




本文系统梳理了从传统Transformer到Swin Transformer的技术演进历程,深入分析了两者的核心差异、Swin Transformer的创新机制及其在计算机视觉领域的应用优势。文章首先回顾Transformer的基本原理及其在NLP领域的成功,然后详细剖析将Transformer直接应用于视觉任务时面临的关键挑战,最后全面解读Swin Transformer如何通过分层设计、移位窗口机制等技术突破这些限制,成为视觉任务的新基准模型(扩展阅读:Transformer 是未来的技术吗?-优快云博客、初探 Transformer-优快云博客)。
Transformer的革命与跨界挑战
2017年,谷歌研究团队在里程碑论文《Attention Is All You Need》中提出的Transformer架构,彻底改变了自然语言处理(NLP)领域的格局。与传统基于循环神经网络(RNN)的序列模型不同,Transformer完全依赖自注意力机制(Self-Attention Mechanism)来建模序列中元素之间的全局依赖关系,摒弃了递归结构带来的顺序计算限制。这一创新不仅大幅提升了模型性能,还使得并行计算成为可能,显著加速了训练过程(扩展阅读:Transformer 中的注意力机制很优秀吗?-优快云博客、初探注意力机制-优快云博客、来聊聊Q、K、V的计算-优快云博客)。
Transformer在NLP领域的成功引发了研究者对其跨领域应用的广泛探索,特别是在计算机视觉(CV)领域。然而,直接将Transformer应用于视觉任务面临诸多根本性挑战:
-
尺度变化问题:自然图像中的视觉实体(如物体)通常以不同尺度出现,而原始Transformer的token长度固定,难以适应这种多尺度特性。
-
分辨率与计算复杂度:图像像素数量远超过文本中的单词数量(例如224×224图像包含50,176个像素,而典型句子仅包含几十个单词),而标准自注意力的计算复杂度与输入大小的平方成正比,导致高分辨率图像处理时计算开销巨大。
-
局部性缺失:卷积神经网络(CNN)天然具备的平移等变性和局部感受野特性使其特别适合视觉任务,而原始Transformer的全局注意力机制缺乏对这些视觉先验的有效利用。
为了解决这些挑战,微软亚洲研究院在2021年提出了Swin Transformer,通过引入分层结构和移位窗口机制,成功将Transformer的优势与视觉任务的特性相结合,在多个视觉基准任务上实现了state-of-the-art(SOTA)性能。Swin Transformer的创新不仅解决了Transformer在视觉领域的应用难题,还开辟了视觉Transformer研究的新方向,成为ICCV 2021最佳论文。
Transformer架构核心原理
自注意力机制
Transformer的核心是多头自注意力机制(Multi-Head Self-Attention, MSA),它允许模型直接计算序列中任意两个元素之间的关系强度,而不受它们距离的限制。给定输入序列(N为序列长度,d为特征维度),自注意力的计算过程如下:
通过线性变换生成查询(Query)、键(Key)和值(Value)矩阵:
其中,
,
为可学习参数矩阵。
计算注意力分数并通过softmax归一化:
多头注意力将上述过程并行执行次后拼接结果:
其中
公式说明:除以是为了防止点积结果过大导致softmax梯度消失,多头机制允许模型共同关注来自不同位置的不同表示子空间的信息。
编码器-解码器结构
标准Transformer由编码器和解码器堆叠而成,每个编码器层包含:
-
多头自注意力子层
-
前馈神经网络(FFN)子层
-
层归一化(LayerNorm)和残差连接
解码器层额外插入一个编码器-解码器注意力层,用于捕捉输入输出序列间的关联。
在视觉任务中,Vision Transformer(ViT)仅使用编码器部分,将图像分割为固定大小的patch(如16×16像素),每个patch线性投影为token后加上位置编码,送入Transformer编码器处理。这种设计虽然简单,但存在两个主要局限:
-
单一尺度特征:ViT仅在一个固定分辨率(通常是原图的1/16)上提取特征,缺乏CNN固有的多尺度层次结构,难以处理不同大小的物体。
-
全局注意力计算开销:对高分辨率图像(如1024×1024),ViT需要计算所有patch对之间的注意力关系,导致不可行的计算和内存需求。
从ViT到Swin Transformer的演进动因
ViT在视觉任务中的局限性
Vision Transformer(ViT)首次证明了纯Transformer架构在图像分类任务上可以超越CNN,但其设计存在几个关键问题限制了在更广泛视觉任务中的应用:
-
非层次化架构:ViT保持单一尺度的特征图(通常为原图1/16大小),而CNN通过池化或跨步卷积自然形成特征金字塔,适合目标检测等需要多尺度表示的任务。
-
计算复杂度问题:ViT的全局自注意力计算复杂度为
,其中H、W为特征图高宽。对于高分辨率输入(如检测任务中常见的800×1333像素),这会导致巨大的计算负担。
-
缺乏视觉归纳偏置:CNN的局部连接、共享权重和平移等变性的设计契合图像数据的特性,而ViT的全局注意力缺乏对这些视觉先验的有效利用,可能导致数据效率低下。
层次化视觉Transformer的早期尝试
在Swin Transformer之前,研究者已提出多种方法来解决ViT的局限性:
-
局部注意力:将注意力计算限制在局部窗口内,如LocalViT将图像划分为不重叠的块,在每个块内独立计算注意力。这虽然降低了计算复杂度,但完全阻断了跨窗口的信息流动。
-
空间下采样:在Transformer中引入类似CNN的池化操作,如PVT(Pyramid Vision Transformer)使用跨步卷积减少token数量,构建特征金字塔。
-
稀疏注意力:设计特定的稀疏注意力模式,如轴向注意力(Axial Attention)分别沿高度和宽度维度计算注意力,将复杂度从
降至
。
这些方法虽然部分缓解了ViT的问题,但往往在效率、灵活性或性能上做出妥协,未能像CNN那样提供通用的视觉特征提取方案。这促使研究者寻求更根本的架构创新,最终催生了Swin Transformer。
Swin Transformer的核心创新
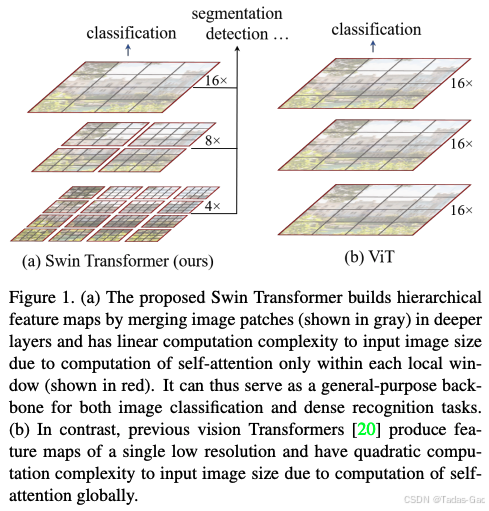
Swin Transformer通过两项关键创新解决了传统Transformer在视觉任务中的局限性:分层架构设计和移位窗口自注意力机制。这些创新使模型既能保持Transformer强大的全局建模能力,又能像CNN那样高效处理视觉数据。
分层特征表示
Swin Transformer采用类似CNN的层次化金字塔结构,通过四个阶段逐步下采样并增加通道维度,形成多尺度特征表示:
Patch Partition:输入图像(224×224×3)首先被划分为4×4的非重叠patch,每个patch展平为48维向量(4×4×3)。
Linear Embedding:通过线性层将48维patch向量投影到任意维度C(根据模型大小调整,如Swin-T为96)。
Stage 1-4:每个阶段由Patch Merging和多个Swin Transformer Block组成:
-
Patch Merging:将相邻2×2的patch合并,空间分辨率减半,特征维度加倍(类似CNN中的池化)。
-
Swin Transformer Block:交替使用窗口自注意力(W-MSA)和移位窗口自注意力(SW-MSA)。
表:Swin Transformer各阶段特征图变化
| 阶段 | 特征图尺寸 | 通道数 | Swin-T Block数 |
|---|---|---|---|
| 输入 | 224×224 | 3 | - |
| 1 | 56×56 | 96 | 2 |
| 2 | 28×28 | 192 | 2 |
| 3 | 14×14 | 384 | 6 |
| 4 | 7×7 | 768 | 2 |
这种设计使Swin Transformer能够像CNN一样构建多尺度特征表示,适合目标检测、分割等需要识别不同大小物体的任务。与ViT的单一尺度(通常为14×14)相比,Swin的分层结构提供了更丰富的空间信息。
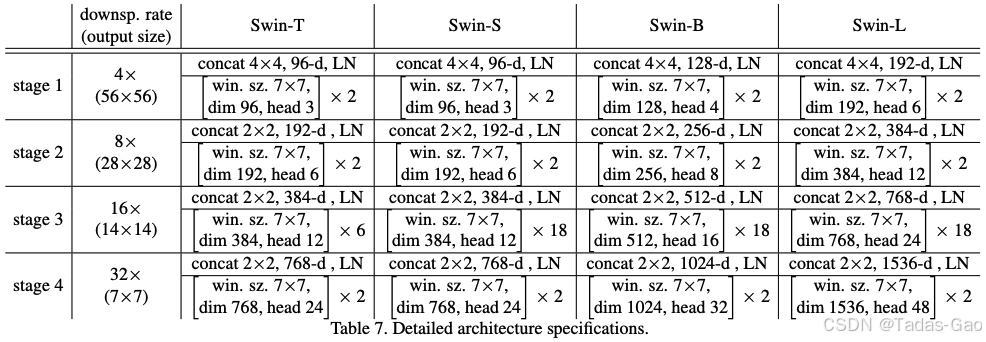
移位窗口自注意力
窗口自注意力(Window Multi-head Self-Attention, W-MSA)是Swin Transformer降低计算复杂度的关键。它将特征图划分为不重叠的局部窗口(默认M=7),仅在每个窗口内计算自注意力。对于
的feature map,计算复杂度为:
而标准MSA的复杂度为:
当M固定时(如7),W-MSA的复杂度与图像大小呈线性关系,而MSA为平方关系。这使得Swin Transformer能够高效处理高分辨率图像。
然而,纯窗口划分会完全阻断窗口间的信息流动,限制模型建模长程依赖的能力。为此,Swin Transformer引入了移位窗口(Shifted Windows)机制:在连续的两个Transformer Block中,第二层将窗口从规则划分的位置移动(⌊M/2⌋, ⌊M/2⌋)像素,称为SW-MSA。
这种设计使第l+1层的窗口跨越第l层中多个窗口的区域,实现跨窗口信息交互,同时保持计算效率。为了避免移位后窗口数量增加和大小不均的问题,Swin Transformer采用环形移位和掩码机制将计算量保持与常规窗口相同。
相对位置偏置
Swin Transformer还在自注意力计算中引入了相对位置偏置:
其中B根据query和key的相对位置从可学习参数表査询。这种设计比绝对位置编码更适合视觉任务,因为图像中的位置关系更多是平移不变的。
Swin Transformer的架构细节
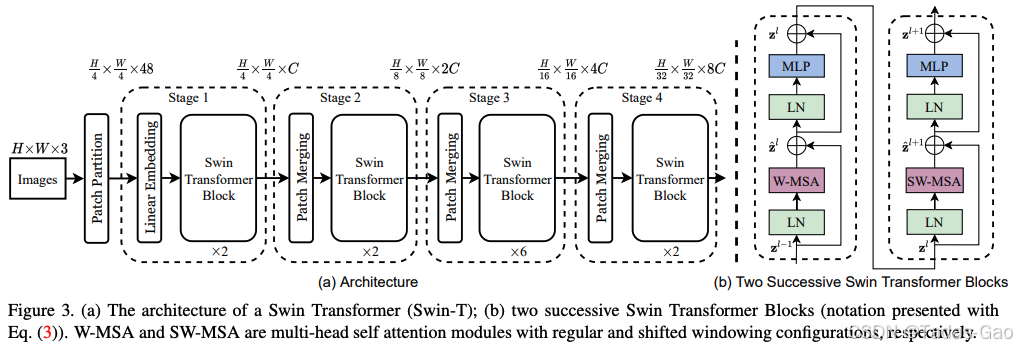
基本构建块:Swin Transformer Block
Swin Transformer Block由两个连续的子模块组成,分别使用W-MSA和SW-MSA:
-
基于窗口的多头自注意力:在局部窗口内计算自注意力,捕获细粒度特征。
-
多层感知机(MLP):两层全连接层与GELU激活,进行特征变换。
-
层归一化(LayerNorm):在每个子模块前应用。
-
残差连接:每个子模块的输出与输入相加。
Swin Transformer Block伪代码
class SwinTransformerBlock:
def __init__(self, dim, num_heads, window_size=7, shift_size=0):
self.norm1 = LayerNorm(dim)
self.attn = WindowAttention(dim, window_size, num_heads)
self.norm2 = LayerNorm(dim)
self.mlp = MLP(dim)
def forward(self, x):
# 第一个子模块:W-MSA或SW-MSA
x = x + self.attn(self.norm1(x))
# 第二个子模块:MLP
x = x + self.mlp(self.norm2(x))
return x变体配置
Swin Transformer提供不同规模的配置以适应各种计算资源需求:
表:Swin Transformer模型变体配置
| 模型 | 隐藏层维度C | 各阶段Block数 | 参数量 | ImageNet-1K Top-1 Acc |
|---|---|---|---|---|
| Swin-T | 96 | [2,2,6,2] | 29M | 81.3% |
| Swin-S | 96 | [2,2,18,2] | 50M | 83.0% |
| Swin-B | 128 | [2,2,18,2] | 88M | 83.5% |
| Swin-L | 192 | [2,2,18,2] | 197M | 87.3% |
更大的模型通过增加隐藏层维度和Block数获得更强的表征能力,在ImageNet-22K预训练后微调可达到87.3%的Top-1准确率。
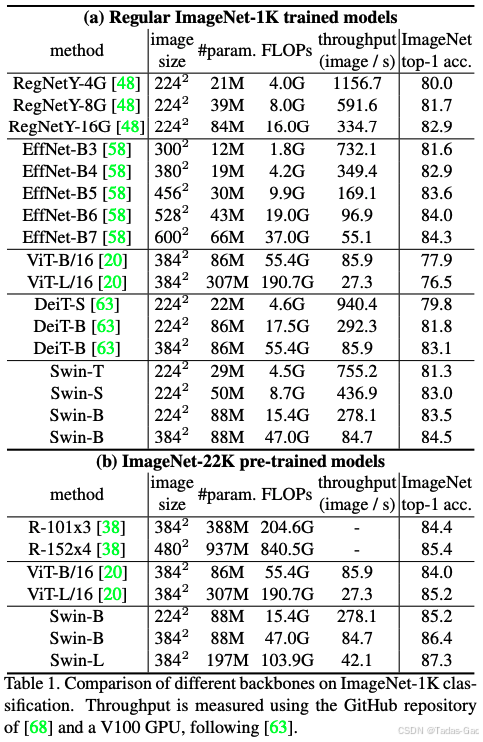
Swin Transformer的性能优势
计算效率
Swin Transformer的线性计算复杂度使其特别适合处理高分辨率图像。对比不同模型在512×512输入下的理论计算量:
表:不同模型计算复杂度比较
| 模型 | 计算复杂度 | 相对值(以Swin为1) |
|---|---|---|
| ViT | 36 | |
| PVT | 6 | |
| Swin(窗口7×7) | 1 |
这种效率优势在密集预测任务(如目标检测、语义分割)中尤为明显,因为这些任务通常需要高分辨率输入。
任务性能
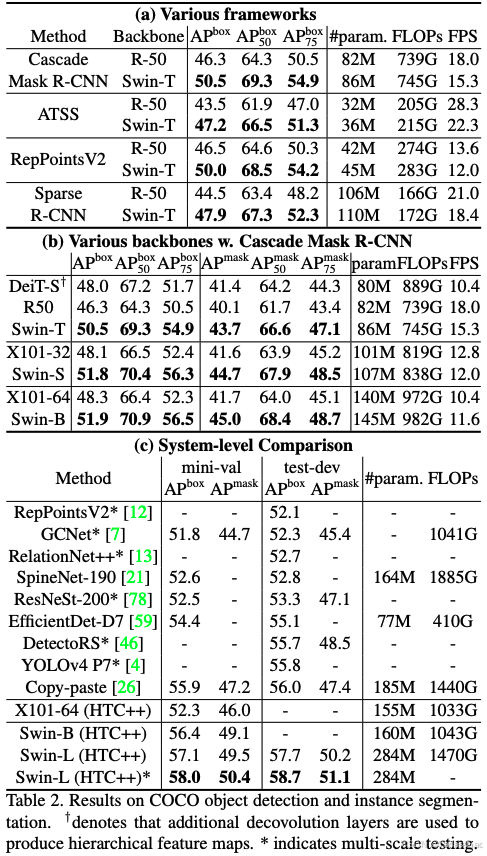
Swin Transformer在多个视觉基准任务上实现了SOTA性能:
-
图像分类:Swin-L在ImageNet-1K上达到86.4%的Top-1准确率。
-
目标检测:在COCO test-dev上,Swin-L获得58.7%的box AP和51.1%的mask AP,超越之前最佳方法+2.7% box AP和+2.6% mask AP。
-
语义分割:在ADE20K val上,Swin-L达到53.5% mIoU,比之前最佳提高+3.2%。
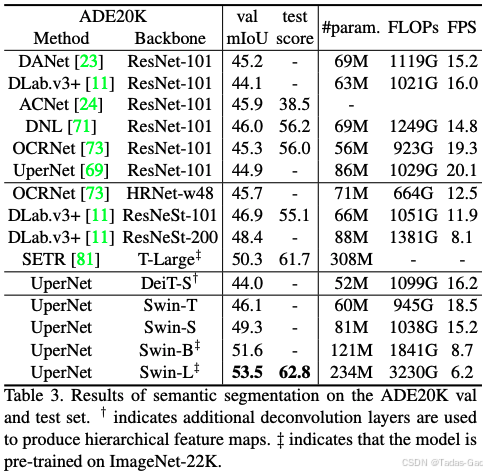
这些结果证明了Swin Transformer作为通用视觉骨干网络的强大能力。
多模态扩展
Swin Transformer的架构也成功扩展到多模态任务。例如在医学影像分析中:
-
Swin-Dual Fusion:整合CT与病理图像预测肺癌骨转移风险,AUC达0.966,显著优于传统CNN。
-
乳腺超声诊断:结合双视角超声图像与放射报告,Swin Transformer V2实现AUC 0.85,Youden指数较单模态提升6-8%。
这些应用展示了Swin Transformer处理复杂视觉任务的灵活性和强大性能。
技术影响与未来方向
对视觉架构设计的影响
Swin Transformer的成功对计算机视觉领域产生了深远影响:
-
Transformer作为通用视觉骨干:证明了经过适当设计的Transformer可以超越CNN成为更强大的视觉特征提取器。
-
层次化设计的重要性:验证了多尺度特征表示对视觉任务的关键作用,促使后续工作更加关注架构的层次性。
-
局部-全局平衡:移位窗口机制展示了如何有效平衡计算效率与建模能力,为处理高分辨率数据提供了新思路。
后续发展与替代方案
尽管Swin Transformer表现出色,研究者也在探索其他方向:
-
ViTDet:何恺明团队提出仅使用普通ViT作为骨干,通过反卷积构建特征金字塔,在目标检测任务上取得与Swin相当的性能,挑战了分层设计的必要性。
-
Swin Transformer V2:通过改进训练方法和架构细节,进一步提升了模型性能和稳定性。
-
与其他架构结合:如将Swin Transformer作为YOLOv8的骨干网络,结合检测器的高效特性。
未来研究方向
-
更高效的注意力机制:探索其他降低计算复杂度的方法,如动态稀疏注意力。
-
多模态统一架构:开发能同时处理视觉、语言等多模态数据的通用Transformer变体。
-
自监督预训练:结合MAE等自监督方法,减少对大规模标注数据的依赖。
-
边缘设备部署:优化模型以适应移动端和嵌入式设备的资源限制。
结论
Swin Transformer通过创新的分层设计和移位窗口机制,成功解决了传统Transformer在视觉任务中面临的计算复杂度高、缺乏多尺度表示等关键挑战。它将Transformer强大的全局建模能力与CNN高效的局部处理特性相结合,在多个视觉基准任务上实现了state-of-the-art性能,成为计算机视觉领域的重要里程碑。
从技术演进角度看,Swin Transformer代表了视觉架构从CNN到Transformer的自然过渡,既保留了适合视觉任务的归纳偏置,又发挥了Transformer的潜力。其成功不仅体现在学术指标上,更在实际应用中展示了强大价值,如医学影像分析、自动驾驶等关键领域。
未来,随着对视觉Transformer研究的深入,我们可能会看到更多像Swin这样巧妙结合不同架构优势的创新设计,推动计算机视觉技术迈向新的高度。Swin Transformer所开创的方向——在保持计算效率的同时增强模型表达能力——将继续指导视觉架构的创新与发展。



















 766
766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











