




14、学习:稀疏空间、音韵学(语音识别)
小回顾
基本方法:最近邻、识别树
仿生方法:神经网络、遗传算法
如何学习音韵?
区别性特征理论
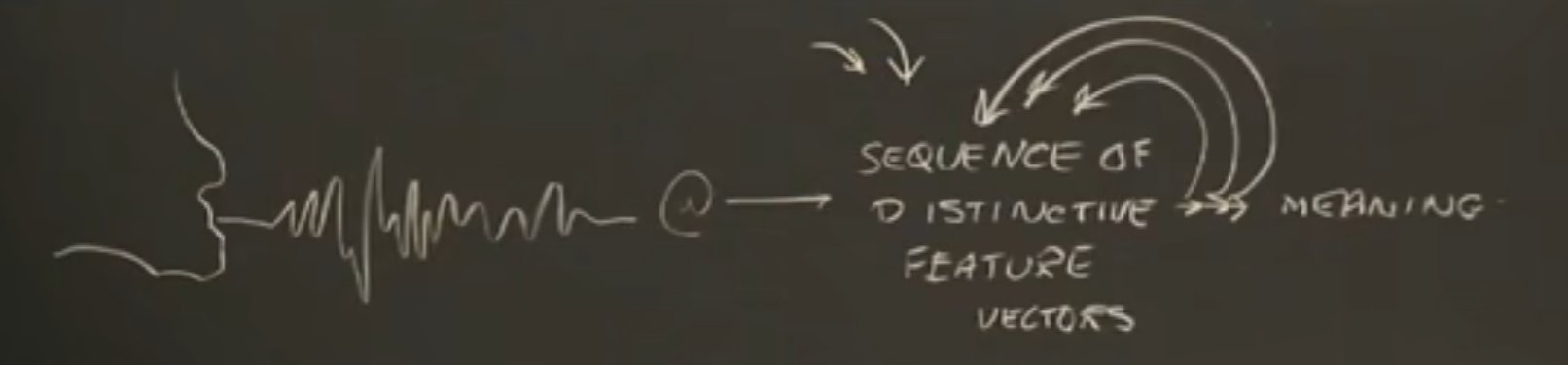
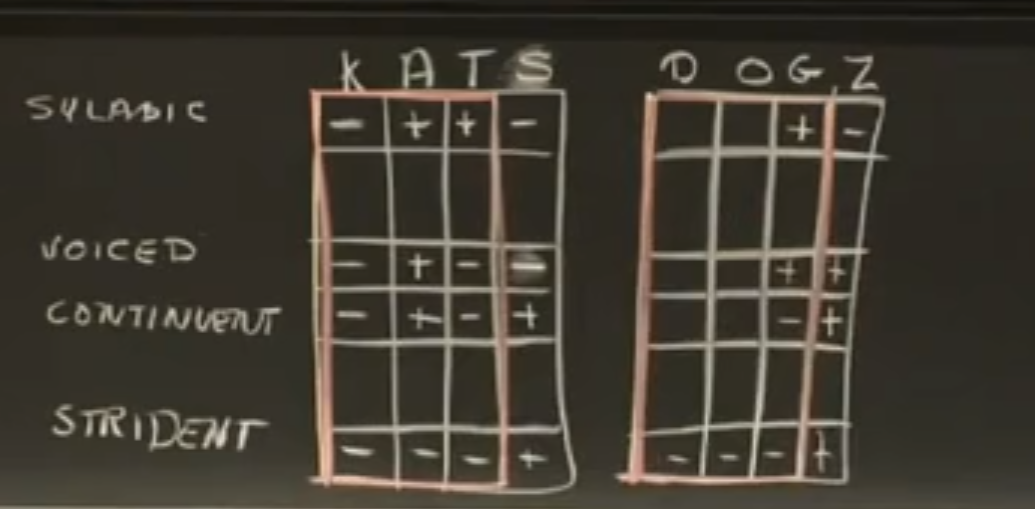
区别性特征,就是一组二进制变量,表示语言的特征。
例如:apples的发音,大概能提出14个特征。
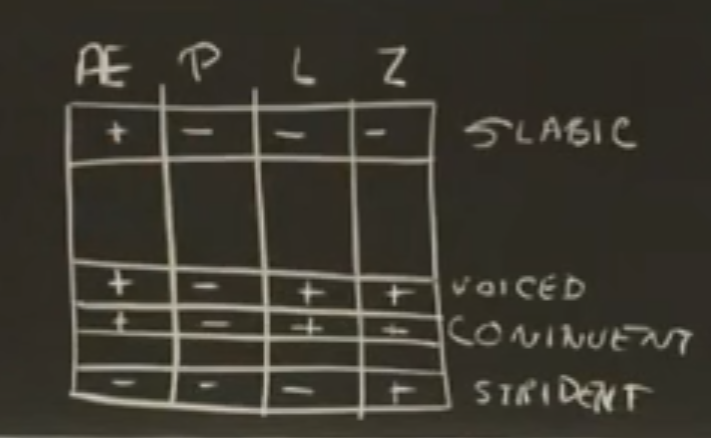
特征,例如音节性、是否发声、连续性、嘶音等。
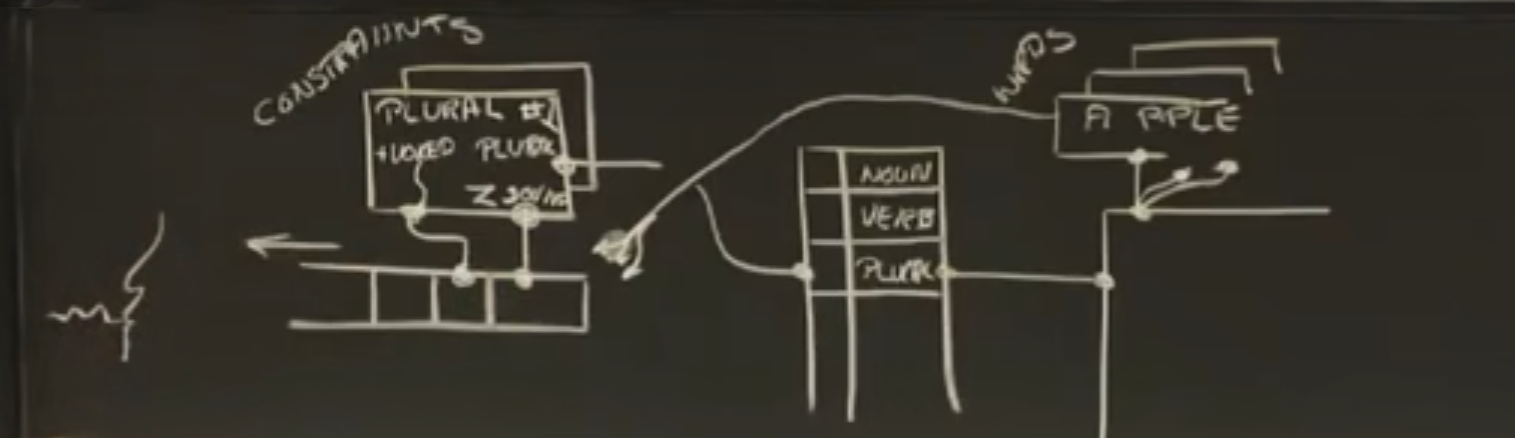
传播器
从左到右表示了约束条件、复数寄存器、单词表(意义寄存器)、外界环境。
约束条件:复数约束(plural constraint )
最左侧,z音端口与最后一个元素相连,正有声端口和倒数第二个相连等等。
相连的端口是点而不是箭头,因为信息在里面是双向流动的。
如果从窗外看到了两个苹果:
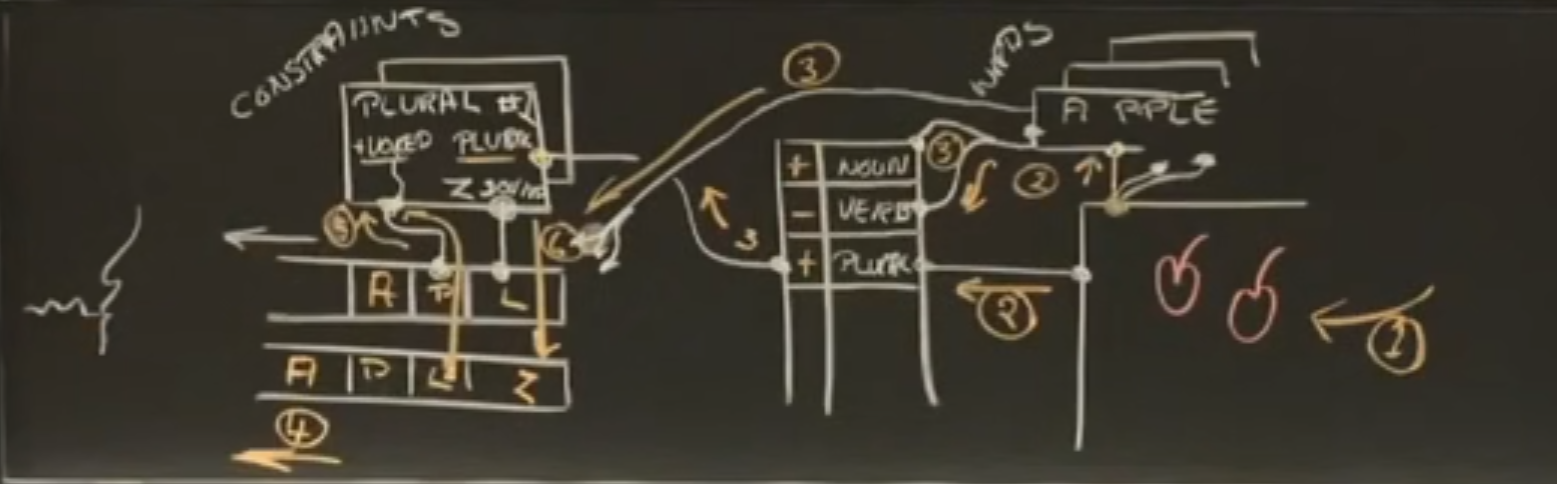
所有音韵学的规则都可以用约束条件来表示,约束条件中的信息流动可以是任何方向。
如何学习这样的规则?
(画外:麦格克效应:如果视频里的唇形和视频的声音不符,会混淆人们听到的内容。但闭上眼睛,就能很容易分辨。
所以,视觉对听觉也有很大的影响。学习语言的时候不看到口型,也会让学习变得困难。)
如何区别z音和s音?
先收集正例(称为种子)和反例
然后进行==推广==(选择矩阵中的一些音素,不再考虑它们。慢慢将一些元素换成不关心符号,直到某一时候,不关心的东西太多,以至于反例也会被负数化为s音)

那先选哪些因素开始推广呢?猜测是,距离末尾最远的字母相关性最低,所以先从第一个字母开始推广。
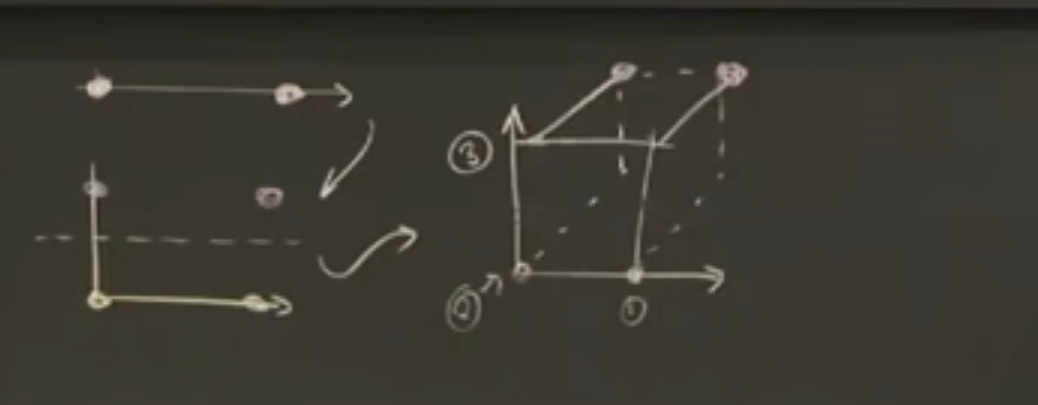
工作原理:对空间进行束搜索,以此再求解过程中降低可能性。
束搜索的两个元素把两个正例都涵盖了,实际也收敛于相同答案。
为什么它能work?
1、可学习性
这是一个稀疏空间,对于高维稀疏空间,很容易将一个超平面放在空间中,将一组例子和另一组例子区分开。
维数越高,越容易划分。
2、如果有一个14维空间,且语言中的40个点均匀分散在整个空间中(分布是随机的),那么根据中央极限定理,它们之间的距离会大致相等。这就确保了音素在说话时很容易区分。
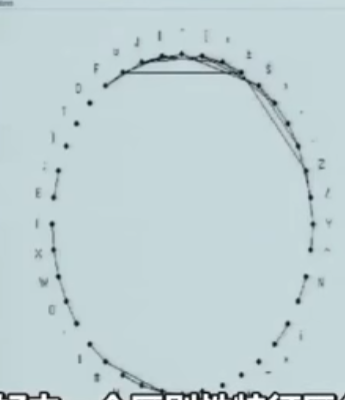
这个图表示刚好由一个区别性特征区分的所有音素。元音比辅音更难区分。
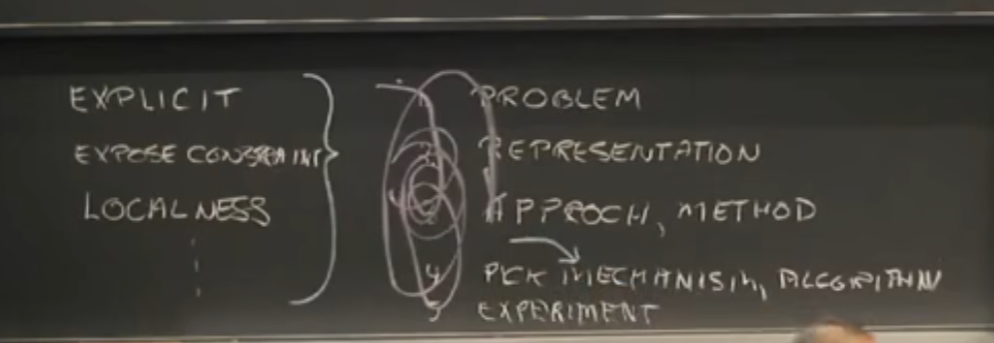
马尔问答法:处理AI问题时,需要的流程(但并不是往下线性流动的,中间会有很多回路)

但是处理AI问题的人,喜欢抓住特定机制不放,然后将这些机制生搬硬套到所有问题上。
问题和机制无法匹配,只是把机制生搬硬套到问题上,是很难取得成功的。
明确的表示(区别性特征)
如何让约束条件暴露出来
局部性标准

















 1827
1827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









