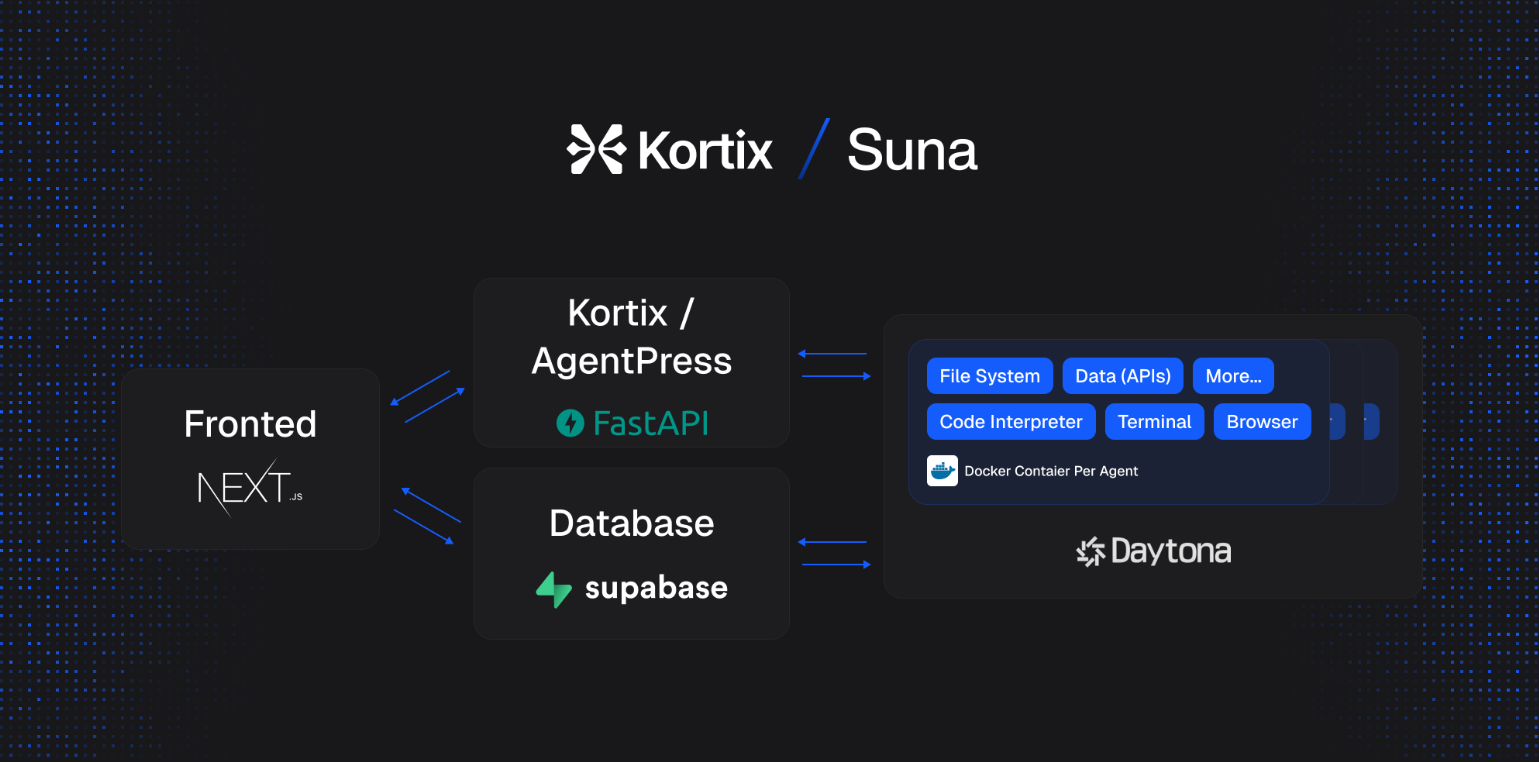
安装前准备
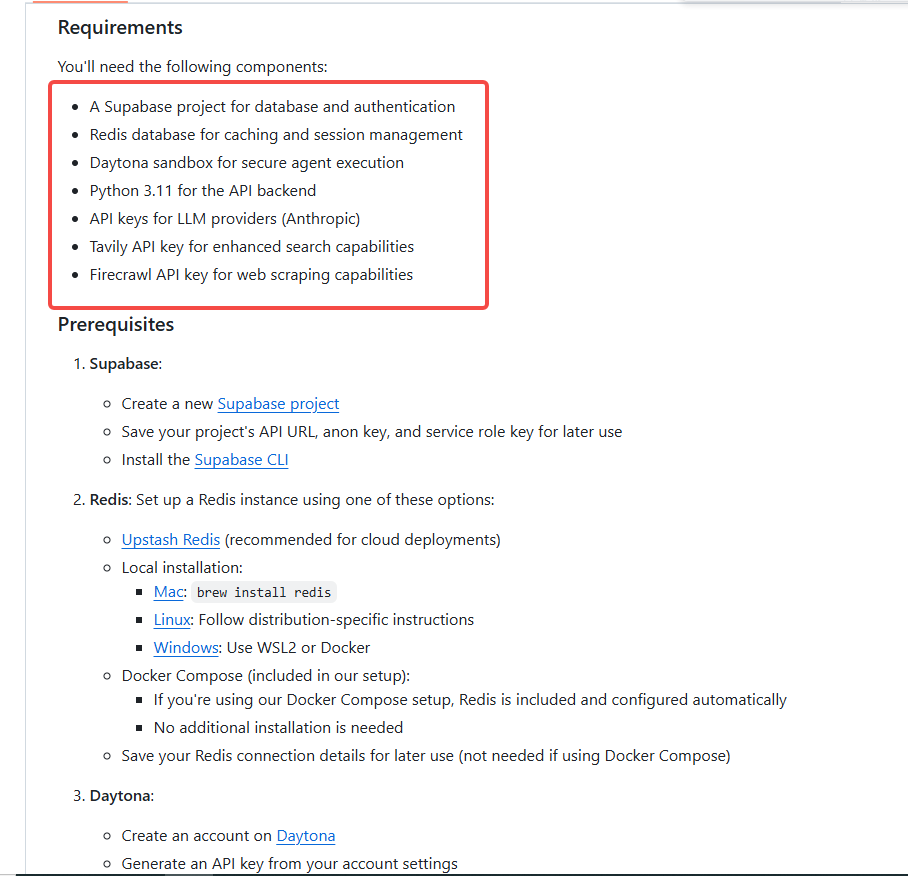
所有的前置安装都需要使用brew安装
安装brew
安装supabase
brew install supabase/tap/supabase
安装redis
sudo apt-get install lsb-release curl gpg
curl -fsSL https://packages.redis.io/gpg | sudo gpg --dearmor -o /usr/share/keyrings/redis-archive-keyring.gpg
sudo chmod 644 /usr/share/keyrings/redis-archive-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/redis-archive-keyring.gpg] https://packages.redis.io/deb $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/redis.list
sudo apt-get update
sudo apt-get install redisRedis will start automatically, and it should restart at boot time. If Redis doesn't start across reboots, you may need to manually enable it:
sudo systemctl enable redis-server
sudo systemctl start redis-server安装daytona
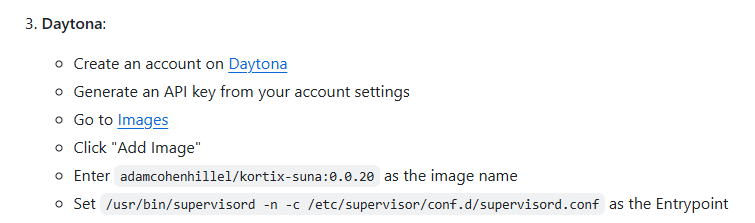
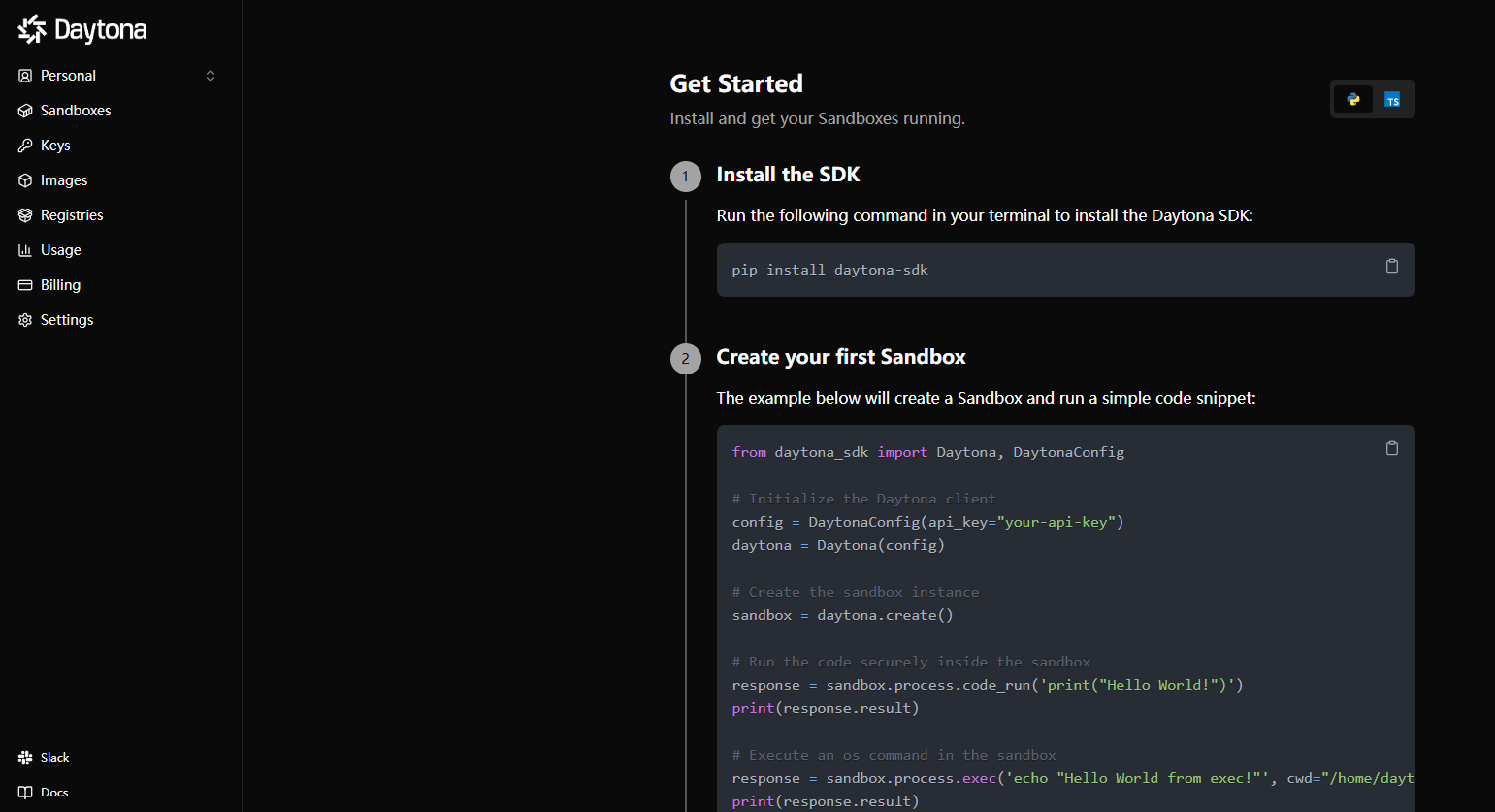
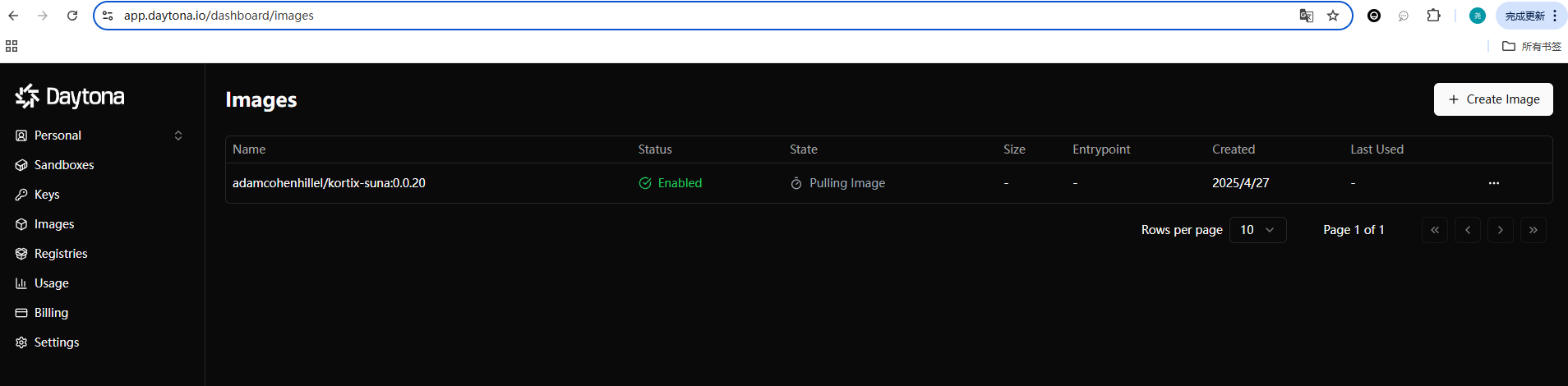
- Set
/usr/bin/supervisord -n -c /etc/supervisor/conf.d/supervisord.confas the Entrypoint
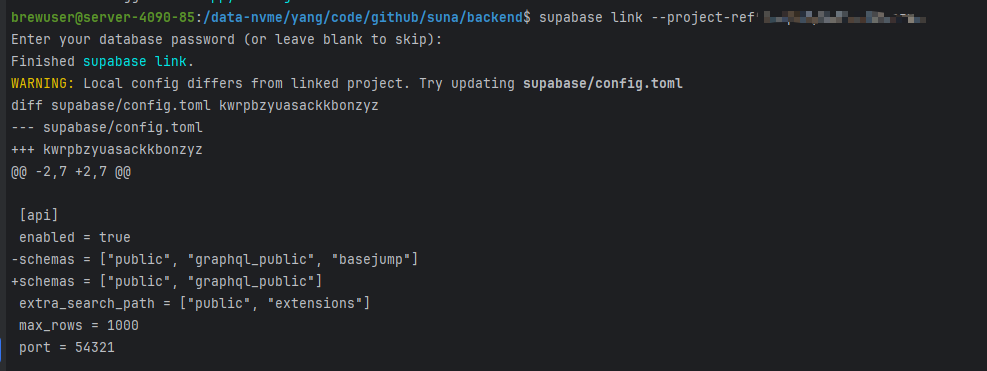
登录supabase(注意要先切换到backend目录下执行)
因为后面的命令都是在相对路径下执行supabase db push会默认调用相对路径下的supabase/migrations下的sql脚本;
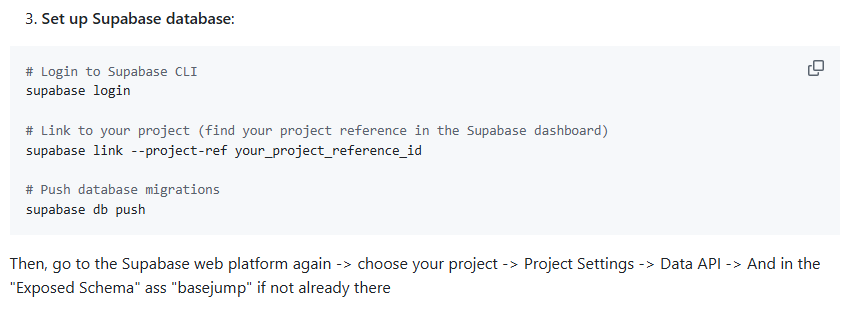
命令1:supabase login
默认密码Test1234
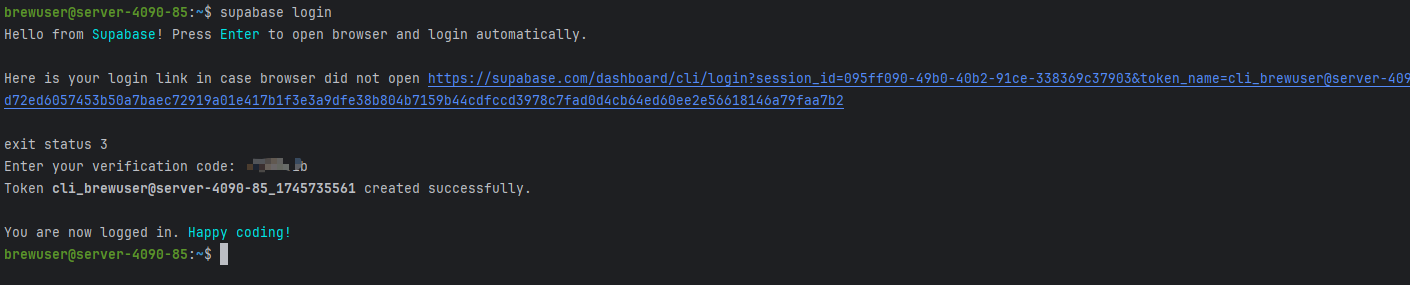
获取project id
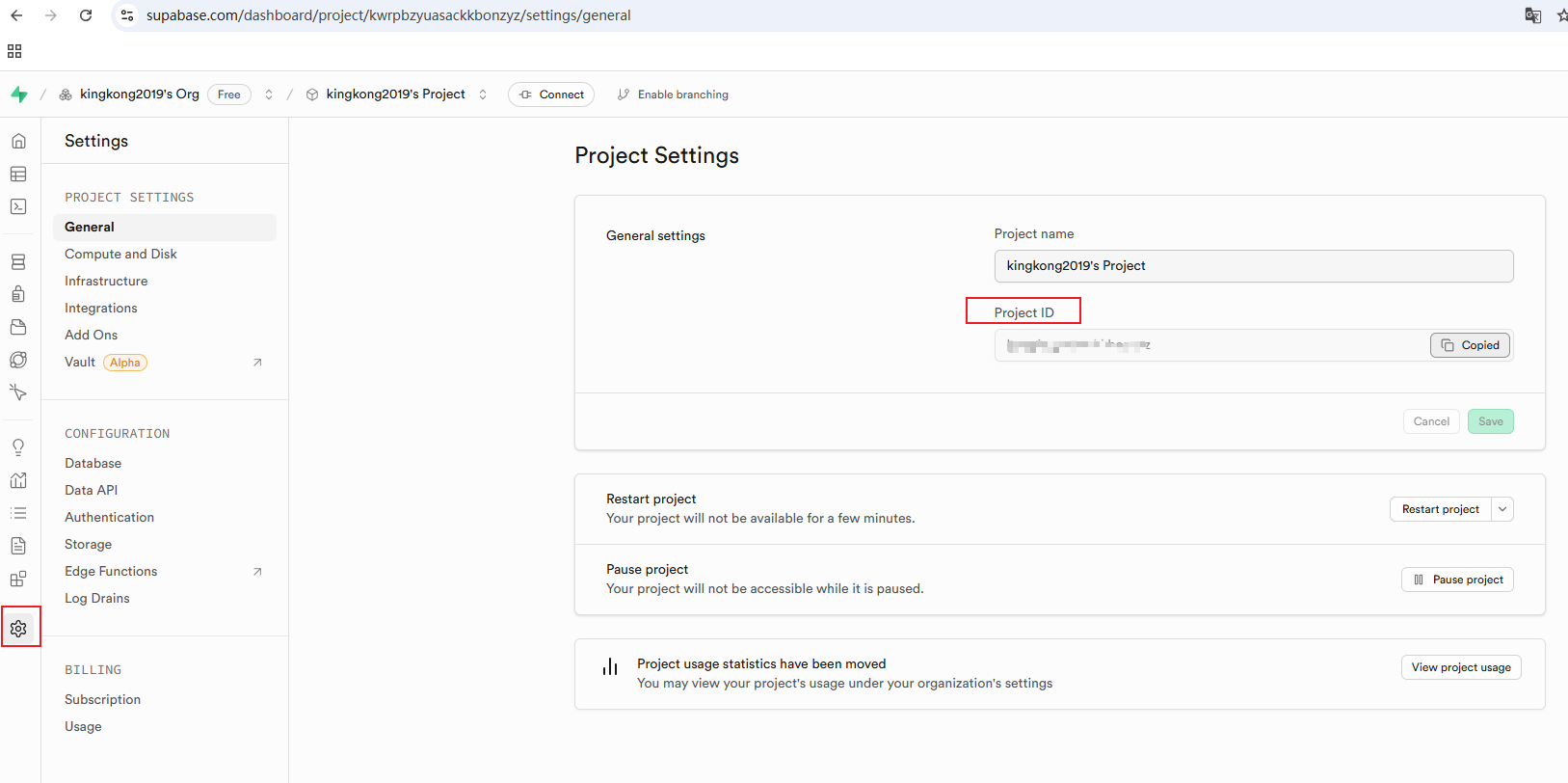
命令2: supabase link project_id
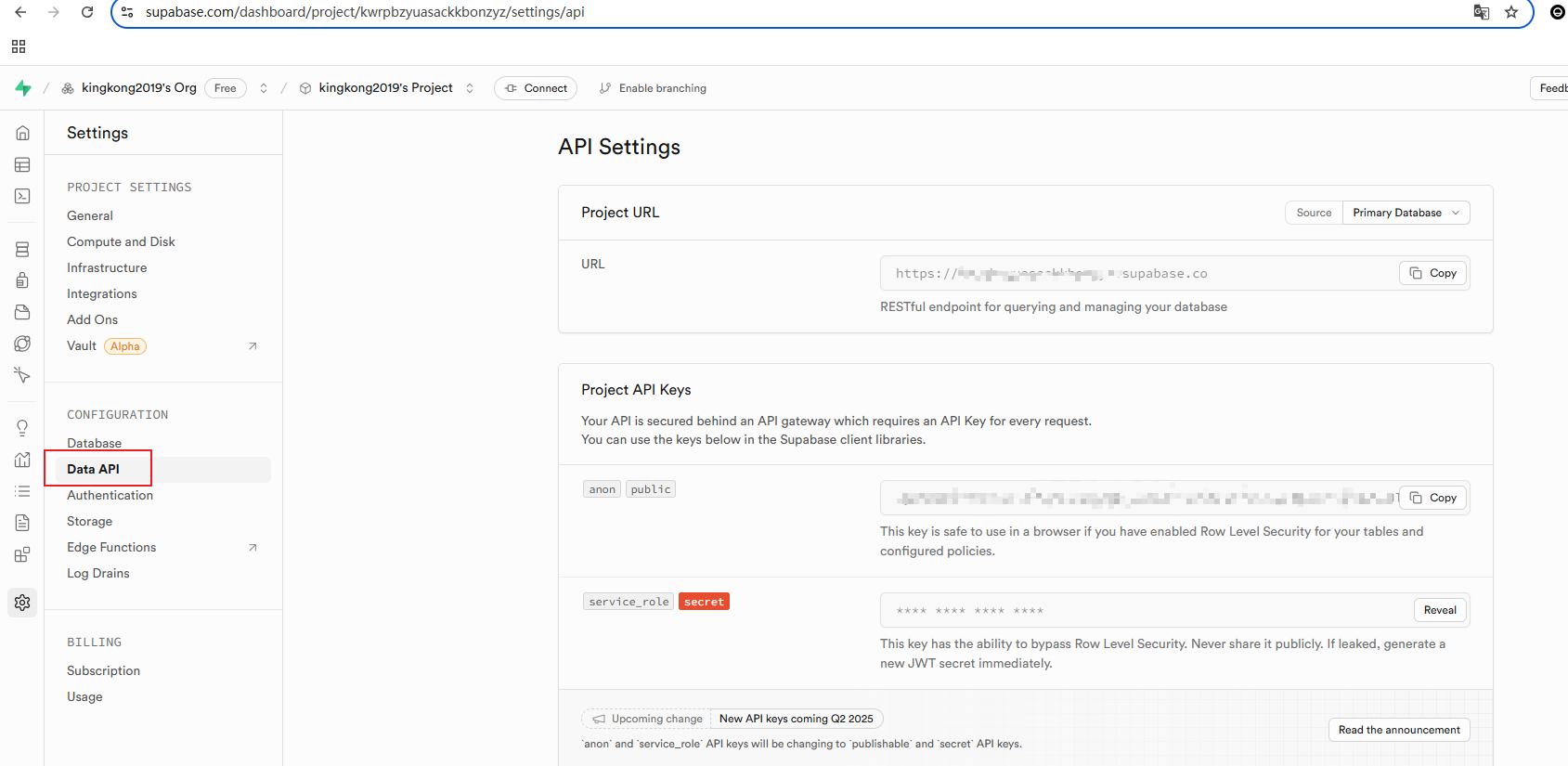
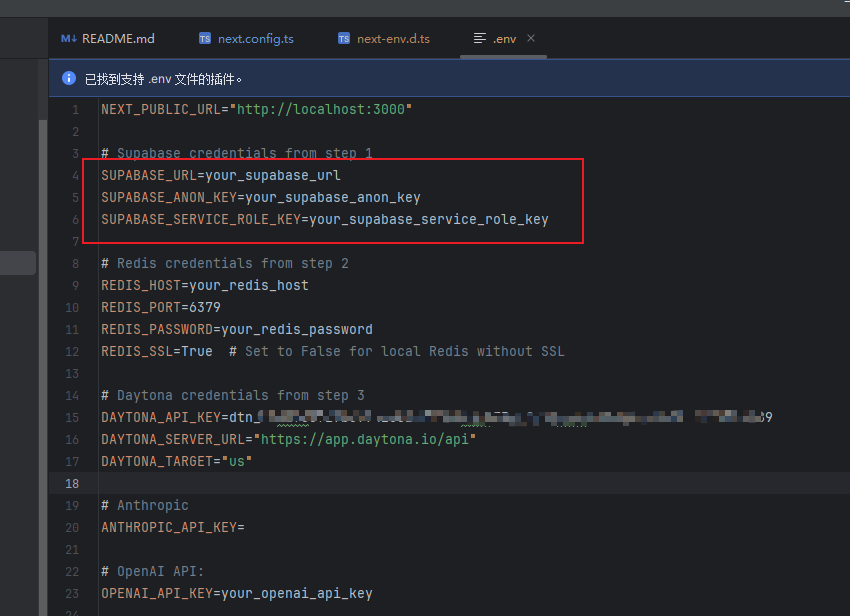
填写对应的supabse信息
在对应的supabse的工程页面获取对应的URL和ANON信息

命令3:supabase db push
正常的效果是这样的:可以看到识别到需要执行的sql语句
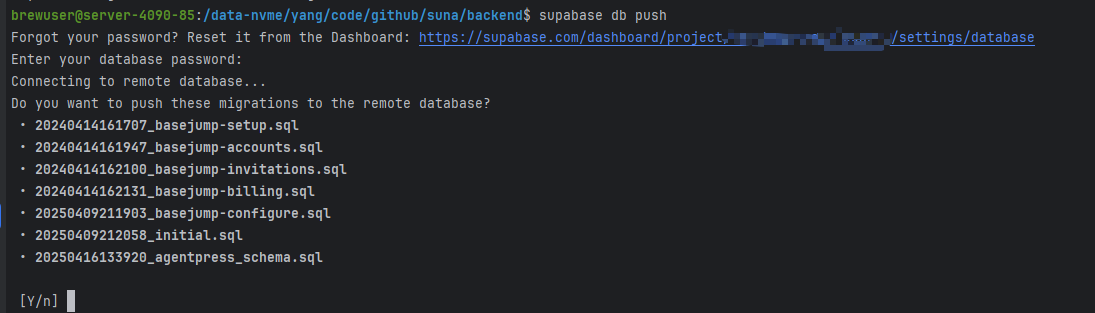
下面的提示是不正常的,sql没有识别到;
解决办法:重新切到backend目录下,执行命令1,2,3;

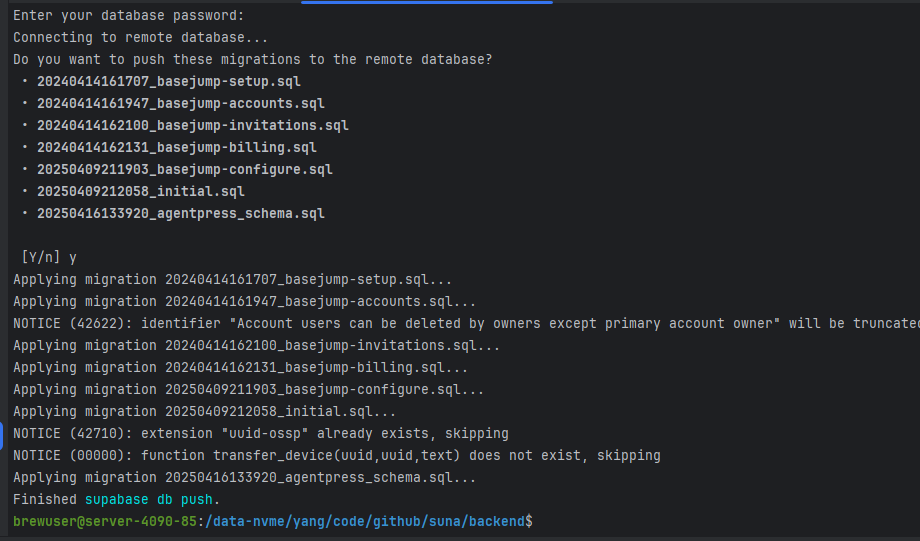
执行成功:
supabase官网server端能看到对应的表创建成功;(没有创建,默认是空的,会提示建表)
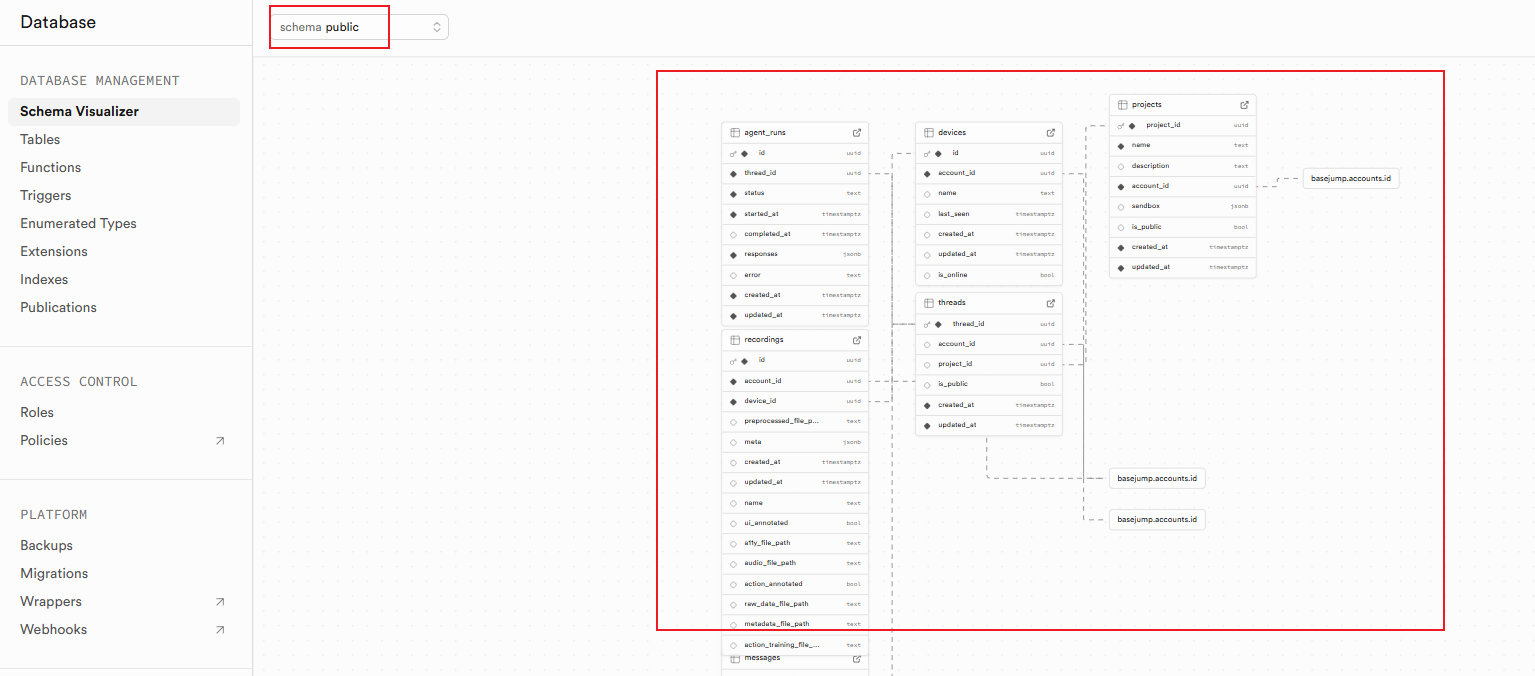
注意:小心漏配

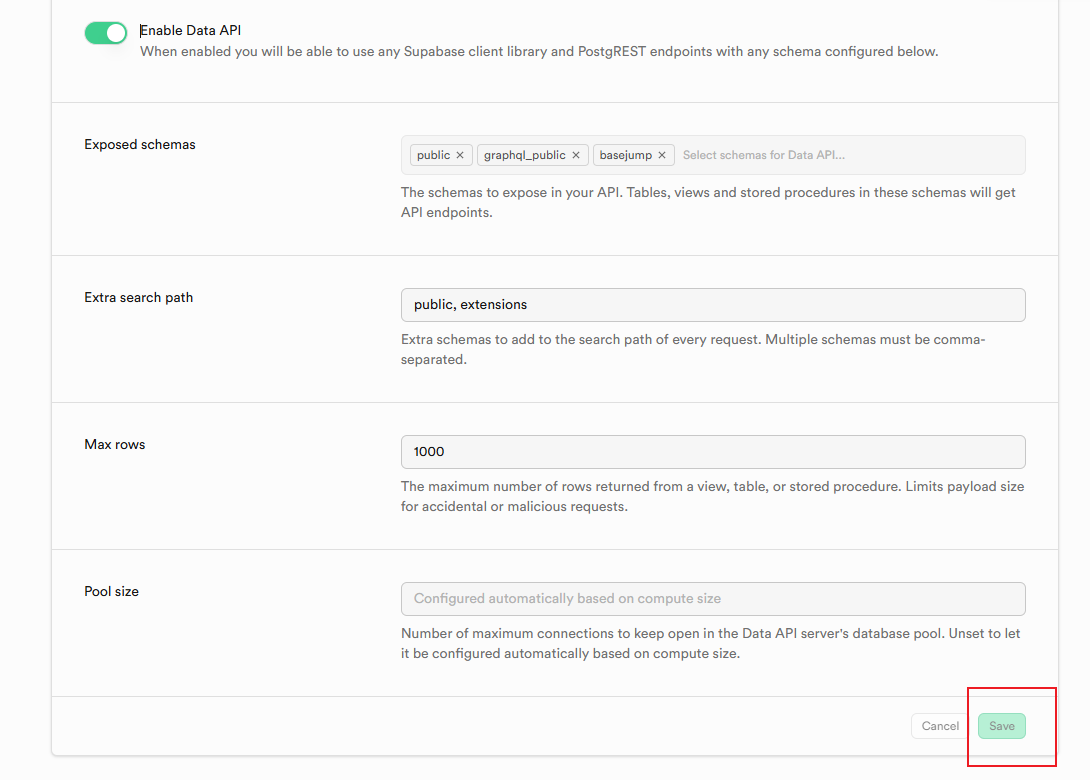
补充勾选basejump:
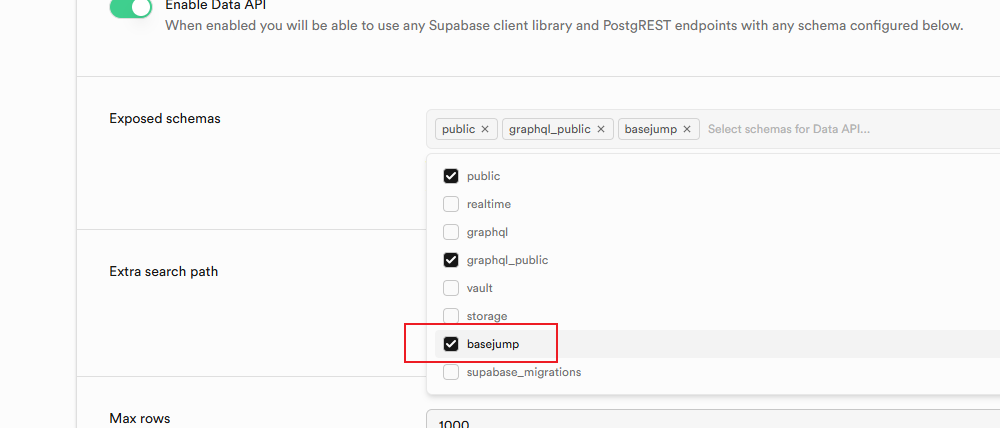
注意,需要点击右下的save按钮才能生效;
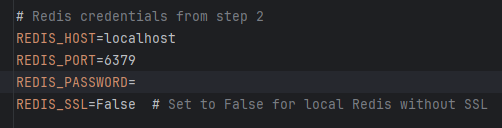
填写redis配置信息
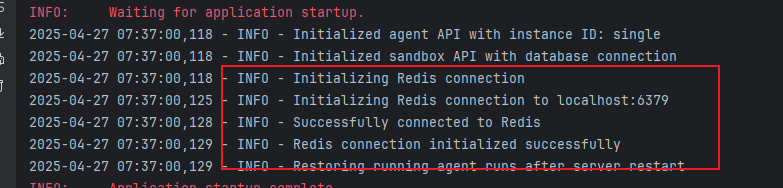
配置正确,后端服务启动成功的提示:
前端
前端编译报错(windows)
ubuntu下无报错;
启动前后端
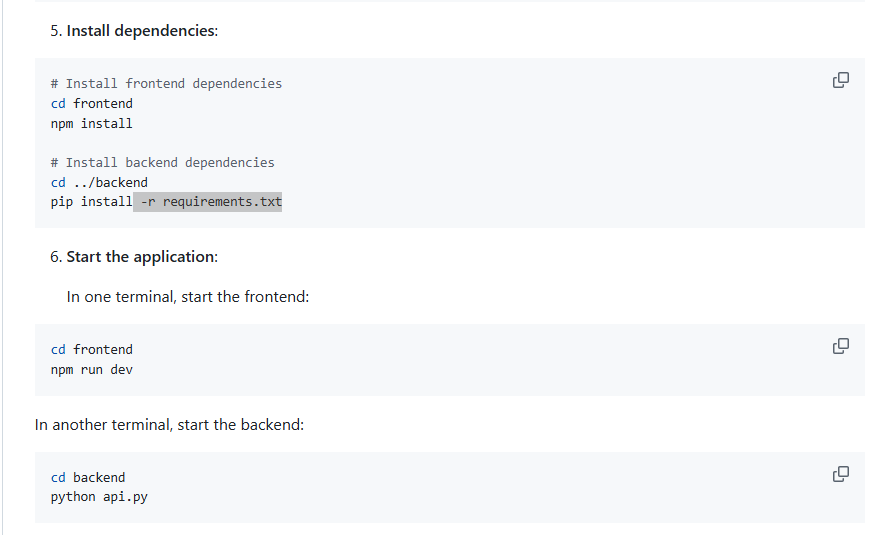
根据启动的信息,访问对应url:
输入需要处理的事情,弹出需要注册:
注册成功:
但是邮箱需要验证后才能使用;
注意这里的邮箱, 在本地调试时,实际验证的URL是LOCALHOST的url地址,并不是类似那种需要发给google邮箱,需要国外邮箱认证的情况;
正常执行的界面:
(本地启动时,在第一个对话框界面耗时会有点长)
然后跳转到下面的界面,开始运行:


执行完成:
总共花了27步,执行过程还不算完美;

点击生成md文件,生效的效果,整体体验还是很不错的:

还能支持下载和导出、并打印;

右边的界面,可以回看每个步骤的详细执行界面的结果;
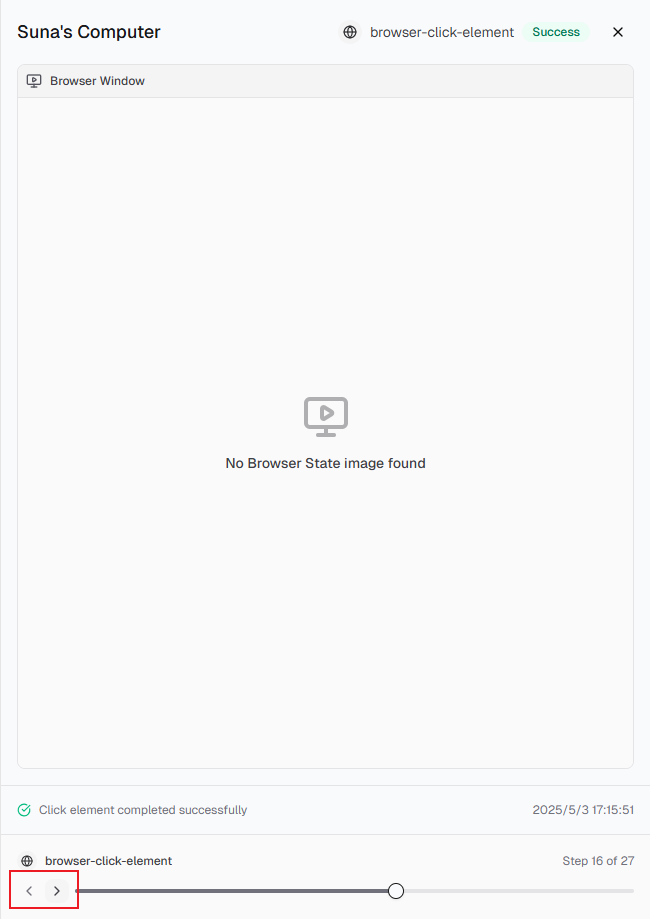
遇到的问题
问题1(close):Failed to create sandbox: Organization is suspended: Depleted credits(规则限制:不超过10个沙箱)
重新创建组织解决,正常daytona是可以面试创建10个沙箱的;
沙箱超限,删除掉不用的即可;
2025-04-28 06:05:35,185 - ERROR - [api.py:384] - Failed to get/create sandbox for project 6abdcfc0-6db9-46e8-ac9c-e9fb73d006c9: Failed to create sandbox: Workspace quota exceeded. Maximum allowed: 10
INFO: 10.239.20.117:58485 - "POST /api/thread/ae279368-c379-49c9-be7a-f37af12a4038/agent/start HTTP/1.1" 500 Internal Server Error

问题2(close):模型 api-key非法
![]()
模型信息设置是在agent\api.py文件中:

还是一样的报错提示;
模型名称是从前端从传入:

前端代码修改模型的调用:

映射到后台的模型是下面的配置文件:
llm.py:关键的大模型调用函数make_llm_api_call;

调用大模型前的参数组装:

实际调用的是agent

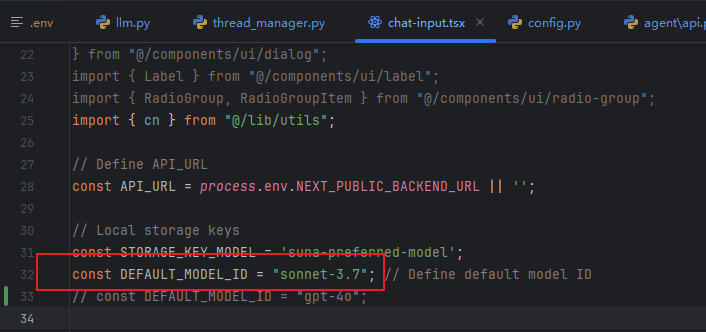
修改agent的默认模型:gtp-4o,根据已有的模型选择;

基于openai封装的claude接口:

增加api_base和api_key的参数传递,确保增加的配置信息生效:


在utils/config.py中增加 自定义的 anthropic地址;
ANTHROPIC_API_BASE、ANTHROPIC_API_KEY(这个在.env中也有配置,但代码调用逻辑每处调用的来源好像不一样,先手动修改确保正确)

问题3(close):删除会话功能不生效(新版本已修复)

问题4(close):任务不往下执行(模型配置正确后解决)

LLM API请求报错:
ANTHROPIC_API_BASE不配置v1时,只配置前端的IP和端口时,会报错:
services2.llm.LLMRetryError: Failed to make API call after 1 attempts. Last error: litellm.APIConnectionError: AnthropicException - b'{\n "error": {\n "type": "forbidden",\n "message": "Request not allowed"\n }\n}'
2025-05-04 02:08:34,804 - ERROR - Error in run_thread: Failed to make API call after 1 attempts. Last error: litellm.APIConnectionError: AnthropicException - b'{\n "error": {\n "type": "forbidden",\n "message": "Request not allowed"\n }\n}'
Traceback (most recent call last):
以下是前后端各个配置模型的地方:



先增加报错的日志打印,看下入参:

根据入参分析:
使用的是原生调用anthropic的接口的方式,但是传入的api_key是openai封装的sk开头的;

以为是openai开头的问题,改成使用anthropic/claude-3-7-sonnet-latest 还是同样的报错:

下一步,通过源码确定调用模型和api_key的位置,目前初步看,模型是通过前端传入,与上面的model_name中的配置没有关系;(至少在当前这一步的报错还没有关系)
首先api_key的获取是在后端;
config.py默认会加载.env中配置的信息;
下一步确认读取api_key的逻辑顺序:

问题5:业务执行的死循环(模型配置正确后解决)
改成指定vpn代理的地址转发到原生的claude调用后,出现业务执行的死循环:

业务执行的死循环:

所以,之前跑通的是基于下面的配置跑通的;
下一步,还是回到解决claude的业务执行死循环的问题:
1、重新启动一个会话,也是会执行到上面的业务死循环,排除直接在旧会话中导致的问题;
2、前端改成gpt-4o后,并重启服务后,也是死循环;
解决办法:
关闭浏览器;重启前端服务后,从最开始界面进入,问题解决;
初步怀疑,是有缓存导致的问题;
回看能完整跑通时的配置:
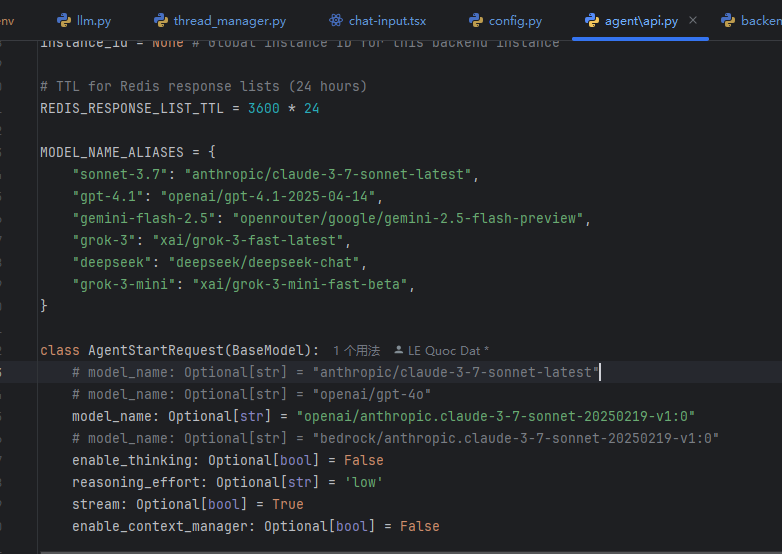
config.py:
这里必须填写v1

但是注意:
anthropic的url地址,不加v1的,端口号3000后面不带v1;
还是会进入死循环:
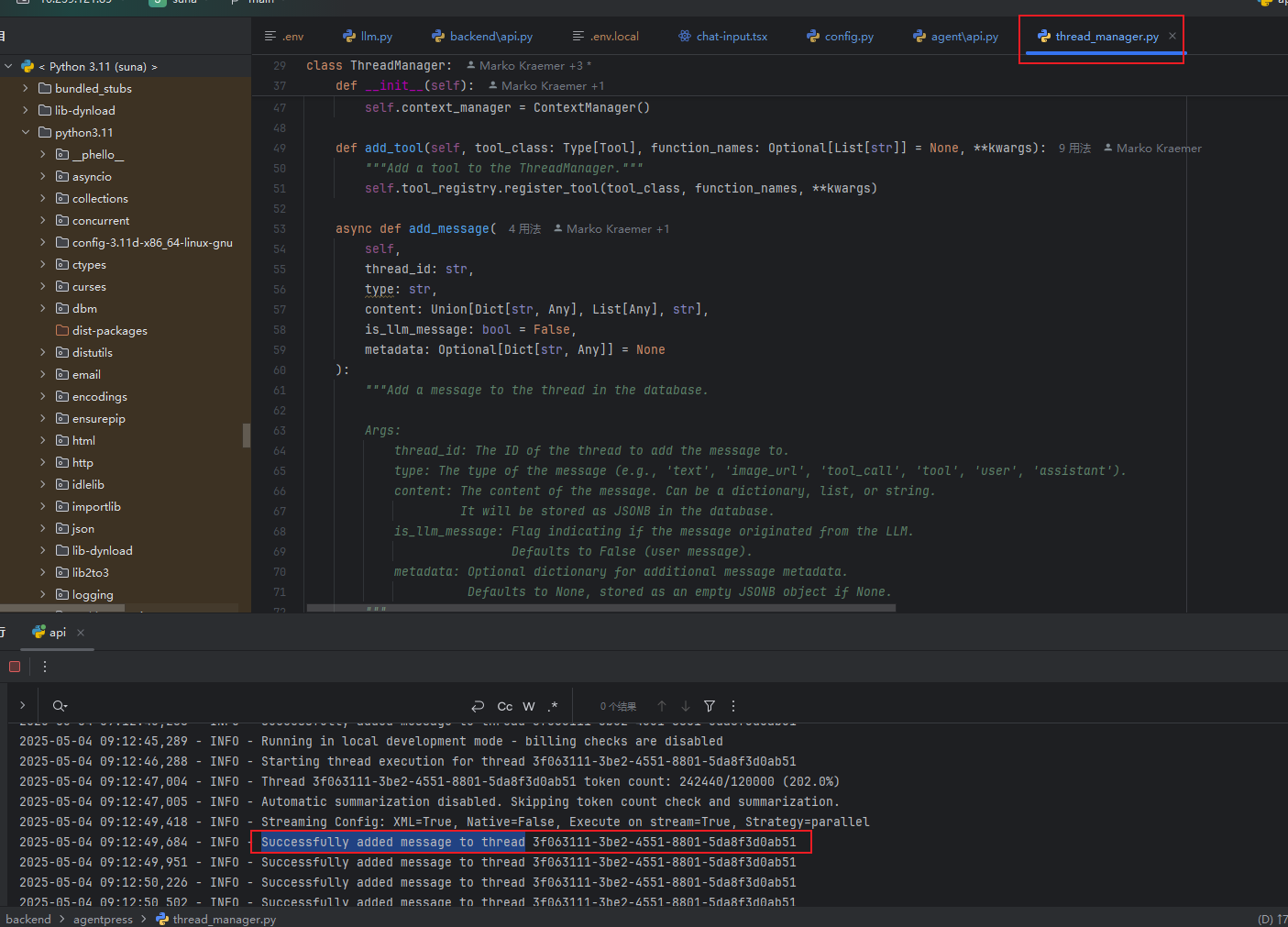
一轮日志:
2025-05-04 09:13:02,236 - INFO - Starting thread execution for thread 3f063111-3be2-4551-8801-5da8f3d0ab51
2025-05-04 09:13:02,963 - INFO - Thread 3f063111-3be2-4551-8801-5da8f3d0ab51 token count: 242440/120000 (202.0%)
2025-05-04 09:13:02,964 - INFO - Automatic summarization disabled. Skipping token count check and summarization.
2025-05-04 09:13:05,412 - INFO - Streaming Config: XML=True, Native=False, Execute on stream=True, Strategy=parallel
2025-05-04 09:13:05,673 - INFO - Successfully added message to thread 3f063111-3be2-4551-8801-5da8f3d0ab51
2025-05-04 09:13:05,939 - INFO - Successfully added message to thread 3f063111-3be2-4551-8801-5da8f3d0ab51
2025-05-04 09:13:06,208 - INFO - Successfully added message to thread 3f063111-3be2-4551-8801-5da8f3d0ab51
2025-05-04 09:13:06,518 - INFO - Successfully added message to thread 3f063111-3be2-4551-8801-5da8f3d0ab51
2025-05-04 09:13:06,520 - INFO - Running in local development mode - billing checks are disabled
async def run_thread

Starting thread execution for thread
async def _run_once 打印下面两行日志:

2025-05-04 09:13:02,963 - INFO - Thread 3f063111-3be2-4551-8801-5da8f3d0ab51 token count: 242440/120000 (202.0%)
2025-05-04 09:13:02,964 - INFO - Automatic summarization disabled. Skipping token count check and summarization.
async def process_streaming_response 调1次

打印:Streaming Config:
async def add_message 会调4次

async def check_billing_status 打印:最后一行billing checks

从上面的分析看,从async def run_thread开始分析:
被run.py调用

run_agent,注意:这里也有一个写死的默认model_name

async def run_agent_background的内部方法:async def check_for_stop_signal()调用了run_agent
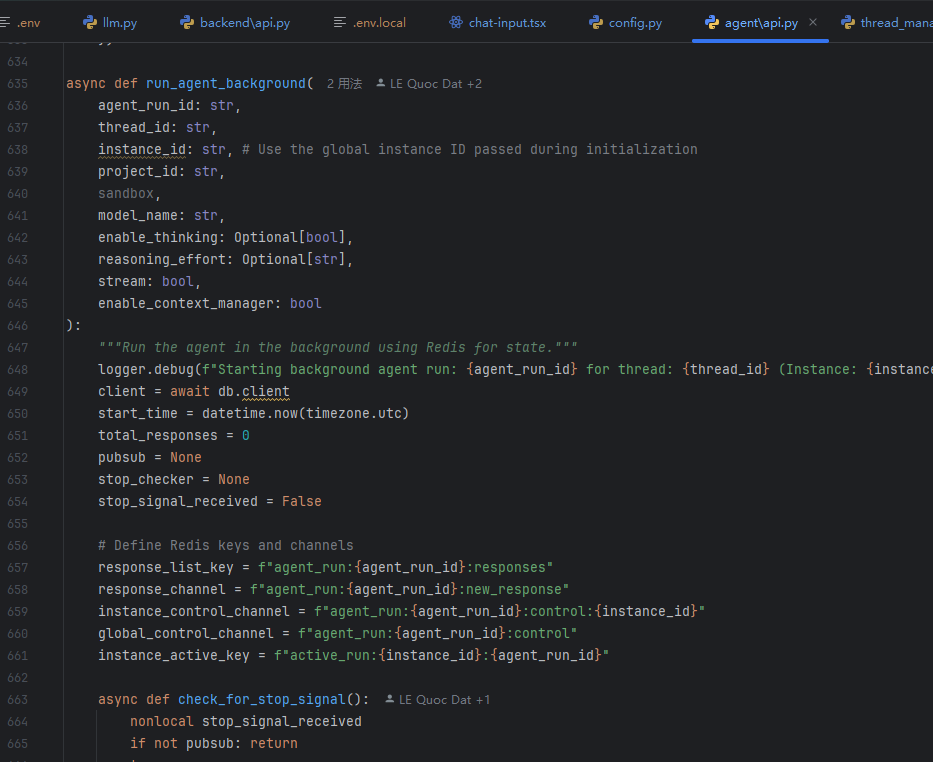

有两个地方会触发线程的启动:
@router.post("/thread/{thread_id}/agent/start")


@router.post("/agent/initiate"

重新观察前后端请求:
对应前端的两处请求发起点

被调用的地方:(待进一步细查)


被调用的地方:(待进一步细查)

差别是在agent的界面发起的命令:前台一样会触发向后端传递模型参数的接口调用;


关键修正点:模型名称填写正确;

重试5次后,每次都正常,未发现业务死循环;(每次都是重新打开浏览器,从下面的界面启动)

问题6(close):模型接口配置问题
2025-05-04 08:53:57,356 - ERROR - Error calculating final cost for stream: This model isn't mapped yet. model=anthropic.claude-3-7-sonnet-20250219-v1:0, custom_llm_provider=openai. Add it here - https://github.com/BerriAI/litellm/blob/main/model_prices_and_context_window.json.
使用了openai标准格式封装的claude接口,不兼容;
(最新版)解决办法:
直接使用claude原生的api_base,可以是公司内网的代理地址;
基于20250505更新的版本,前端代码不需要改动,后端代码改动:
1、llm.py中增加对api_base和api_key的传值;默认在llm的接口调用时,都没有传递这两个值,这两值是通过环境变量或者配置文件获取的;

2、修改config.py,制定模型名称和api_base(这个可以公司内网的代理地址)

3、backend\api.py中增加允许前端请求的url地址,保险起见本地调试时可以设置为*,生产发布时去掉;

suna的前端关键界面代码分析
右边的沙箱界面

supabase使用源码工程默认的调试方案:
npm install supabase
注意不要使用:npm install -g supabase,会报错,默认不允许进行全局安装;

切换到backend目录下,执行:node_modules/supabase/bin/supabase start
启动成功:

生产部署时,屏蔽标准模式的付费跳转问题;

正式正产部署后,会默认跳转到下面的付费页面;

找到下面的代码,并注释掉本地模式的判断,默认都返回true即可;


















 726
726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









