







创建地图点
在SVO中,后端的特征点是只在关键帧上提取的,用FAST加金字塔。而上一个关键帧的特征点在这一个关键帧上找匹配点的方法,是用极限搜索,寻找亮度差最小的点。最后再用depthfilter深度滤波器把这个地图点准确地过滤出来。VINS中对特征点的跟踪是使用的光流的方法,对每个特征位置的误差没有进行优化处理,优化的只是特征对应的空间点深度。
在SVO中,选取30个地图点,如果这30个地图点在当前帧和最近一个关键帧的视差的中位数大于40,或者与窗口中的关键帧的距离大于一定阈值,就认为需要一个新的关键帧。然后把当前帧设置为关键帧,对当前帧进行操作。
2.1 初始化种子
当关键帧过来的时候,对关键帧进行处理。在当前图像上,划分出
25
p
i
x
e
l
×
25
p
i
x
e
l
25pixel \times 25pixel
25pixel×25pixel的网格。
首先,当前帧上的这些已有的特征点,占据住网格。
在当前帧的5层金字塔上,每层提取fast点,首先用 3 × 3 3 \times 3 3×3范围的非极大值抑制。然后,对剩下的点,全部都计算shiTomasi分数。再全部映射到第0层的网格上,每个网格只保留分数最大的,且大于阈值的那个点。
然后,对于所有的新的特征点,初始化成种子点。用高斯分布表示逆深度,均值为最近的那个点的深度的倒数。深度范围为当前帧的最近的深度的倒数,即1.0/depth_min。高斯分布的标准差为1/6*1.0/depth_min。
2.2 更新种子,深度滤波器
如果新来一个关键帧,或者是当前的普通帧,或者之前的关键帧,用于更新种子点。对于每个种子点,通过正负1倍标准差,确定逆深度的搜索范围。这些参数都是对应种子点在它自己被初始化的那一帧。
然后把深度射线上的最短和最长的深度,映射到当前帧的单位深度平面上,其实就得到的在单位平面上的极限线段。然后,再把逆深度的均值对应的深度,映射到当前帧,就是跟1.3中的同样的方法,得到图块放射矩阵,和最佳搜索层数。
把极线线段投影到对应的层数上,如果两个端点间的像素距离小于2个像素,就直接进行优化位置。用的是1.3中的找图块匹配的方法,把对应的图块映射过来。找到最佳匹配位置后,进行三角定位。
s
c
u
r
x
c
u
r
=
s
r
e
f
R
c
→
r
e
f
x
r
e
f
+
t
c
u
r
→
r
e
f
s
r
R
c
,
r
x
r
−
s
c
x
c
=
−
t
c
,
r
[
R
c
,
r
x
r
−
x
c
]
[
s
r
s
c
]
=
−
t
c
,
r
[
s
r
s
c
]
=
−
(
[
R
c
,
r
x
r
−
x
c
]
T
[
R
c
,
r
x
r
−
x
c
]
)
−
1
[
R
c
,
r
x
r
−
x
c
]
T
t
c
,
r
s_{cur}x_{cur}=s_{ref}R_{c\to ref}x_{ref}+t_{cur \to ref} \\ s_rR_{c,r}x_r-s_cx_c=-t_{c,r} \\ \begin{bmatrix} R_{c,r}x_r & -x_c \end{bmatrix} \begin{bmatrix} s_r \\ s_c \end{bmatrix} = -t_{c,r} \\ \begin{bmatrix} s_r \\ s_c \end{bmatrix} = -(\begin{bmatrix} R_{c,r}x_r & -x_c \end{bmatrix}^T\begin{bmatrix} R_{c,r}x_r & -x_c \end{bmatrix})^{-1}\begin{bmatrix} R_{c,r}x_r & -x_c \end{bmatrix}^Tt_{c,r}
scurxcur=srefRc→refxref+tcur→refsrRc,rxr−scxc=−tc,r[Rc,rxr−xc][srsc]=−tc,r[srsc]=−([Rc,rxr−xc]T[Rc,rxr−xc])−1[Rc,rxr−xc]Ttc,r
如果两个端点间像素距离大于2个像素,就在极线上进行搜索。首先,确定总步长数,以两端点间的距离除以0.7,得到总步长数n_steps。然后,把单位深度平面上的极线线段分n_steps段,从一个端点开始往另外一个端点走,每走一步,就把位置投影到对应层数的图像上,坐标取整后,获取图块。然后,计算投影过来的图块与投影位置图块的相似度。如果分数小于阈值,就认为两个图块是相似的。在当前位置,再进行优化位置。然后进行三角定位。
接下来,计算三角定位出来的深度值的协方差。假设,在图像上的测量协方差为1个像素,则这个协方差的传递到深度上的过程如下。这个传递的,都是标准差。计算过程应用的是三角形的相关知识,参考《视觉SLAM十四讲》。
再把这个协方差传递到逆深度上。假设这时候三角定位出来的深度值为
z
z
z,则在逆深度上的标准差
δ
i
n
v
\delta_inv
δinv为
δ
i
n
v
=
1
2
(
1
z
−
σ
o
b
s
−
1
z
+
σ
o
b
s
)
\delta_inv=\frac{1}{2}(\frac{1}{z-\sigma_{obs}}-\frac{1}{z+\sigma_{obs}})
δinv=21(z−σobs1−z+σobs1)
接下来就是更新种子点的深度分布了。下面进行具体的介绍。另外,如果种子点的方差,小于深度范围/200的时候,就认为收敛了,它就不再是种子点,而是candidate点。candidate点被成功观察到1次,就变成UNKNOW点。UNKNOW被成功观察到10次,就变成GOOD点。如果多次应该观察而没有被观察到,就变成DELETE点。
以下内容参考SVO原理解析,其来源于参考文献[1]:
G.
Vogiatzis
and
C.
Hern´
andez,
“Video-based,
Real-Time
Multi
View
Stereo,”
Image
and
Vision
Computing,
vol.
29,
no.
7,
2011.
\textbf{G. Vogiatzis and C. Hern´ andez, “Video-based, Real-Time Multi View Stereo,” Image and Vision Computing, vol. 29, no. 7, 2011.}
G. Vogiatzis and C. Hern´ andez, “Video-based, Real-Time Multi View Stereo,” Image and Vision Computing, vol. 29, no. 7, 2011.
给定已知相对位姿的两个视角下的图像
I
,
I
′
I,I'
I,I′。由两幅图像中的对应点及位姿可以计算得到一个深度值
x
x
x。由于重建误差和无匹配的存在,考察实际情况中
x
x
x的直方图分布,[1]认为,
x
x
x的分布可以用高斯分布和均匀分布来联合表示
p
(
x
∣
Z
,
π
)
=
π
N
(
x
∣
Z
,
r
2
)
+
(
1
−
π
)
U
(
x
∣
Z
m
i
n
,
Z
m
a
x
)
p(x|Z,\pi)=\pi N(x|Z,r^2)+(1-\pi)U(x|Z_{min},Z_{max})
p(x∣Z,π)=πN(x∣Z,r2)+(1−π)U(x∣Zmin,Zmax)
其中,
π
\pi
π表示
x
x
x为有效测量的概率。下图是一个若干测量的直方图例子。
x
x
x轴表示深度测量范围
[
−
5
,
5
]
[-5,5]
[−5,5],
y
y
y轴表示直方图统计
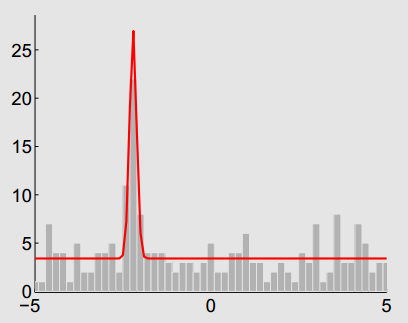
考虑同一个seed的一系列测量
x
1
,
x
2
,
…
,
x
n
x_1,x_2,\dots,x_n
x1,x2,…,xn,假设这些测量都是独立的。我们想从(1)式求出
Z
,
π
Z,\pi
Z,π。最直观的做法是通过最大似然估计求解。然而[1]认为最大似然估计容易被局部极大值干扰,其结果并不准确。[1]选择从最大后验概率求解,等价于
a
r
g
m
a
x
Z
,
π
p
(
Z
,
π
∣
x
1
,
…
,
x
N
)
argmax_{Z,\pi}p(Z,\pi|x_1,\dots,x_N)
argmaxZ,πp(Z,π∣x1,…,xN)
有
p
(
Z
,
π
∣
x
1
,
…
,
x
N
)
∝
p
(
Z
,
π
)
∏
n
p
(
x
n
∣
Z
,
π
)
p(Z,\pi|x_1,\dots,x_N) \propto p(Z,\pi)\prod_np(x_n|Z,\pi)
p(Z,π∣x1,…,xN)∝p(Z,π)n∏p(xn∣Z,π)
作者证明,上式可以用
G
a
u
s
s
i
a
n
×
B
e
t
a
Gaussian \times Beta
Gaussian×Beta分布来近似
q
(
Z
,
π
∣
a
n
,
b
n
,
μ
n
,
σ
n
)
≈
B
e
t
a
(
π
∣
a
n
,
b
n
)
⋅
N
(
Z
∣
μ
n
,
σ
n
)
q(Z,\pi|a_n,b_n,\mu_n,\sigma_n)\approx Beta(\pi|a_n,b_n) \cdot N(Z|\mu_n,\sigma_n)
q(Z,π∣an,bn,μn,σn)≈Beta(π∣an,bn)⋅N(Z∣μn,σn)
并给出一个迭代格式
(5)
q
(
Z
,
π
∣
a
n
,
b
n
,
μ
n
,
σ
n
)
≈
p
(
x
n
∣
Z
,
π
)
q
(
Z
,
π
∣
a
n
−
1
,
b
n
−
1
,
μ
n
−
1
,
σ
n
−
1
)
q(Z,\pi|a_n,b_n,\mu_n,\sigma_n) \approx p(x_n|Z,\pi)q(Z,\pi|a_{n-1},b_{n-1},\mu_{n-1},\sigma_{n-1}) \tag{5}
q(Z,π∣an,bn,μn,σn)≈p(xn∣Z,π)q(Z,π∣an−1,bn−1,μn−1,σn−1)(5)
这里约等于是因为上式子右端并不是
G
a
u
s
s
i
a
n
×
B
e
t
a
Gaussian\times Beta
Gaussian×Beta的分布,而是用
q
(
Z
,
π
∣
a
n
,
b
n
,
μ
n
,
σ
n
)
q(Z,\pi|a_n,b_n,\mu_n,\sigma_n)
q(Z,π∣an,bn,μn,σn)去近似右端项。[1]实际上利用一阶矩和二阶矩相等来更新参数。根据上式,在加入新的测量时,seed的近似后验概率分布也会得到更新。当
σ
n
\sigma_n
σn小于给定阈值时,认为seed的深度估计已经收敛,计算其三维坐标,并加入地图。
近似分布的推导
[1]作者提供了文档
Supplementary
matterial
Parametrix
approximation
to
posterior
\textbf{Supplementary matterial Parametrix approximation to posterior}
Supplementary matterial Parametrix approximation to posterior。这里首先假设
p
(
Z
,
π
)
p(Z,\pi)
p(Z,π)满足独立性公式
p
(
Z
,
π
)
=
p
(
Z
)
p
(
π
)
p(Z,\pi)=p(Z)p(\pi)
p(Z,π)=p(Z)p(π)
第一步:引入潜变量(latent variable)
y
n
y_n
yn。
y
n
=
1
y_n=1
yn=1表示
x
n
x_n
xn是内点,
y
n
=
0
y_n=0
yn=0表示
x
n
x_n
xn是外点。那么有
p
(
x
n
∣
Z
,
π
,
y
n
)
=
N
(
x
n
∣
Z
,
τ
n
2
)
y
n
U
(
x
n
)
1
−
y
n
p(x_n|Z,\pi,y_n)=N(x_n|Z,\tau_n^2)^{y_n}U(x_n)^{1-y_n}
p(xn∣Z,π,yn)=N(xn∣Z,τn2)ynU(xn)1−yn
和
p
(
y
n
∣
π
)
=
π
y
n
(
1
−
π
)
1
−
y
n
p(y_n|\pi)=\pi^{y_n}(1-\pi)^{1-y_n}
p(yn∣π)=πyn(1−π)1−yn
容易证明
p
(
x
n
∣
Z
,
π
)
=
1
p
(
Z
,
π
)
∑
y
n
p
(
x
n
,
Z
,
π
,
y
n
)
=
∑
y
n
p
(
y
n
∣
Z
,
π
)
p
(
x
n
∣
Z
,
π
,
y
n
)
=
∑
y
n
p
(
y
n
∣
π
)
p
(
x
n
∣
Z
,
π
,
y
n
)
p(x_n|Z,\pi)=\frac{1}{p(Z,\pi)}\sum_{y_n}p(x_n,Z,\pi,y_n)=\sum_{y_n}p(y_n|Z,\pi)p(x_n|Z,\pi,y_n) \\ =\sum_{y_n}p(y_n|\pi)p(x_n|Z,\pi,y_n)
p(xn∣Z,π)=p(Z,π)1yn∑p(xn,Z,π,yn)=yn∑p(yn∣Z,π)p(xn∣Z,π,yn)=yn∑p(yn∣π)p(xn∣Z,π,yn)
第二步,估计后验概率。令KaTeX parse error: Expected '}', got '\y' at position 32: …},Y={y_1,\dots,\̲y̲_n},
X
,
Y
,
Z
,
π
X,Y,Z,\pi
X,Y,Z,π的联合概率密度函数为
p
(
X
,
Y
,
Z
,
π
)
=
∏
n
p
(
x
n
∣
Z
,
π
,
y
n
)
p
(
y
n
∣
Z
,
π
)
p
(
Z
∣
π
)
p
(
π
)
=
[
∏
n
p
(
x
n
∣
Z
,
π
,
y
n
)
p
(
y
n
∣
π
)
]
p
(
Z
)
p
(
π
)
p(X,Y,Z,\pi)=\prod_np(x_n|Z,\pi,y_n)p(y_n|Z,\pi)p(Z|\pi)p(\pi) \\ =[\prod_np(x_n|Z,\pi,y_n)p(y_n|\pi)]p(Z)p(\pi)
p(X,Y,Z,π)=n∏p(xn∣Z,π,yn)p(yn∣Z,π)p(Z∣π)p(π)=[n∏p(xn∣Z,π,yn)p(yn∣π)]p(Z)p(π)
由于并不知道
p
(
Y
,
Z
,
π
∣
X
)
p(Y,Z,\pi|X)
p(Y,Z,π∣X)的具体分布。令
q
(
Y
,
Z
,
π
)
q(Y,Z,\pi)
q(Y,Z,π)是
p
(
Y
,
Z
,
π
∣
X
)
p(Y,Z,\pi|X)
p(Y,Z,π∣X)的一个近似推断,且满足
q
(
Y
,
Z
,
π
)
=
q
1
(
Y
)
q
2
(
Z
,
π
)
q(Y,Z,\pi) = q_1(Y)q_2(Z,\pi)
q(Y,Z,π)=q1(Y)q2(Z,π)
根据变分推断,求解
p
(
Y
,
Z
,
π
∣
X
)
p(Y,Z,\pi|X)
p(Y,Z,π∣X)的最佳近似分布等价于最小化
p
,
q
p,q
p,q的Kullback-Leibler散度,由此推出
q
1
,
q
2
q_1,q_2
q1,q2需要满足
ln
q
2
=
E
Y
[
ln
p
(
X
,
Y
,
Z
,
π
)
]
+
c
o
n
s
t
ln
q
1
=
E
Z
,
π
[
ln
p
(
X
,
Y
,
Z
,
π
)
]
+
c
o
n
s
t
\ln q_2=E_Y[\ln p(X,Y,Z,\pi)]+const \\ \ln q_1 = E_{Z,\pi}[\ln p(X,Y,Z,\pi)]+const
lnq2=EY[lnp(X,Y,Z,π)]+constlnq1=EZ,π[lnp(X,Y,Z,π)]+const
综上,可以进一步证明
q
2
q_2
q2满足
G
a
u
s
s
i
a
n
×
B
e
t
a
Gaussian\times Beta
Gaussian×Beta分布。
近似分布的迭代求解
由于(5)右边并不满足
G
a
u
s
s
i
a
n
×
B
e
t
a
Gaussian\times Beta
Gaussian×Beta分布,[1]尝试用另一个
G
a
u
s
s
i
a
n
×
B
e
t
a
Gaussian\times Beta
Gaussian×Beta分布来近似右端项。令(5)式两端相对于
Z
,
π
Z,\pi
Z,π的一阶矩和二阶矩相等,建立起参数方程,联立求解得到新的参数。
定义
G
a
u
s
s
i
a
n
×
B
e
t
a
Gaussian\times Beta
Gaussian×Beta分布为
q
(
Z
,
π
∣
a
,
b
,
μ
,
σ
2
)
=
N
(
Z
∣
μ
,
s
i
g
m
a
2
)
B
e
t
a
(
π
∣
a
,
b
)
q(Z,\pi|a,b,\mu,\sigma^2)=N(Z|\mu,sigma^2)Beta(\pi|a,b)
q(Z,π∣a,b,μ,σ2)=N(Z∣μ,sigma2)Beta(π∣a,b)
其中,
B
e
t
a
(
π
∣
a
,
b
)
=
Γ
(
a
+
b
)
Γ
(
a
)
Γ
(
b
)
π
a
−
1
(
1
−
π
)
b
−
1
Beta(\pi|a,b)=\frac{\Gamma(a+b)}{\Gamma(a)\Gamma(b)}\pi^{a-1}(1-\pi)^{b-1}
Beta(π∣a,b)=Γ(a)Γ(b)Γ(a+b)πa−1(1−π)b−1
根据式(5),我们想找到
q
(
′
)
=
q
(
Z
,
π
∣
a
′
,
b
′
,
μ
′
,
σ
′
2
)
q(') = q(Z,\pi|a',b',\mu',\sigma'^2)
q(′)=q(Z,π∣a′,b′,μ′,σ′2)使得其一阶矩和二阶矩与
p
(
x
∣
Z
,
π
)
q
(
Z
,
π
∣
a
,
b
,
μ
,
σ
2
)
p(x|Z,\pi)q(Z,\pi|a,b,\mu,\sigma^2)
p(x∣Z,π)q(Z,π∣a,b,μ,σ2)
相等。将
p
p
p的表达式代入上式,有
KaTeX parse error: Expected 'EOF', got '\piN' at position 2: (\̲p̲i̲N̲(x|Z,\tau^2)+(1…
注意到
Γ
(
a
,
b
)
=
1
π
a
a
+
b
Γ
(
a
+
1
,
b
)
=
1
1
−
π
b
a
+
b
Γ
(
a
,
b
+
1
)
N
(
x
∣
Z
,
τ
2
)
N
(
Z
∣
μ
,
σ
2
)
=
N
(
x
∣
μ
,
σ
2
+
τ
2
)
N
(
Z
∣
m
,
s
2
)
\Gamma(a,b) = \frac{1}{\pi}\frac{a}{a+b}\Gamma(a+1,b)=\frac{1}{1-\pi}\frac{b}{a+b}\Gamma(a,b+1) \\ N(x|Z,\tau^2)N(Z|\mu,\sigma^2)=N(x|\mu,\sigma^2+\tau^2)N(Z|m,s^2)
Γ(a,b)=π1a+baΓ(a+1,b)=1−π1a+bbΓ(a,b+1)N(x∣Z,τ2)N(Z∣μ,σ2)=N(x∣μ,σ2+τ2)N(Z∣m,s2)
其中
1
s
2
=
1
σ
2
+
1
τ
2
,
m
=
s
2
(
μ
σ
2
+
x
τ
2
)
\frac{1}{s^2}=\frac{1}{\sigma^2}+\frac{1}{\tau^2},m=s^2(\frac{\mu}{\sigma^2}+\frac{x}{\tau^2})
s21=σ21+τ21,m=s2(σ2μ+τ2x)
将上式代入(10),就可以得到[1]补充文档(18)式,即
(11)
C
1
N
(
Z
∣
m
,
s
2
)
B
e
t
a
(
π
∣
a
+
1
,
b
)
+
C
2
N
(
Z
∣
μ
,
σ
2
)
B
e
t
a
(
π
∣
a
,
b
+
1
)
C_1N(Z|m,s^2)Beta(\pi|a+1,b)+C_2N(Z|\mu,\sigma^2)Beta(\pi|a,b+1) \tag{11}
C1N(Z∣m,s2)Beta(π∣a+1,b)+C2N(Z∣μ,σ2)Beta(π∣a,b+1)(11)
其中,
C
1
=
a
a
+
b
N
(
x
∣
μ
,
σ
2
+
σ
2
)
,
C
2
=
a
a
+
b
U
(
x
)
C_1=\frac{a}{a+b}N(x|\mu,\sigma^2+\sigma^2), C_2=\frac{a}{a+b}U(x)
C1=a+baN(x∣μ,σ2+σ2),C2=a+baU(x)
分别计算
q
(
′
)
q(')
q(′)和(11)关于
Z
,
π
Z,\pi
Z,π的一阶矩和二阶矩,通过其分别相等得到
a
′
,
b
′
,
μ
′
,
σ
′
a',b',\mu',\sigma'
a′,b′,μ′,σ′四个方程。

按照上述方程利用新的信息对概率分布的参数进行更新。
更加具体的推导参见深度滤波器详细解读。
当然,我们可以对深度分布建立其他模型,只要明确每个概率模型的更新过程即可,但是客观上这些深度满足什么分布,是受到很多因素影响的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









