






目录
前言
最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
底层逻辑是基于b+树索引的数据结构。b+树是一种多叉树,每个节点可以包含多个键值对,用于加快查找速度。在MYSQL中,每个索引都是基于b+树实现的。
当查询条件中的所有列都包含在索引中时,MYSQL会根据最左匹配原则选择索引进行查询。最左匹配原则指的是从索引的最左边开始,逐个匹配查询条件中的列。如果某一列不满足查询条件,则停止匹配。这样可以快速定位到满足查询条件的记录。
使用最左匹配原则可以提高查询效率,因为MYSQL可以利用索引定位到满足查询条件的记录,而不需要扫描整个表。但是需要注意,如果查询条件中的列没有按照索引定义的顺序排序,MYSQL将无法使用索引,从而导致查询效率降低。
具体的查询过程是这样的:MySQL首先会查看查询条件中是否有使用到索引的列,如果有,则会选择使用包含这些列的索引进行查询。如果查询条件中只涉及到了复合索引的部分列,MySQL会从索引的最左边开始匹配,直到遇到一个不匹配的列,然后停止匹配。MySQL会利用这个索引的前缀,找到满足条件的记录。
最左匹配原则能够提高查询性能,因为MySQL只需要扫描索引的前缀,而不需要扫描整个索引。但同时,这也意味着复合索引的顺序非常重要,需要根据实际查询的情况来确定索引的顺序。
一、最左匹配原则示例
1.导入测试数据-索引(a,b,c)
CREATE TABLE `test_table` (
`a` varchar(100) DEFAULT NULL,
`b` varchar(100) DEFAULT NULL,
`c` varchar(100) DEFAULT NULL,
`d` varchar(100) DEFAULT NULL,
KEY `test_table_a_IDX` (`a`,`b`,`c`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into test_table (a,b,c,d) values ('A1','B1','C1','D1');
insert into test_table (a,b,c,d) values ('A2','B2','C2','D2');
insert into test_table (a,b,c,d) values ('A3','B3','C3','D3');
insert into test_table (a,b,c,d) values ('A4','B4','C4','D4');
insert into test_table (a,b,c,d) values ('A5','B5','C5','D5');2.全值匹配查询
EXPLAIN SELECT * FROM TEST_TABLE WHERE A='A1' AND B = 'B1' AND C ='C1';
EXPLAIN SELECT * FROM TEST_TABLE WHERE B='B1' AND A = 'A1' AND C ='C1';
EXPLAIN SELECT * FROM TEST_TABLE WHERE C='C6' AND B = 'B4' AND A ='A1';
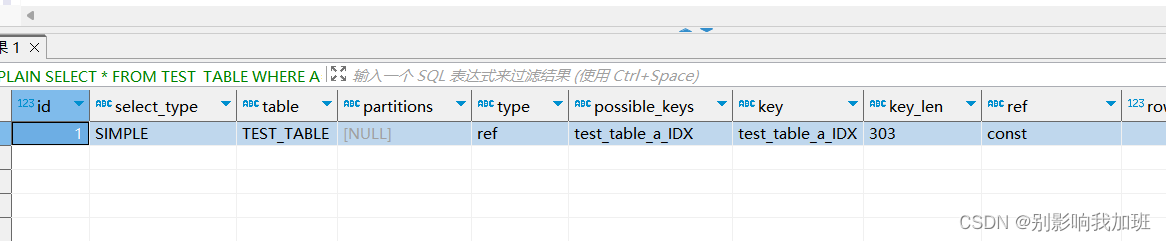
注:possible_keys:显示可能应用在这张表中的索引。key:实际使用的索引。
全值匹配查询中都用到了索引,子句几个搜索条件顺序调换不影响查询结果,因为Mysql中有查询优化器,会自动优化查询顺序。
3.连续匹配查询
- 从a开始都从最左边开始连续匹配,用到了索引
--(a),(a,b),(a,b,c)
EXPLAIN SELECT * FROM TEST_TABLE WHERE A='A1';
EXPLAIN SELECT * FROM TEST_TABLE WHERE A='A1' AND B = 'B1';
EXPLAIN SELECT * FROM TEST_TABLE WHERE A='A1' AND B = 'B1' AND C ='C1';
- 这些没有从最左边开始,最后查询没有用到索引,用的是全表扫描。
EXPLAIN SELECT * FROM TEST_TABLE WHERE B='B1'; #b
EXPLAIN SELECT * FROM TEST_TABLE WHERE C='C1'; #c
EXPLAIN SELECT * FROM TEST_TABLE WHERE B='B1' AND C = 'C1'; #bc 
4.不连续匹配查询
- 如果不连续时,只用到了a列的索引,b列和c列都没有用到
EXPLAIN SELECT * FROM TEST_TABLE WHERE B='B1' and D ='C1'; #bd

EXPLAIN SELECT * FROM TEST_TABLE WHERE A='A1' and D ='D1'; #ad
二、底层原理详解
1.MYSQL优化器
以EXPLAIN SELECT * FROM TEST_TABLE WHERE B='B1' AND A = 'A1' AND C ='C1';为例查看优化器日志。
-- 开启
set optimizer_trace="enabled=on";
-- 执行sql
EXPLAIN SELECT * FROM TEST_TABLE WHERE B='B1' AND A = 'A1' AND C ='C1';
-- 查看日志信息
select * from information_schema.OPTIMIZER_TRACE;
-- 关闭
set optimizer_trace="enabled=off";{
"steps": [
{
"join_preparation": {
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `t1`.`a` AS `a`,`t1`.`b` AS `b`,`t1`.`c` AS `c`,`t1`.`d` AS `d`,`t1`.`e` AS `e` from `t1` where ((`t1`.`a` = `t1`.`b`) and (`t1`.`b` = 1)) limit 0,1000"
}
]
}
},
{
"join_optimization": {
"select#": 1,
"steps": [
{
"condition_processing": {
"condition": "WHERE",
"original_condition": "((`t1`.`a` = `t1`.`b`) and (`t1`.`b` = 1))",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "(multiple equal(1, `t1`.`a`, `t1`.`b`))"
},
{
"transformation": "constant_propagation",
"resulting_condition": "(multiple equal(1, `t1`.`a`, `t1`.`b`))"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "multiple equal(1, `t1`.`a`, `t1`.`b`)"
}
]
}
},
{
"substitute_generated_columns": {
}
},
{
"table_dependencies": [
{
"table": "`t1`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
]
}
]
},
{
"ref_optimizer_key_uses": [
{
"table": "`t1`",
"field": "a",
"equals": "1",
"null_rejecting": false
},
{
"table": "`t1`",
"field": "b",
"equals": "1",
"null_rejecting": false
}
]
},
{
"rows_estimation": [
{
"table": "`t1`",
"rows": 1,
"cost": 1,
"table_type": "const",
"empty": false
}
]
},
{
"condition_on_constant_tables": "0",
"condition_value": false
}
],
"empty_result": {
"cause": "Impossible WHERE noticed after reading const tables"
}
}
},
{
"join_execution": {
"select#": 1,
"steps": [
]
}
}
]
}- “join_preparation”:与准备阶段;
- “join_optimization”::join优化阶段;
- “join_execution”:执行阶段。
- “condition_processing”:条件优化,对查询条件进行一些优化!
- “rows_estimation”:行估算。
2.最左匹配原理
索引的底层是一颗 B+ 树,联合索引当然还是一颗 B+ 树,只不过联合索引的键值数量不是一个,而是多个。构建一颗 B+ 树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建 B+ 树。例子:假如创建一个(a,b,c)的联合索引,那么它的索引树是这样的:
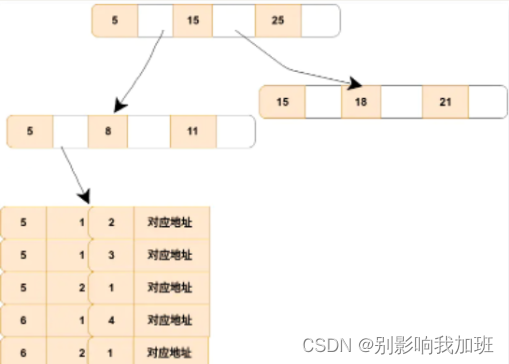
该图就是一个形如(a,b,c)联合索引的 b+ 树,其中的非叶子节点存储的是第一个关键字的索引 a,而叶子节点存储的是三个关键字的数据。这里可以看出 a 是有序的,而 b,c 都是无序的。但是当在 a 相同的时候,b 是有序的,b 相同的时候,c 又是有序的。通过对联合索引的结构的了解,那么就可以很好的了解为什么最左匹配原则中如果遇到范围查询就会停止了。以 select * from t where a=5 and b>0 and c =1; #这样a,b可以用到(a,b,c),c不可以 为例子,当查询到 b 的值以后(这是一个范围值),c 是无序的。所以就不能根据联合索引来确定到底该取哪一行。
工作原理:以上图为例,冗余索引提前加载到了内存,在内存里面定位,折半查找,查询数据只与磁盘做一次IO交互就可以,节省时间。
具体的关于BTree数据结构相关知识我是阅读了以下文章学习的:
MySQL的B-Tree索引底层结构以及具体实现原理详解-优快云博客


















 8400
8400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











