




FCN
论文名称:Fully Convolutional Networks for Semantic Segmentation
机构:UC Berkeley
时间:2014年提出,CVPR 2015,PAMI 2016
论文:https://arxiv.org/abs/1411.4038
代码:https://github.com/shelhamer/fcn.berkeleyvision.org
框架:
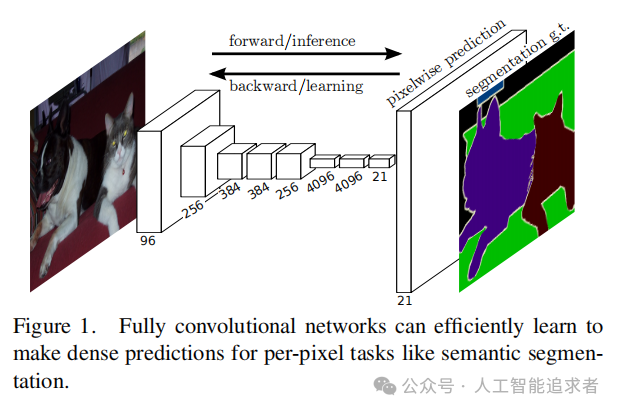
首次提出用于图像分割的端到端全卷积神经网络。框架如上,作者将分类网络(文中提到有三个:AlexNet, VGG16, GoogLeNet)中的分类层换成卷积层。
具体而言,则是直接一个1x1卷积,将特征通道变成分割类别数,再加一个反卷积升维到原始输入尺度即可计算loss.

SegNet
论文名称:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
机构:剑桥大学
时间:2015提出,PAMI 2017
论文:https://arxiv.org/pdf/1511.00561v3.pdf
代码:https://github.com/alexgkendall/caffe-segnet
框架:
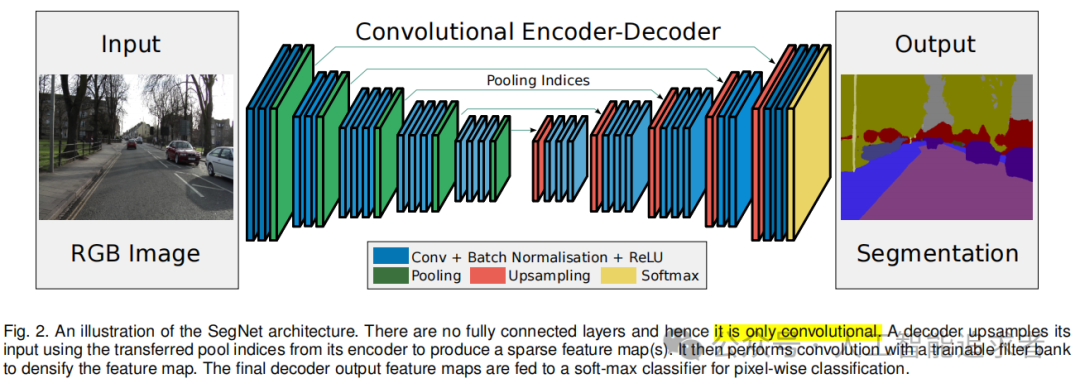
注意:上面的箭头不是跳层连接的意思,它的作用是传递UpSampling信息。整个SegNet是一个简单而高效的编码器-解码器架构。
(1)该框架主体由由一个编码器网络、一个相应的解码器网络和一个像素级的分类层组成;
(2)编码器网络的体系结构在拓扑结构上与VGG16网络[1]中的13个卷积层完全相同;
(3)解码器网络的作用是将低分辨率特征映射到输入分辨率的特征图,以进行像素级分类。SegNet的新颖之处在于,解码器对其较低分辨率的输入特征图进行向上采样的方式。
Pooling: SegNet的Pooling比一般的Pooling多了一个Pooling Index操作,每次Pooling时保存通过max选出的权值在filter中的相对位置。
Upsampling: 而Upsamping就是Pooling的逆操作。具体就是SegNet在Unpooling时用Pooling Index信息,直接将数据放回对应位置,后面再接Conv训练学习。
U-Net
论文名称:U-Net: Convolutional Networks for Biomedical Image Segmentation
机构:德国弗莱堡大学
时间:MICCAI2015
论文:https://arxiv.org/pdf/1505.04597.pdf
代码:https://github.com/milesial/Pytorch-UNet
框架:

框架如上,相对于SegNet编码-解码结构,UNet多了跳层连接;
4次下采样,再4次上采样,每次上采样后,通道拼接之前的特征;
最后是一个1x1卷积,将输出维度数变成分割类别数。
PSPNet
论文名称:Pyramid Scene Parsing Network
机构:香港中文大学,商汤科技
时间:2017CVPR
论文:https://openaccess.thecvf.com/content_cvpr_2017/papers/Zhao_Pyramid_Scene_Parsing_CVPR_2017_paper.pdf
代码:https://github.com/hszhao/PSPNet
框架:
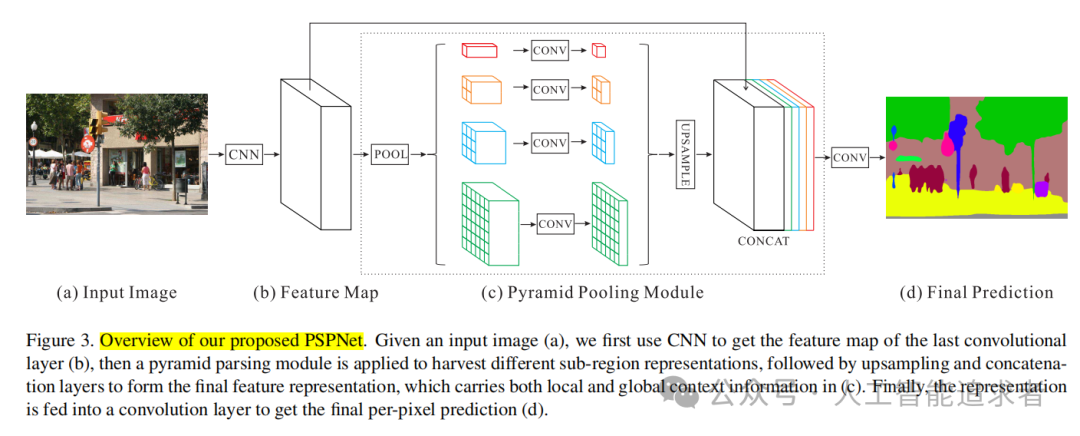
框架如上。简单一句话,利用卷积获取多尺度特征,再concat通道在一起,学习多尺度特征。
(1)首先经过卷积,获得初步的特征;
(2)对初步的特征经过Pool操作,获得多尺度特征后一顿卷积,再上采样到初步特征的尺度;
(3)将多尺度特征和初步特征concat在一起,最后接一个1x1卷积,即可计算Loss.
DeepLabV3+
论文名称:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
机构:google Inc
时间:2018ECCV
论文:https://arxiv.org/pdf/1802.02611.pdf
代码:https://github.com/jfzhang95/pytorch-deeplab-xception
框架:
简略框架如下(c)。在编码器上使用空间金字塔池化,获取多尺度特征;在编码器上使用空洞卷积进行上采样,预测分割结果。
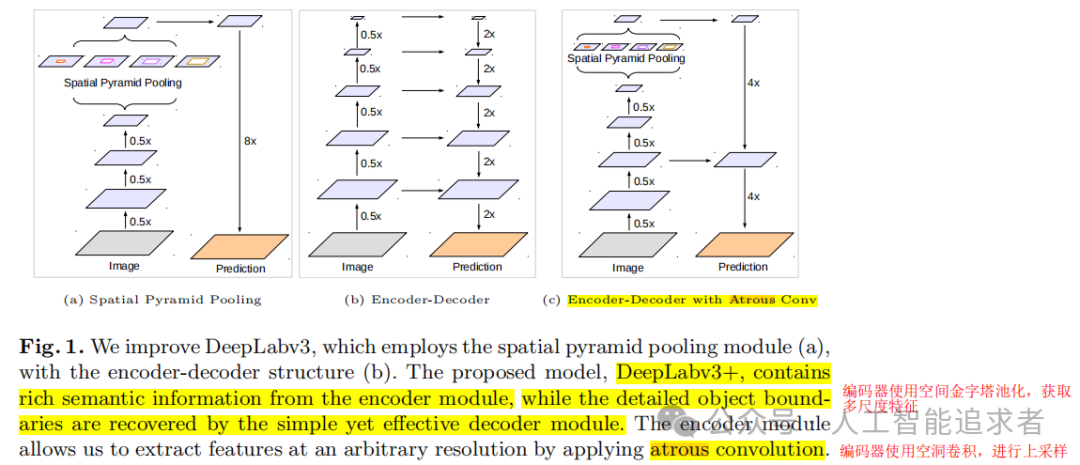
具体框架如下。
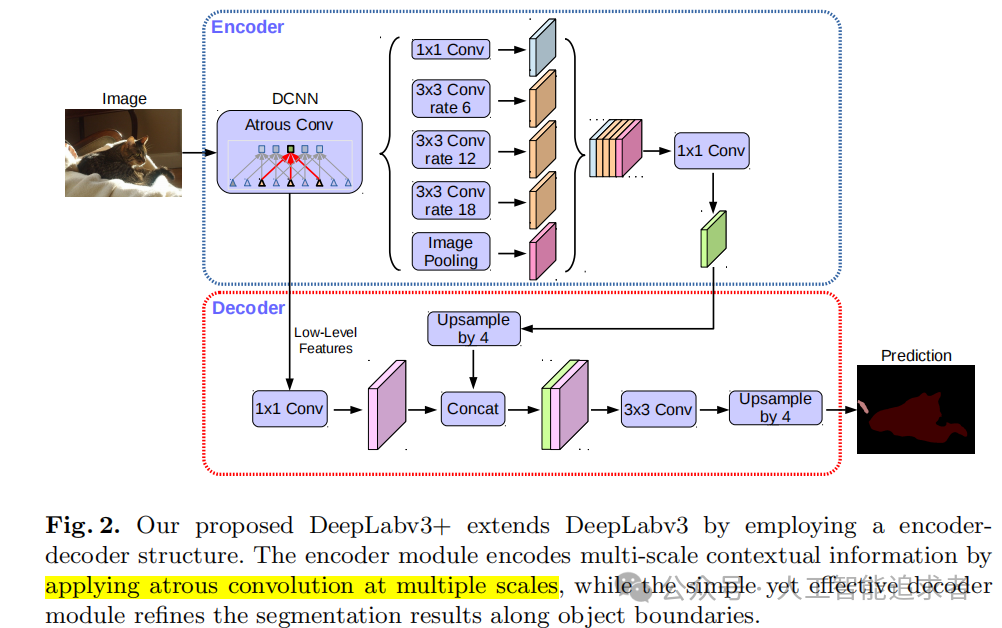
总体是编码-解码结构;
(1)encoder部分使用了ASPP(Atrous Spatial Pyramid Pooling)结构,提取多尺度特征,再沿着channel维度concat在一起,再使用1x1卷积得到编码特征;
(2)decoder部分,首先对low-level特征1x1卷积,减小channels维度,对编码的high-level特征进行上采样(F.interpolate),再把low-level特征和high-level特征concat在一起,继续卷积和上采样得的分割结果。
其他分割模型的代码可以参考如下:
-
https://github.com/labmlai/annotated_deep_learning_paper_implementations
-
https://github.com/qubvel/segmentation_models
-
https://github.com/open-mmlab/mmsegmentation
-
https://github.com/PaddlePaddle/PaddleSeg



















 37万+
37万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











