




如何识别吸血鬼?
考虑这些样本数据:(影子那项有些是?,是因为有些人晚上出没,不知道是否有影子)
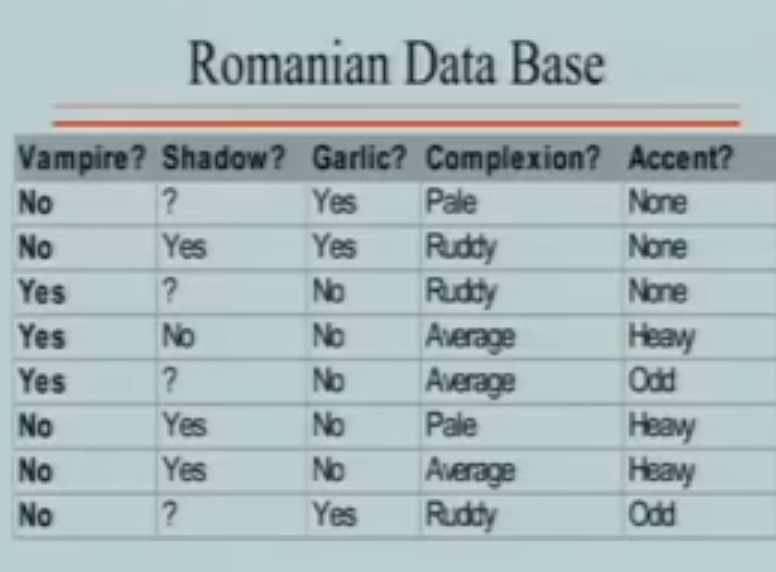
数据特点:
-
这不是数值数据,是符号数据(没有0.7个影子)
-
有些数据无关紧要
-
有些特征只在某些时刻有用
-
测试代价cost
识别树
一次测试,有三个结果,这三个结果中可能有一个需要进行另一次测试
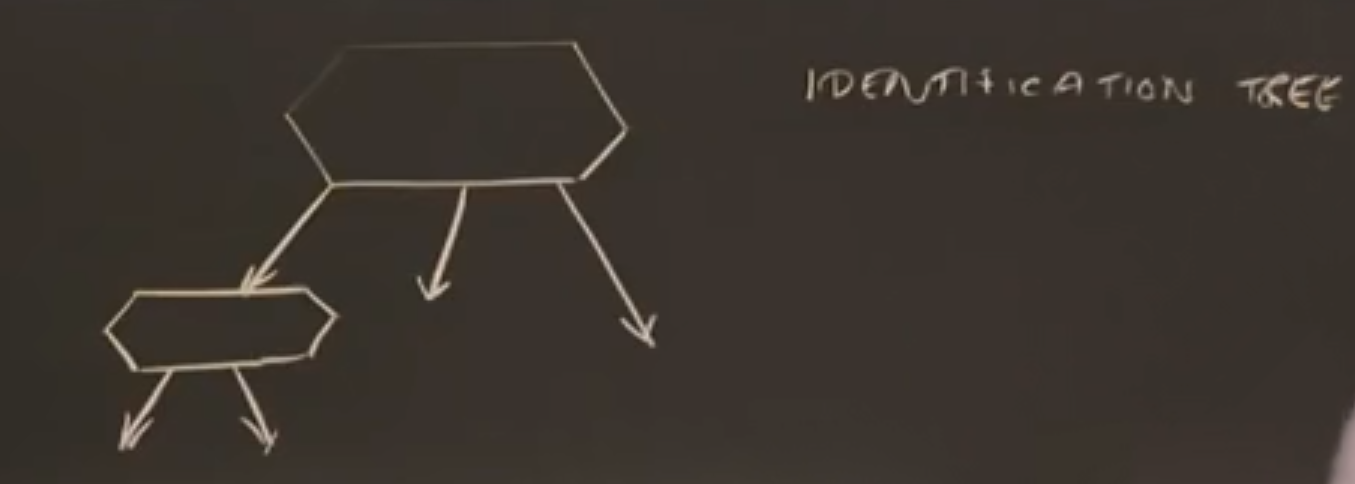
什么叫一个好的识别树?
希望它比较小(因为考虑到cost,并且simple can be useful)
如何将测试安排到测试树里,完成识别任务?
先来看样本表格中测试对应的结果
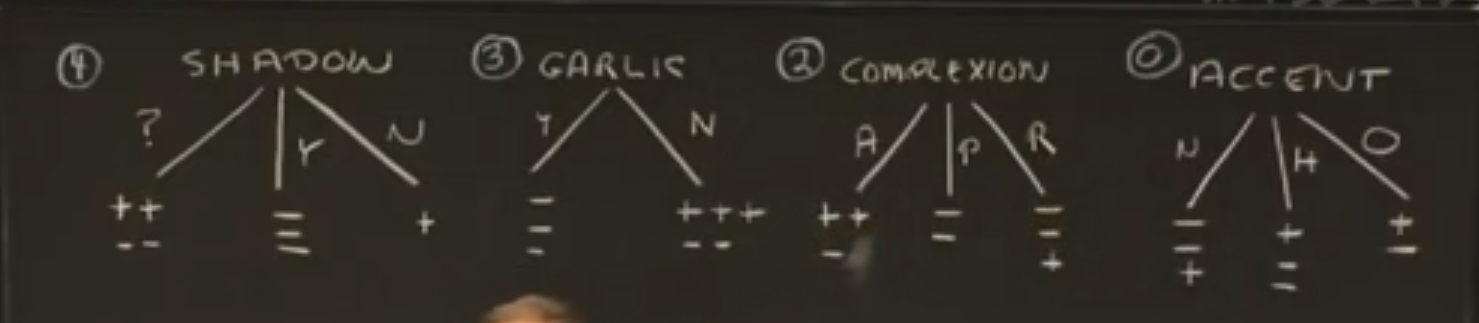
希望生成同质子集(子集中只有同一种样本),评价标准设为同质子集中样本的个数。
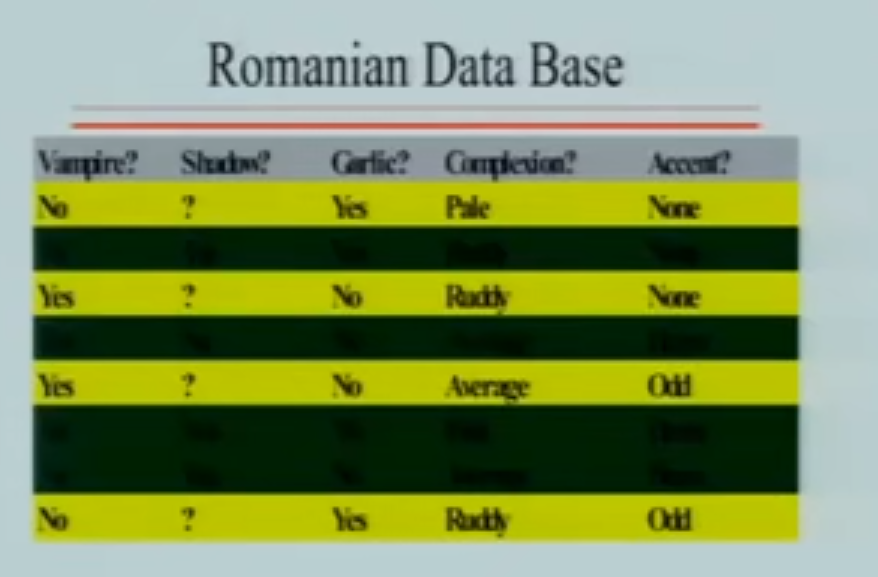
由此看来,影子测试最合适。
对于不确定影子的样本,只关注剩下的信息。
继续评估测试效果,大蒜测试最合适。
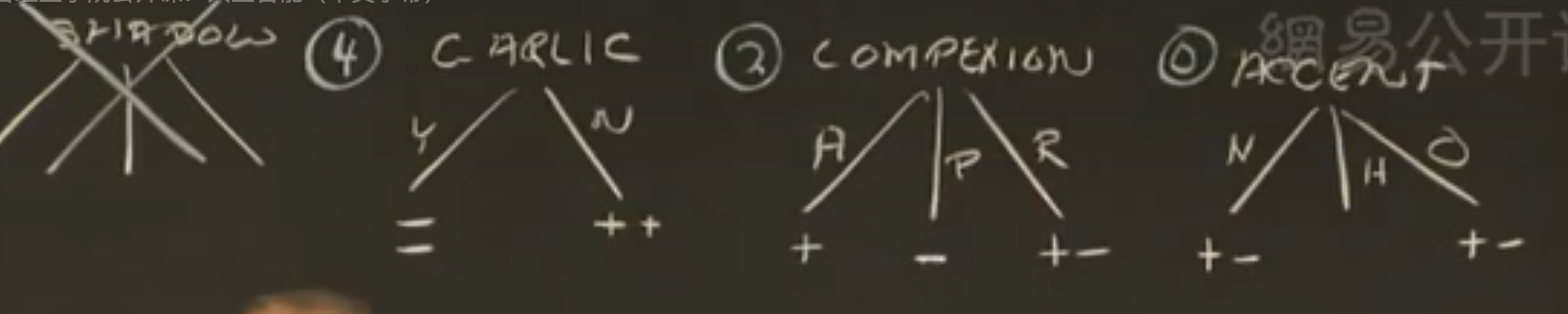
识别树就设计完了。
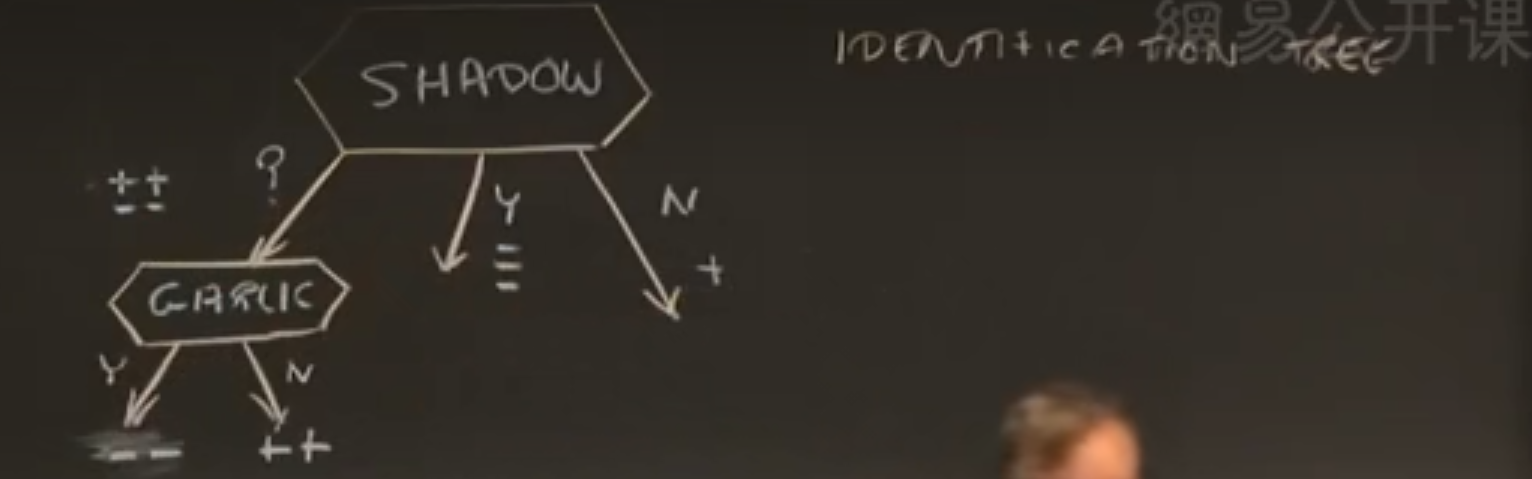
优点:
不需要使用所有测试,只需要用有用的测试,代价更小。
大数据集怎么办?
大数据集没办法一开始就得到同质子集。所以需要测试分支底端得到集合的无序程度。
例如,一堆二进制编码怎么测量无序程度?——计算熵。这是信息论中的方法。
公式:
D(ser)=−PTlog2PT−NTlog2NT D(ser)=-\frac{P}{T}\log_{2}\frac{P}{T}-\frac{N}{T}\log_2\frac{N}{T} D(ser)=−T
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3162
3162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









