



借助新的填充中间范式,GitHub 工程师改进了 GitHub Copilot 将您的代码情境化的方式。通过继续开发和测试高级检索算法,他们正在努力使我们的 AI 工具更加先进。

为了让 GitHub Copilot 的合作感觉像是开发人员和结对程序员之间的思想交流,GitHub 的机器学习专家一直在忙于研究、开发和测试新功能——其中许多人专注于提高 AI 结对程序员的语境理解能力。这是因为良好的沟通是结对编程的关键,而推断语境对于实现良好的沟通至关重要。
为了揭开帷幕,我们询问了 GitHub 的研究人员和工程师,了解他们正在做哪些工作来帮助 GitHub Copilot 提高其语境理解能力。以下是我们的发现。
从 OpenAI 的 Codex 模型到 GitHub Copilot
当 OpenAI 于 2020 年 6 月发布 GPT-3 时,GitHub 知道开发人员将从一款专门利用该模型进行编码的产品中受益。因此,我们为 OpenAI 提供了意见,因为它构建了 Codex,它是 GPT-3 和 LLM 的后代,将为 GitHub Copilot 提供支持。配对程序员于 2021 年 6 月作为技术预览版推出,并于 2022 年 6 月作为世界上第一个大规模生成式 AI 编码工具全面上市。
为了确保模型拥有最佳信息以快速做出最佳预测,GitHub 的机器学习 (ML) 研究人员做了很多称为提示工程的工作(我们将在下面详细解释),以便模型以低延迟提供与上下文相关的响应。
尽管 GitHub 总是在新模型推出时进行试验,但 Codex 是第一个真正强大的生成式 AI 模型,GitHub 的 ML 工程师 David Slater 说。 “我们通过迭代模型和及时改进所获得的实际经验非常宝贵。”
所有这些实验都促成了结对编程,最终让开发人员有更多时间专注于更有成就感的工作。GitHub 的机器学习研究员 Alice Li 表示,该工具通常对从头开始新项目或新文件有很大帮助,因为它为开发人员提供了一个起点,开发人员可以根据需要进行调整和调整。
为什么上下文很重要
开发人员使用来自拉取请求、项目中的文件夹、未解决的问题等的详细信息来将他们的代码情境化。当谈到生成式 AI 编码工具时,我们需要教会该工具使用哪些信息来做同样的事情。
Transformer LLM 擅长连接点和全局思维。生成式 AI 编码工具是由大型语言模型 (LLM) 实现的。这些模型是针对大量代码和人类语言进行训练的算法集。当今最先进的 LLM 是转换器,这使它们能够擅长在用户输入的文本和模型已经生成的输出之间建立联系。这就是为什么今天的生成式 AI 工具提供的响应比以前的 AI 模型更具上下文相关性。
但他们需要被告知哪些信息与您的代码相关。目前,速度足以为 GitHub Copilot 提供支持的转换器一次可以处理大约 6,000 个字符。虽然这足以推进和加速代码完成和代码更改摘要等任务,但字符数量有限意味着并非所有开发人员的代码都可以用作上下文。
因此,我们的挑战是不仅要弄清楚要向模型提供哪些数据,还要弄清楚如何最好地排序和输入数据,以便为开发人员提供最佳建议。
GitHub Copilot 如何理解您的代码
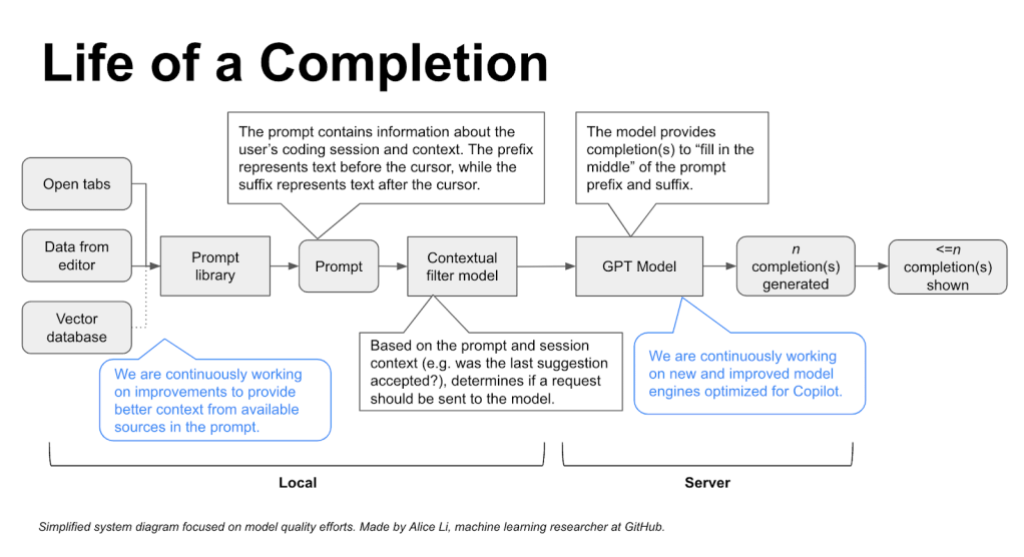
这一切都归结于提示,它是 IDE 代码和相关上下文的汇编,并输入到模型中。提示由后台的算法生成,可以在您编码的任何阶段生成。这就是为什么 GitHub Copilot 会生成编码建议,无论您是正在编写还是刚刚完成注释,或者正在编写一些复杂的代码。
提示的创建方式如下:一系列算法首先从您当前的文件和其他来源(我们将在下面深入介绍)中选择相关的代码片段或注释。然后对这些片段和注释进行优先排序、过滤,并组合成最终的提示。
GitHub Copilot 的上下文理解随着时间的推移不断成熟。第一个版本只能将您在 IDE 中处理的文件视为与上下文相关。但我们知道上下文远不止于此。现在,仅仅一年之后,我们正在试验将考虑您的整个代码库以生成定制建议的算法。
让我们看看我们是如何实现这一点的:
提示工程是创建提示的精妙艺术,以便模型为用户做出最有用的预测。提示告诉 LLM(包括 GitHub Copilot)要处理哪些数据以及以何种顺序处理,以便将代码情境化。大部分工作都在所谓的提示库中进行,我们的内部 ML 专家会使用算法提取和优先处理有关开发人员情境的各种信息源,从而创建将由 GitHub Copilot 模型处理的提示。
相邻选项卡是我们所说的允许 GitHub Copilot 处理开发人员 IDE 中打开的所有文件(而不仅仅是开发人员正在处理的单个文件)的技术。通过打开与其项目相关的所有文件,开发人员会自动调用 GitHub Copilot 来梳理所有数据,并在他们打开的文件和光标周围的代码之间找到匹配的代码片段,并将这些匹配添加到提示中。
在开发相邻选项卡时,GitHub Next 团队和内部 ML 研究人员进行了 A/B 测试,以找出识别 IDE 中的代码与打开的选项卡中的代码之间的匹配的最佳参数。他们发现,设置一个非常低的匹配标准实际上可以得到最好的编码建议。
通过包含每一点上下文,相邻选项卡有助于相对提高用户对 GitHub Copilot 建议的接受度 5%**。
中间填充 (FIM) 范式进一步扩大了上下文范围。在 FIM 之前,只有光标之前的代码才会被放入提示中 — 忽略光标之后的代码。(在 GitHub,我们将光标之前的代码称为前缀,将光标之后的代码称为后缀。)使用 FIM,我们可以告诉模型提示的哪部分是前缀,哪部分是后缀。
即使您从头开始创建某些内容并且拥有文件骨架,我们也知道编码不是线性或连续的。因此,当您在文件中来回切换时,FIM 可帮助 GitHub Copilot 为文件中光标所在的部分或应该位于前缀和后缀之间的代码提供更好的编码建议。
根据 A/B 测试,FIM 的性能相对提升了 10%,这意味着开发人员接受向他们展示的完成内容的比例增加了 10%。并且由于缓存的优化使用,相邻的标签和 FIM 可以在后台工作,而不会增加任何延迟。
提高语义理解
今天,我们正在试验向量数据库,它可以为在私有存储库或专有代码中工作的开发人员创建定制的编码体验。生成式 AI 编码工具使用一种称为嵌入的东西从向量数据库中检索信息。
什么是向量数据库?它是一个索引高维向量的数据库。
什么是高维向量?它们是对象的数学表示,由于这些向量可以在多个维度上对对象进行建模,因此它们可以捕获该对象的复杂性。当正确使用它们来表示代码片段时,它们可能既表示代码的语义,甚至表示代码的意图,而不仅仅是语法。
什么是嵌入?在编码和 LLM 的上下文中,嵌入是将一段代码表示为高维向量。由于 LLM 对编程和自然语言都具有“知识”,因此它能够捕获向量中代码的语法和语义。
它们协同工作的方式如下:
算法将为存储库中的所有代码片段(可能有数十亿个)创建嵌入,并将它们存储在向量数据库中。
然后,在您编写代码时,算法会将代码片段嵌入到您的 IDE 中。
然后,算法将对为您的 IDE 代码片段创建的嵌入和已存储在向量数据库中的嵌入进行近似匹配(也是实时匹配)。向量数据库允许算法在其存储的向量上快速搜索近似匹配(而不仅仅是精确匹配),即使它存储了数十亿个嵌入的代码片段。
GitHub 高级 ML 研究员 Alireza Goudarzi 解释说,开发人员熟悉使用哈希码检索数据,哈希码通常会逐个字符地寻找精确匹配。 “但是,由于嵌入源自经过大量数据训练的 LLM,因此它们会在代码片段和自然语言提示之间产生一种语义接近感。”
阅读下面的三个句子,并找出哪两个句子在语义上最相似。
句子 A:国王移动并捕获了棋子。
句子 B:国王在威斯敏斯特大教堂加冕。
句子 C:两个白车仍在游戏中。
答案是句子 A 和 C,因为它们都是关于国际象棋的。虽然句子 A 和 B 在句法或结构上相似,因为它们都以国王为主语,但它们在语义上不同,因为“国王”在不同的上下文中使用。
如上所述,我们仍在试验检索算法。我们在设计此功能时考虑到了企业客户,特别是那些希望通过私有存储库获得定制编码体验并明确选择使用该功能的客户。
总结
去年,我们对 GitHub Copilot 进行了定量研究,发现使用结对编程时,开发人员的编码速度提高了 55%。这意味着开发人员会感觉更有效率,更快地完成重复性任务,并且可以更专注于令人满意的工作。但我们的工作不会止步于此。
GitHub 产品和研发团队(包括 GitHub Next)一直在与 Microsoft Azure AI-Platform 合作,继续改进 GitHub Copilot 的上下文理解。帮助 GitHub Copilot 将您的代码情境化的大部分工作都是在幕后进行的。在您编写和编辑代码时,GitHub Copilot 会通过生成提示实时响应您的编写和编辑——换句话说,根据您在 IDE 中的操作对相关信息进行优先级排序并发送到模型——以继续为您提供最佳的编码建议。
(本文系翻译)
觉得文章不错,顺手点个“点赞”、“在看”或转发给朋友们吧。

相关阅读:
关于译者

关注公众号看其它原创作品
坚持提供对你有用的信息
觉得好看,点个“点赞”、“在看”或转发给朋友们,欢迎你留言。


















 2208
2208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









