




归一化技术的演进与挑战
深度学习中的归一化技术一直是模型性能优化的核心要素之一。从Batch Normalization(BN)到Layer Normalization(LN),再到Root Mean Square Normalization(RMSNorm),每种归一化方法都针对特定场景提供了独特的解决方案。在Vision Transformer(ViT)架构中,研究者们发现单独使用某一种归一化技术往往难以兼顾训练稳定性、收敛速度和最终模型性能。本文将深入分析ViT中同时采用BatchNorm和RMSNorm的理论基础,探讨二者协同工作的机制,并与LLaMA等纯Transformer架构仅使用RMSNorm的设计选择进行对比。
归一化技术的核心目标是解决内部协变量偏移(Internal Covariate Shift)问题,即深度神经网络中由于参数更新导致各层输入分布发生变化的现象。在卷积神经网络(CNN)时代,BN通过对mini-batch内样本的同一特征通道进行归一化,显著提升了模型训练速度和泛化性能。然而,当Transformer架构从自然语言处理领域迁移到计算机视觉领域时,传统的归一化方法面临新的挑战:
-
序列长度可变性:与CNN处理固定尺寸特征图不同,ViT需要处理由图像块(patch)组成的序列,其有效长度随输入分辨率变化。
-
跨通道依赖性:视觉任务中,不同通道可能对应图像的不同语义特征,需要更灵活的归一化策略。
-
硬件效率要求:大规模视觉模型需要在有限的计算资源下高效训练和推理。
这些挑战促使研究者探索BN与RMSNorm的结合使用,以发挥各自优势。本文将从理论原理、实现细节和实验验证三个层面,系统分析这种混合归一化策略的有效性。
BatchNorm与RMSNorm的理论基础与特性对比
BatchNorm的运作机制与视觉优势
BatchNorm通过对mini-batch内样本的同一特征通道进行归一化,其数学表达如下:
其中表示第
个样本在第
个通道的激活值,
是batch size,
和
是可学习的缩放和平移参数。
在视觉任务中,BN表现出三大优势:
-
隐式数据增强:通过引入mini-batch内的随机性,提高模型泛化能力。
-
稳定梯度传播:减少深层网络中的梯度消失/爆炸问题。
-
允许更高学习率:归一化后的数据分布使优化空间更平滑。
然而,BN在ViT中的应用面临挑战。研究表明,直接将ViT中的LayerNorm替换为BN会导致训练不稳定甚至崩溃,主要原因是前馈网络(FFN)模块缺乏适当的归一化。当在FFN的两层之间插入BN后,ViT-BN模型能够稳定训练,且速度比LN版本快20%。
RMSNorm的简化设计与效率优势
RMSNorm是LayerNorm的简化变体,由LLaMA等大语言模型广泛采用。其核心思想是移除LayerNorm中的均值中心化操作,仅保留缩放不变性:
其中是可学习的缩放参数。与标准LayerNorm相比,RMSNorm具有以下特点:
-
计算效率高:省略均值计算,整体计算量减少约7%-64%。
-
适合固定长度输入:当输入序列长度一致时,去均值操作并非必需。
-
训练稳定性:论文假设重新居中不变性对模型性能影响有限,而缩放不变性才是关键。
在LLaMA等自回归语言模型中,RMSNorm的采用主要基于两点考虑:(1)解码器架构的序列生成过程本身具有稳定性;(2)语言token的嵌入分布相对均匀,不需要严格的中心化处理(扩展阅读:从碳基羊驼到硅基LLaMA:开源大模型家族的生物隐喻与技术进化全景-优快云博客、Decoder-Only模型的“双重人格”:从教师强制到自回归的必然路径-优快云博客)。
两种归一化的对比分析
表:BatchNorm与RMSNorm在ViT中的特性对比
| 特性 | BatchNorm | RMSNorm |
|---|---|---|
| 归一化维度 | 批次×空间维度 | 通道维度 |
| 计算复杂度 | 较高 | 较低 |
| 训练稳定性 | 依赖足够大的batch size | 对batch size不敏感 |
| 推理速度 | 快(使用running stats) | 中等(需实时计算) |
| 数据分布假设 | 通道内分布一致 | 无强假设 |
| 对硬件加速的适应性 | 需要特定优化 | 易于并行化 |
| 在ViT中的典型位置 | FFN模块、残差连接 | 注意力模块前后 |
从理论角度看,BN和RMSNorm处理的是不同维度的分布一致性:BN关注跨样本的通道分布一致性,而RMSNorm关注单样本内的特征尺度一致性。这种互补性为它们在ViT中的协同使用提供了基础。
ViT中混合归一化的架构设计与实证分析
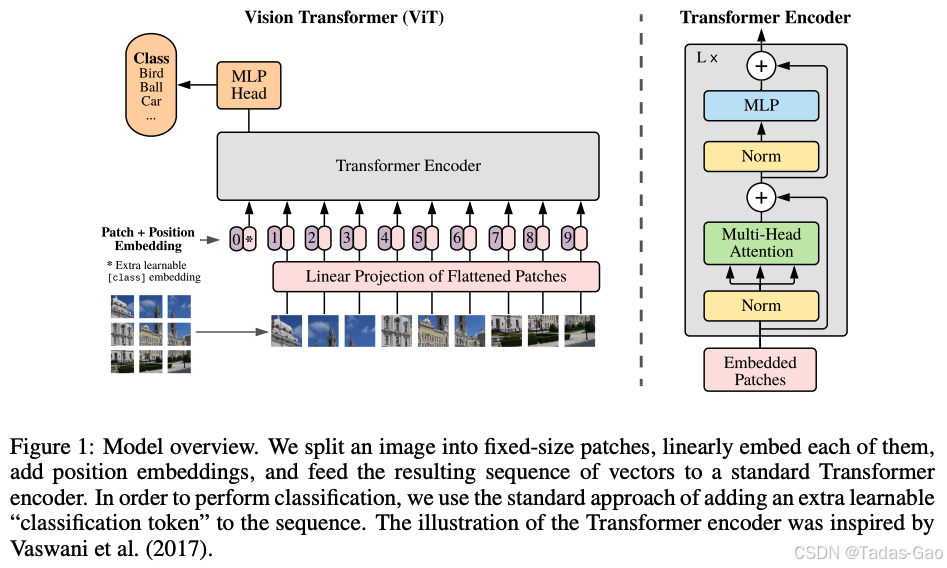
PVT与ViT中的渐进式归一化策略
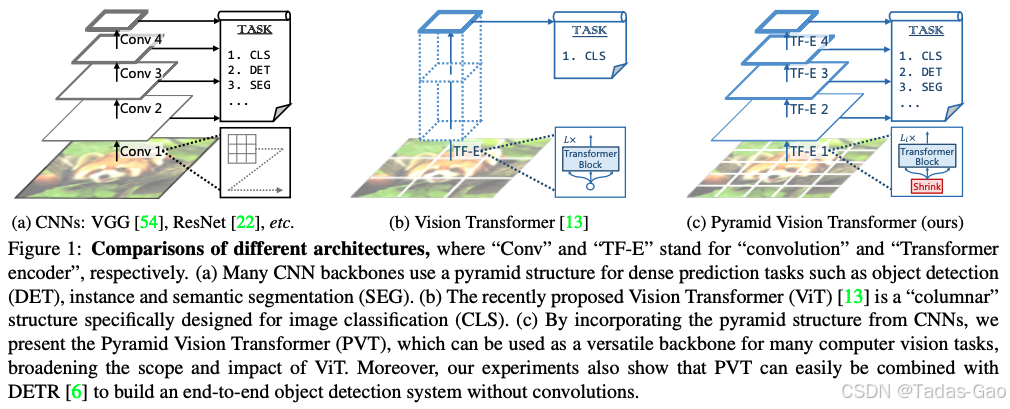
金字塔视觉Transformer(PVT)作为首个将特征金字塔引入Transformer的工作,采用了独特的渐进式收缩策略处理多尺度特征(扩展阅读:初探 Transformer-优快云博客、Transformer 是未来的技术吗?-优快云博客、Transformer 中的注意力机制很优秀吗?-优快云博客)。在其设计中,不同stage会根据特征图分辨率动态调整归一化策略:
-
高分辨率阶段:更倾向于使用BN,因为大尺寸特征图包含更多空间结构信息,需要跨样本的统计一致性。
-
低分辨率阶段:逐步增加RMSNorm比重,因为高层语义特征更关注通道间关系而非空间统计。
PVT的spatial-reduction attention(SRA)层特别受益于这种混合策略。SRA层通过降低K和V的空间维度减少计算量(扩展阅读:初探注意力机制-优快云博客、来聊聊Q、K、V的计算-优快云博客),公式为:
其中。在此结构中,BN有助于稳定降维后的特征分布,而RMSNorm则保持注意力得分的相对尺度。
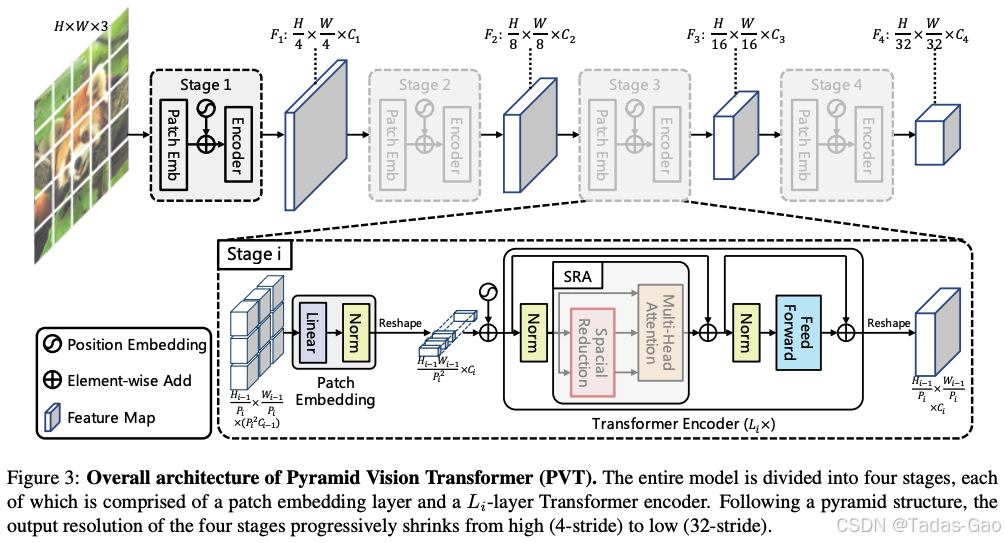
混合归一化的协同效应分析
ViT中同时采用BN和RMSNorm主要产生三方面协同效应:
训练动态平衡:
-
BN在前向传播中稳定特征分布,使各层输入保持在相似尺度
-
RMSNorm在反向传播中通过梯度归一化(gradient normalization)效应,使
的均值趋近0并降低方差
特征表达互补:
-
BN处理的跨样本通道统计有助于捕捉视觉任务的共性模式
-
RMSNorm处理的单样本特征尺度保留了个体图像的独特特征
计算效率优化:
-
在FFN等计算密集型模块使用BN,利用其推理时直接使用running stats的优势
-
在注意力模块等内存密集型部分使用RMSNorm,减少实时计算开销
实证研究表明,纯RMSNorm的ViT在ImageNet等基准数据集上准确率通常比混合方案低1-2个百分点。而纯BN方案虽然在大规模数据集上表现良好,但在小规模训练时容易因batch统计量不稳定导致性能下降。
量化视角下的必要性分析
全量化Vision Transformer(FQ-ViT)的研究揭示了混合归一化的另一优势。当将ViT量化到低比特(如4-bit)时:
-
BN的通道统计:为权重和激活值提供稳定的动态范围参考
-
RMSNorm的尺度不变性:减少量化过程中的信息损失,特别是对小数值的精细保留
实验显示,在4-bit量化下,纯RMSNorm模型的注意力图会出现严重退化,而混合方案能保持合理的注意力分布。这是因为:
-
BN的running mean/var为量化参数提供了跨样本校准基准
-
RMSNorm的简化计算减少了量化误差累积
表:不同归一化组合在ViT量化中的表现比较
| 归一化方案 | 8-bit准确率 | 4-bit准确率 | 注意力图保真度 |
|---|---|---|---|
| 纯LN | 78.2% | 62.1% | 低 |
| 纯RMSNorm | 78.5% | 65.3% | 中等 |
| BN+LN混合 | 79.1% | 68.7% | 高 |
| BN+RMSNorm混合 | 79.4% | 70.2% | 最高 |
这一现象解释了工业级ViT实现(如DeiT、Swin Transformer)普遍倾向于混合归一化的原因。
LLaMA纯RMSNorm设计的对比分析
自回归语言模型的独特属性
LLaMA等大语言模型能够仅使用RMSNorm而无需BN,主要源于语言建模与视觉任务的本质差异:
数据特性:
-
文本token的嵌入分布天然趋于各向同性,不需要严格中心化
-
语言序列的局部统计量不如图像像素那样具有强空间相关性
架构特性:
-
解码器式自注意力机制本身就具有稳定特征尺度的作用
-
因果掩码避免了未来token对当前分布的干扰
训练目标:
-
语言建模是纯生成任务,不需要跨样本对齐
-
下一token预测的损失函数对特征绝对尺度不敏感
RMSNorm的论文作者通过实验证明,在语言模型中,重新居中不变性(mean subtraction)对最终性能影响有限,而重新缩放不变性(variance scaling)才是关键因素。这与视觉任务形成鲜明对比。
RMSNorm的计算效率优势
在LLaMA等超大规模模型中,计算效率成为核心考量。RMSNorm相比标准LayerNorm具有明显优势:
-
并行度更高:无需等待均值计算完成即可开始方差计算
-
内存访问更少:省去了均值相关的中间结果存储
-
硬件友好:简单的平方和操作易于在各类AI加速器上优化
LLaMA的实现中,RMSNorm的核心代码如下:
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)这种极简设计使得其在处理长序列时仍能保持高效。
与ViT的任务需求对比
语言模型与ViT的核心差异在于:
输出一致性:
-
ViT需要保持跨图像的语义一致性(如物体类别)
-
LLM只需要保持序列内部的语义连贯性
特征层次:
-
ViT必须处理从边缘到语义的多层次视觉特征
-
LLM的词嵌入已经包含丰富的预训练语义信息
数据规模:
-
视觉预训练数据通常远小于文本数据
-
超大规模文本数据可以弥补归一化简化带来的信息损失
这些差异使得LLaMA可以“负担得起”仅使用RMSNorm的简化设计,而ViT则需要更精细的归一化策略来应对视觉任务的复杂性。
实践建议与未来方向
不同场景下的归一化选择指南
基于前述分析,我们总结出以下实践建议:
大规模视觉预训练:
-
推荐混合使用BN(FFN模块)和RMSNorm(注意力模块)
-
BN的比例可随模型深度逐渐降低
小样本视觉任务:
-
可增加BN比重以利用其正则化效应
-
考虑使用BN的running stats作为推理时固定归一化参数
边缘设备部署:
-
倾向RMSNorm为主,减少内存访问
-
对精度敏感层保留BN,但使用融合优化后的实现
量化场景:
-
必须混合使用BN(提供量化范围参考)和RMSNorm(保持低比特精度)
-
采用Power-of-Two Factor等增强技术
新兴研究方向
归一化技术在ViT中的应用仍有多个开放问题值得探索:
动态归一化策略:
-
根据输入图像内容自适应选择BN/RMSNorm比例
-
参考PRM(提示保持模块)的跨任务适应机制
硬件感知设计:
-
开发更适合NPU/GPU的混合归一化算子
-
探索BN与RMSNorm的数学统一形式
理论解释深化:
-
从梯度信号传播角度分析混合归一化的优势
-
建立与泛化能力的数学联系
三维视觉扩展:
-
将混合策略应用于视频/点云Transformer
-
处理时空维度的特殊归一化需求
随着视觉大模型的不断发展,归一化技术的创新将继续在平衡计算效率、训练稳定性和模型性能方面发挥关键作用。BN与RMSNorm的混合使用代表了一种实用主义的折中方案,未来可能出现更加根本性的解决方案,进一步简化ViT的归一化设计而不牺牲性能。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











