




 本文深入解析SpringBatch框架的结构和工作流程,涵盖应用层、核心层、基础架构层的细节,以及Job、Step、Tasklet、Chunk的配置与执行原理。探讨了监听器、LateBinding、事务配置、重启策略等高级特性。
本文深入解析SpringBatch框架的结构和工作流程,涵盖应用层、核心层、基础架构层的细节,以及Job、Step、Tasklet、Chunk的配置与执行原理。探讨了监听器、LateBinding、事务配置、重启策略等高级特性。
Spring Batch框架结构
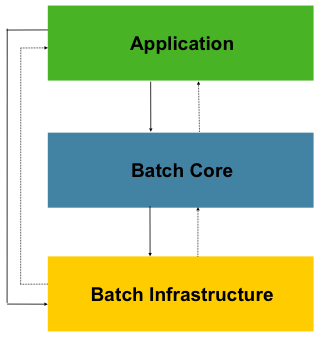
应用层包含所有的批处理作业,通过Spring框架管理成员自定义的代码。
核心层包含了Batch启动和控制所需要的核心类,如JobLauncher、Job和Step等。
基础架构层提供共通的读(ItemReader)、写(ItemWriter)和服务(如RetryTemplate:重试模块,可被核心层和应用层使用)。
Spring Batch 框架流程介绍
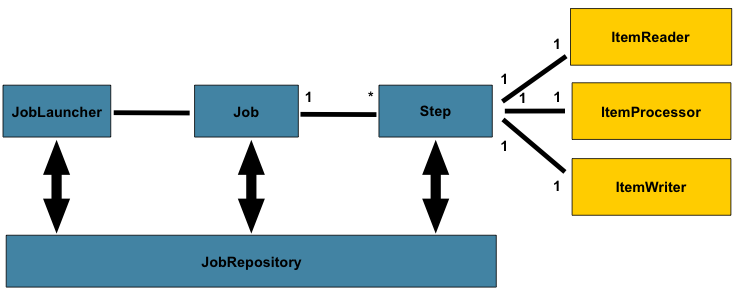
上图描绘了Spring Batch的执行过程。说明如下:
每个Batch都会包含一个Job。Job就像一个容器,这个容器里装了若干Step,Batch中实际干活的也就是这些Step,至于Step干什么活,无外乎读取数据,处理数据,然后将这些数据存储起来(ItemReader用来读取数据,ItemProcessor用来处理数据,ItemWriter用来写数据) 。可通过调用JobLauncher接口启动一个Job。
JobExecution jobExecution=JobLauncher.run(Job var1, JobParameters var2);
JobRepository是上述处理提供的一种持久化机制,它为JobLauncher,Job,和Step实例提供CRUD操作。
外部控制器调用JobLauncher启动一个Job,Job调用自己的Step去实现对数据的操作,Step处理完成后,再将处理结果一步步返回给上一层,这就是Batch处理实现的一个简单流程。
Job详解
基本配置
Job的配置有3个必须的属性,name,jobRepository,steps。一个简单的Job配置如下:
<job id="footballJob">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s2" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
</job>
jobRepository默认引用名称为jobRepository的bean,当然也可以显式地配置:
<job id="footballJob" job-repository="specialRepository">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s3" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
</job>
Restartable属性
该属性定义Job是否可以被重启,默认为true,在JobExecution执行失败后,可以创建另一个JobExecution来继续上次的执行。但是如果该属性设为false,重新执行该JobInstance将抛出异常。
<job id="footballJob" restartable="false">
...
</job>
拦截Job执行
Spring Batch在Job的生命周期中提供了一些钩子方法,可这些钩子方法通过Listener的形式提供。JobListener的接口定义如下:
public interface JobExecutionListener {
void beforeJob(JobExecution jobExecution);
void afterJob(JobExecution jobExecution);
}
通过实现JobExecutionListener接口并配置给Job,可以在Job执行前后执行特定的逻辑。例如在执行结束之后,如果失败,发送邮件通知管理人员等。
<job id="footballJob">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s2" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
<listeners>
<listener ref="sampleListener"/>
</listeners>
</job>
需要注意的是,无论Job是否成功执行,afterJob方法都会执行,Job是否执行成功,可以从JobExecution中获取。
public void afterJob(JobExecution jobExecution){
if( jobExecution.getStatus() == BatchStatus.COMPLETED ){
//job success
}
else if(jobExecution.getStatus() == BatchStatus.FAILED){
//job failure
}
}
Listener的执行顺序:
beforeJob与配置的顺序一样,afterJob与配置的顺序相反。
Listener异常:
Listener的执行过程中如果抛出异常,将导致Job无法继续完成,最终状态为FAILED.因此要合理控制Listener异常对业务的影响。
注解支持:
如果不想使用侵入性强的Listener接口,可以使用@BeforeJob和@AfterJob两个注解声明。
Job抽象与继承
通用的Job配置可以抽取出来,作为抽象的Job存在,抽象的Job不允许被实例化:
<job id="baseJob" abstract="true">
<listeners>
<listener ref="listenerOne"/>
<listeners>
</job>
子Job可以通过继续共用这些配置(当然,也可以继承非抽象的Job)。
<job id="job1" parent="baseJob">
<step id="step1" parent="standaloneStep"/>
<listeners merge="true">
<listener ref="listenerTwo"/>
<listeners>
</job>
其中的merge=”true”表示合并父job和子job的配置,也就是两个Listener都生效,同常规的Spring配置。
Job参数验证
JobParameterValidator组件用于验证JobParameter。通过以下配置为job配置验证器:
<job id="job1" parent="baseJob3">
<step id="step1" parent="standaloneStep"/>
<validator ref="paremetersValidator"/>
</job>
属性的Late Binding
在Spring中,可以把Bean配置用到的属性值通过PropertiesPlaceHolderConfiguer把属性从配置中分离出来独立管理,理论上来说,在配置Job的时候也可以使用相同的方式。但是Spring Batch提供了在运行时配置参数值的能力:
<bean:property name="filePath" value="#{jobParameters['filePath']}" />
在启动Job时:
launcher.executeJob("job.xml" , "footjob", new JobParametersBuilder().addDate("day", new Date()))
.addString("filePath", "/opt/data/test.xml"));
配置JobRepository
JobRepository为任务框架中的各个组件对象提供CRUD操作,例如JobExecution,StepExecution。 一个配置例子如下:
<job-repository id="jobRepository"
data-source="dataSource"
transaction-manager="transactionManager"
isolation-level-for-create="SERIALIZABLE"
table-prefix="BATCH_"
max-varchar-length="1000"/>
事务配置
JobRepository的操作需要事务来保证其完整性以及正确性,这些元数据的完整性对框架来说非常重要。如果没有事务支持,框架的行为将无法正确定义。 create*方法的事务隔离级别单独定义,为了保证同一个JobInstance不会被同时执行两次,默认的隔离级别为SERIALIZABLE,可以被修改:
<job-repository id="jobRepository" isolation-level-for-create="REPEATABLE_READ" />
如果没有使用Batch命名空间或者没有使用Factory Bean,则需要显示配置事务AOP:
<aop:config>
<aop:advisor
pointcut="execution(* org.springframework.batch.core..*Repository+.*(..))"/>
<advice-ref="txAdvice" />
</aop:config>
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="*" />
</tx:attributes>
</tx:advice>
表名前缀
默认情况下,Spring Batch需要的表以BATCH作为前缀,不过可以自定义:
<job-repository id="jobRepository" table-prefix="e_batch" />
表前缀可以修改,但是表名和表的列不能被修改。
特殊的Repository
测试环境中,内存级别的数据库十分方便:
<bean id="jobRepository"
class="org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean">
<property name="transactionManager" ref="transactionManager"/>
</bean>
如果使用的数据库类型不在SpringBatch的支持中,可以通过JobRepositoryFactoryBean自定义。
配置JobLauncher
默认提供了一个简单的Launcher:
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
</bean>
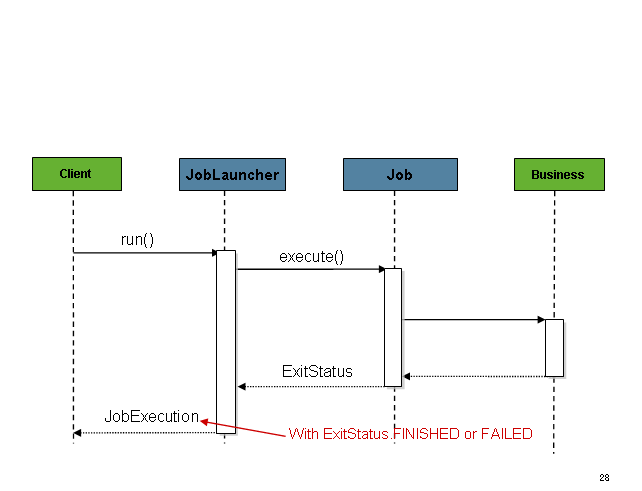
JobLauncher的时序图如下:
如果启动的请求来自HTTP,那么等待整个Job完成再返回不是一个好方法,此时需要异步启动Job,时序图如下:
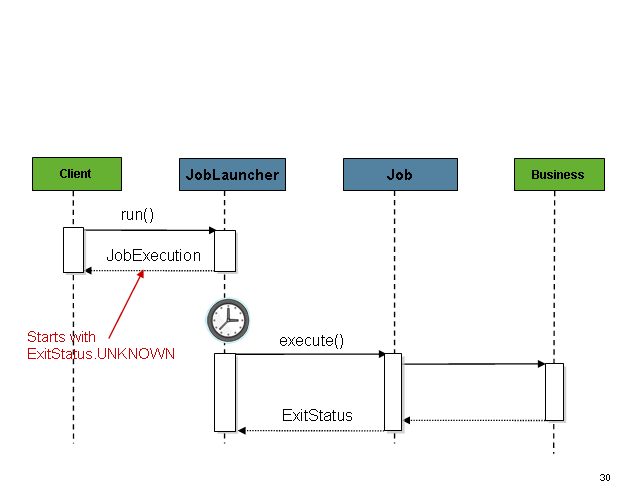
相应的Launcher配置如下:
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
<property name="taskExecutor">
<bean class="org.springframework.core.task.SimpleAsyncTaskExecutor" />
</property>
</bean>
运行Job
有多种方式可以启动一个Job,但是核心都是通过JobLauncher来实现。
-
命令行运行
主要通过CommandLineJobRunner类完成
-
从Web容器中运行
通过Http请求启动任务很常见,时序图如下: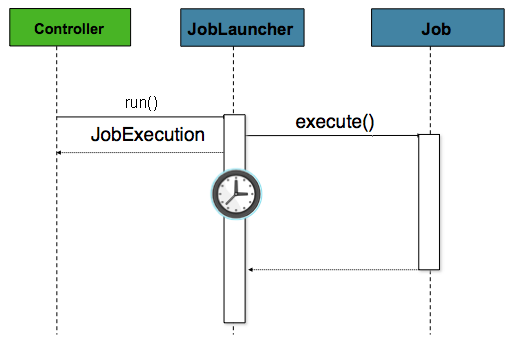
Controller可以是常规的Spring MVC Controller:
@Controller
public class JobLauncherController {
@Autowired
JobLauncher jobLauncher;
@Autowired
Job job;
@RequestMapping("/jobLauncher.html")
public void handle() throws Exception{
jobLauncher.run(job, new JobParameters());
}
}
使用调度框架运行 可以与其他调度框架一起使用,例如使用Spring的轻量级调用框架Spring Scheduler或者Quartz
元数据的高级用法
除了通过JobRepository对元数据进行CRUD操作外,Spring batch还提供另外的接口用于访问元数据。 包括: JobExplorer JobOperator。整体结构如下:
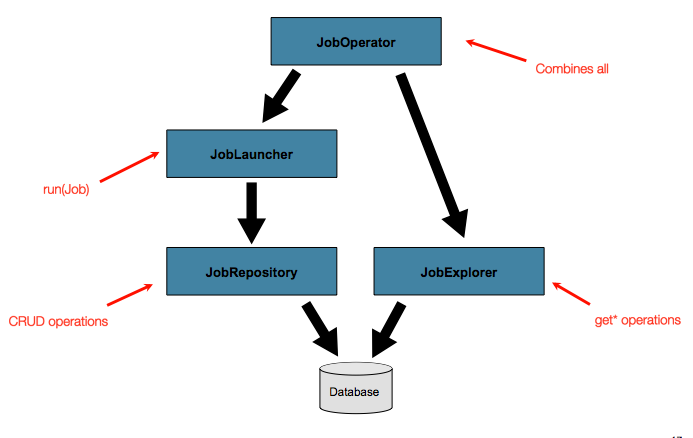
JobExplorer
该组件提供了只读的查询操作,是JobRepository的只读版本,接口定义如下
public interface JobExplorer { List<JobInstance> getJobInstances(String jobName, int start, int count); JobExecution getJobExecution(Long executionId); StepExecution getStepExecution(Long jobExecutionId, Long stepExecutionId); JobInstance getJobInstance(Long instanceId); List<JobExecution> getJobExecutions(JobInstance jobInstance); Set<JobExecution> findRunningJobExecutions(String jobName); }
配置一个Bean如下:
<bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean" p:dataSource-ref="dataSource" />
如果需要制定表名前缀:
<bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean" p:dataSource-ref="dataSource" p:tablePrefix="BATCH_" />
JobOperator
JobOperator集成了很多接口定义,提供了综合的操作方法。定义如下:
public interface JobOperator {
List<Long> getExecutions(long instanceId) throws NoSuchJobInstanceException;
List<Long> getJobInstances(String jobName, int start, int count)
throws NoSuchJobException;
Set<Long> getRunningExecutions(String jobName) throws NoSuchJobException;
String getParameters(long executionId) throws NoSuchJobExecutionException;
Long start(String jobName, String parameters)
throws NoSuchJobException, JobInstanceAlreadyExistsException;
Long restart(long executionId)
throws JobInstanceAlreadyCompleteException, NoSuchJobExecutionException,
NoSuchJobException, JobRestartException;
Long startNextInstance(String jobName)
throws NoSuchJobException, JobParametersNotFoundException, JobRestartException,
JobExecutionAlreadyRunningException, JobInstanceAlreadyCompleteException;
boolean stop(long executionId)
throws NoSuchJobExecutionException, JobExecutionNotRunningException;
String getSummary(long executionId) throws NoSuchJobExecutionException;
Map<Long, String> getStepExecutionSummaries(long executionId)
throws NoSuchJobExecutionException;
Set<String> getJobNames();
}
配置:
<bean id="jobOperator" class="org.spr...SimpleJobOperator">
<property name="jobExplorer">
<bean class="org.spr...JobExplorerFactoryBean">
<property name="dataSource" ref="dataSource" />
</bean>
</property>
<property name="jobRepository" ref="jobRepository" />
<property name="jobRegistry" ref="jobRegistry" />
<property name="jobLauncher" ref="jobLauncher" />
</bean>
其中的startNextInstance方法将使用当前Job的JobParameter,经过JobParametersIncrementer处理之后的参数启动一个JobInstance。
public interface JobParametersIncrementer {
JobParameters getNext(JobParameters parameters);
}
下面是一个简单实现:
public class SampleIncrementer implements JobParametersIncrementer {
public JobParameters getNext(JobParameters parameters) {
if (parameters==null || parameters.isEmpty()) {
return new JobParametersBuilder().addLong("run.id", 1L).toJobParameters();
}
long id = parameters.getLong("run.id",1L) + 1;
return new JobParametersBuilder().addLong("run.id", id).toJobParameters();
}
}
为job配置incrementer:
<job id="footballJob" incrementer="sampleIncrementer">
...
</job>
Step详解
面向chunk处理
一个简单的Step配置如下:
<job id="sampleJob" job-repository="jobRepository">
<step id="step1">
<tasklet transaction-manager="transactionManager">
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>
</job>
1 抽象Step与继承
可以在抽象Step中封装通用逻辑,然后在具体的Step中实现个性化的逻辑:
<step id="parentStep">
<tasklet allow-start-if-complete="true">
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>
<step id="concreteStep1" parent="parentStep">
<tasklet start-limit="5">
<chunk processor="itemProcessor" commit-interval="5"/>
</tasklet>
</step>
2 commit interval
Step在开始处理的时候启动一个事务,通过指定的Spring PlatformTransactionManager周期性地提交Item的写操作,通过interval来指定批次大小:
<job id="sampleJob">
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>
</job>
3 重启
启动次数限制
可以通过step的start-limit属性来设置Step可以执行的次数:
<step id="step1">
<tasklet start-limit="2">
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>
这个Step只能被执行2次,多次执行将抛出异常。默认情况下,step的start-limit为无穷大,即可以被无限次执行。
重启已经完成的Step
默认情况下,如果一个Step的状态为COMPLETED,那么重新执行该Step时,将被跳过,可以通过配置allow-start-if-complete属性改变这一点,使得已经完成的Step可以重新被执行:
<step id="step1">
<tasklet allow-start-if-complete="true">
<chunk reader="itemReader" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>
4 跳过
对于一些异常情况,我们可能不希望它导致整个任务结束,相反我们希望跳过这些异常的Item,后期再通过日志(通过SkipListener来记录)来特殊处理,这时候可以通过Skip逻辑来实现:
<step id="step1">
<tasklet>
<chunk reader="flatFileItemReader" writer="itemWriter"
commit-interval="10" skip-limit="10">
<skippable-exception-classes>
<include class="org.springframework.batch.item.file.FlatFileParseException"/>
</skippable-exception-classes>
</chunk>
</tasklet>
</step>
上述配置中,如果出现的异常在skippable异常列表中,则将被跳过,被跳过的Item数量上限为10,超出限制将抛出异常(导致Step失败)。如果skippable列表很长或者难以配置,可以通过include和exclude来配置:
<step id="step1">
<tasklet>
<chunk reader="flatFileItemReader" writer="itemWriter"
commit-interval="10" skip-limit="10">
<skippable-exception-classes>
<include class="java.lang.Exception"/>
<exclude class="java.io.FileNotFoundException"/>
</skippable-exception-classes>
</chunk>
</tasklet>
</step>
在决定是否跳过时,使用抛出的异常的最近的超类(nearest superclass)来决定。 include和exclude的顺序无关紧要。
5 重试
对于数据库用户名或者密码错误这一类异常,再多的重试连接都没有用。但是对于偶然的数据库死锁或者通信连接异常,通过重试很有可能解决问题。Spring Batch对Step提供了重试支持:
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter"
commit-interval="2" retry-limit="3">
<retryable-exception-classes>
<include class="org.springframework.dao.DeadlockLoserDataAccessException"/>
</retryable-exception-classes>
</chunk>
</tasklet>
</step>
各项配置与Skip类似。
6 事务属性与回滚
可以配置一些特定的异常,使得这些异常抛出的时候不回滚事务:
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="2"/>
<no-rollback-exception-classes>
<include class="org.springframework.batch.item.validator.ValidationException"/>
</no-rollback-exception-classes>
</tasklet>
</step>
事务隔离级别,传播特定等属性也可以配置:
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="2"/>
<transaction-attributes isolation="DEFAULT"
propagation="REQUIRED"
timeout="30"/>
</tasklet>
</step>
事务属性配置同常规的Spring事务。
7 在Step中注册ItemStream流
Step在执行过程中,会在适当的时机调用ItemStream的回调函数,并且从ItemStream中获取状态等信息,持久化到Repository。因此这些ItemStream必须注册到Step中,默认情况下,如果ItemReader、Processor、Writer实现了ItemStream,会被自动注册。否则,需要手动注册,这通常实在非直接依赖中使用了ItemStream,例如在Delegate中使用了ItemStream。组合模式下的组件是常见的例子:
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="compositeWriter" commit-interval="2">
<streams>
<stream ref="fileItemWriter1"/>
<stream ref="fileItemWriter2"/>
</streams>
</chunk>
</tasklet>
</step>
<beans:bean id="compositeWriter"
class="org.springframework.batch.item.support.CompositeItemWriter">
<beans:property name="delegates">
<beans:list>
<beans:ref bean="fileItemWriter1" />
<beans:ref bean="fileItemWriter2" />
</beans:list>
</beans:property>
</beans:bean>
8 拦截Step执行
Step的执行过程中,框架提供了许多钩子用于自定义,主要是以listener形式提供。包括
-
StepExecutionListener
-
ChunkListener
-
ItemReaderListener/ProcessorListener/WriterListener
-
SkipListener
-
RetryListener
这些监听器提供的方法主要时间点是:执行之前、执行之后、异常发生时
<step id="step1">
<tasklet>
<chunk reader="reader" writer="writer" commit-interval="10"/>
<listeners>
<listener ref="chunkListener"/>
</listeners>
</tasklet>
</step>
TaskletStep
批处理(chunk)是一种常见的形式,但是许多场合下不一定能满足要求。此时Tasklet可以派上用场。 Tasklet接口只定义了一个方法execute。TaskletStep将循环调用该方法,直到方法返回RepeatStatus.FINISH或者抛出异常。对Tasklet的调用被封装在一个事务中。 使用如下方法定义一个TaskletStep:
<step id="step1">
<tasklet ref="myTasklet"/>
</step>
这是,不能再使用chunk子元素。
下面是一个Tasklet实现的例子,删除某个目录下的文件:
public class FileDeletingTasklet implements Tasklet, InitializingBean {
private Resource directory;
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
File dir = directory.getFile();
Assert.state(dir.isDirectory());
File[] files = dir.listFiles();
for (int i = 0; i < files.length; i++) {
boolean deleted = files[i].delete();
if (!deleted) {
throw new UnexpectedJobExecutionException("Could not delete file " +
files[i].getPath());
}
}
return RepeatStatus.FINISHED;
}
public void setDirectoryResource(Resource directory) {
this.directory = directory;
}
public void afterPropertiesSet() throws Exception {
Assert.notNull(directory, "directory must be set");
}
}
如下使用该Tasklet:
<job id="taskletJob">
<step id="deleteFilesInDir">
<tasklet ref="fileDeletingTasklet"/>
</step>
</job>
<beans:bean id="fileDeletingTasklet"
class="org.springframework.batch.sample.tasklet.FileDeletingTasklet">
<beans:property name="directoryResource">
<beans:bean id="directory"
class="org.springframework.core.io.FileSystemResource">
<beans:constructor-arg value="target/test-outputs/test-dir" />
</beans:bean>
</beans:property>
</beans:bean>
TaskletAdapter提供了复用现有服务的能力:
<bean id="myTasklet" class="o.s.b.core.step.tasklet.MethodInvokingTaskletAdapter">
<property name="targetObject">
<bean class="org.mycompany.FooDao"/>
</property>
<property name="targetMethod" value="updateFoo" />
</bean>
控制Step执行流程
Step条件用于决定该Step完成之后,下一步如何执行。条件分值是根据Step执行结束之后返回的ExistCode来决定的。
next
<job id="job">
<step id="stepA" parent="s1">
<next on="*" to="stepB" />
<next on="FAILED" to="stepC" />
</step>
<step id="stepB" parent="s2" next="stepC" />
<step id="stepC" parent="s3" />
</job>
其中next的on属性支持通配符
-
*: 匹配0或多个字符
-
?: 匹配精确一个字符
这里的on是指step的ExitStatus。区别于JobExecution和StepExecution的属性BatchStatus,ExitStatus用于表示一个Step执行完成之后处于什么样的状态,而BatchStatus表示Job或Step的执行状态。ExitStatus默认情况下等于Step的BatchStatus.但是可以自定义:
<step id="step1" parent="s1">
<end on="FAILED" />
<next on="COMPLETED WITH SKIPS" to="errorPrint1" />
<next on="*" to="step2" />
</step>
其中ExitStatus “COMPLETED WITH SKIPS”来自以下Listener:
public class SkipCheckingListener extends StepExecutionListenerSupport {
public ExitStatus afterStep(StepExecution stepExecution) {
String exitCode = stepExecution.getExitStatus().getExitCode();
if (!exitCode.equals(ExitStatus.FAILED.getExitCode()) &&
stepExecution.getSkipCount() > 0) {
return new ExitStatus("COMPLETED WITH SKIPS");
}
else {
return null;
}
}
}
注意next元素和next属性不能同时使用。
next属性除了指向另外一个step外,还可以指向一个Decider
<job id="job">
<step id="step1" parent="s1" next="decision" />
<decision id="decision" decider="decider">
<next on="FAILED" to="step2" />
<next on="COMPLETED" to="step3" />
</decision>
<step id="step2" parent="s2" next="step3"/>
<step id="step3" parent="s3" />
</job>
<beans:bean id="decider" class="com.MyDecider"/>
MyDecider定义如下:
public class MyDecider implements JobExecutionDecider {
public FlowExecutionStatus decide(JobExecution jobExecution, StepExecution stepExecution) {
if (someCondition) {
return "FAILED";
}
else {
return "COMPLETED";
}
}
}
Decider用于对自定义条件分支。通常情况下,next根据step的返回结果决定下一步如何执行。但是如果使用Decider,那么step执行完成之后,将通过当前的执行上下文,根据Decider返回的状态,决定下一步如何执行。也就是说,默认情况下有一个默认的Decider,这个Decider简单地根据Step返回结果决定下一步,伪代码如下:
public FlowExecutionStatus decide(... , ...) {
return stepExecution.getExitStatus();
}
flow
flow用于包装一组step,可以被重用。例如:
<job id="job">
<flow id="job1.flow1" parent="flow1" next="step3"/>
<step id="step3" parent="s3"/>
</job>
<flow id="flow1">
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
上述flow定义组合了2个step,可以被多个job共用。
另外,可以通过split将多个flow并行执行:
<split id="split1" next="step4">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>
上述两个flow可以并发执行,当两个都完成,也就是split执行完成之后,按照顺序执行下一个step step4.
JobStep
JobSte将其他Job作为一个Step来执行:
<job id="jobStepJob" restartable="true">
<step id="jobStepJob.step1" next="step2">
<job ref="job" job-launcher="jobLauncher"
job-parameters-extractor="jobParametersExtractor"/>
</step>
<step id=step2> ... <step>
</job>
<job id="job" restartable="true">...</job>
<bean id="jobParametersExtractor" class="org.spr...DefaultJobParametersExtractor">
<property name="keys" value="input.file"/>
</bean>
JobStep会创建一个新的Job Execution。 job-parameters-extractor用于将当前的JobParameter转化为新启Job的JobParameter。 区别于flow,JobStep作为一个独立的step(step内启动新的job execution),而flow只是简单地执行flow中定义的step,整个flow不会作为一个单独的step运行。
在Step中结束Job
在step的执行过程中,可以根据执行结果中断整个job,Spring Batch提供了fail、end、stop三种元素用于在step中中断job。 通常情况下,job的step配置中都有一个没有下一步的step (have had at least one final Step with no transitions),该step决定Job的最终状态:
-
如果step的返回状态为FAILED,则BatchStatus和ExitStatus都为FAILED
-
否则,两者的状态均为COMPLETED
1 end
end元素将使得Jb最终BatchStatus为COMPLETED(不能被重启),如果job通过end元素结束,则ExitStatus默认为COMPLETED,当然可以自定义ExitStatus。
<step id="step1" parent="s1" next="step2">
<step id="step2" parent="s2">
<end on="FAILED"/>
<next on="*" to="step3"/>
</step>
<step id="step3" parent="s3">
2 fail
fail元素引导Job以FAILED状态结束,另外可以自定义ExitStatus。以该方式结束的Job可以被重启。
<step id="step1" parent="s1" next="step2">
<step id="step2" parent="s2">
<fail on="FAILED" exit-code="EARLY TERMINATION"/>
<next on="*" to="step3"/>
</step>
<step id="step3" parent="s3">
3 stop
stop元素使得Job以STOPPED状态结束,该状态的Job可以被重启(针对STOPPED状态采取一些动作之后),但是必须指定下一次重启的step:
<step id="step1" parent="s1">
<stop on="COMPLETED" restart="step2"/>
</step>
<step id="step2" parent="s2"/>
Late Binding与Step、Job scope
对于Job和Step的属性配置,可以使用Spring常规的占位符,将属性配置独立到properties文件中,或者在运行时通过-D参数传入。例如:
<bean id="flatFileItemReader"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="${input.file.name}" />
</bean>
然后在运行时通过-D传入参数:
-Dinput.file.name="file://file.txt"
或者通过properties文件:
input.file.name=file://file.txt
但是在Spring Batch中,更方便的方式是通过JobParameter传入。为了实现该功能,Spring Batch通过自定义scope来达到Job和Step属性的后期绑定(Late Binding)。
<bean id="flatFileItemReader" scope="step"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="#{jobParameters['input.file.name']}" />
</bean>
另外,ExecutionContext中的属性也都可以用于组件的属性配置。
<bean id="flatFileItemReader" scope="step"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="#{jobExecutionContext['input.file.name']}" />
</bean>
<bean id="flatFileItemReader" scope="step"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="#{stepExecutionContext['input.file.name']}" />
</bean>
Step Scope
注意到上述的配置中,bean都设置了scope属性,这是必须的。为了在step运行时才绑定参数,这些bean只有在Step启动时才会被实例化。由于step或者job scope不是spring默认的scope,因此需要显示配置,有2中方式可以达到该目的:
使用batch命名空间
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="...">
<batch:job .../>
...
</beans>
显式配置scope
<bean class="org.springframework.batch.core.scope.StepScope" />
两者只能选其一。
Job Scope
类似于step scope,job scope确保一个执行中的job只有一个bean实例。同时也使得可以从JobParameter或者jobExecutionContext中后期绑定参数。
<bean id="..." class="..." scope="job">
<property name="name" value="#{jobParameters[input]}" />
</bean>
<bean id="..." class="..." scope="job">
// spring EL
<property name="name" value="#{jobExecutionContext['input.name']}.txt" />
</bean>
对于上述bean,如果在多个job配置中引用该bean,那么job scope确保对于这些Job的任何JobInstance,都只有一个唯一的bean。
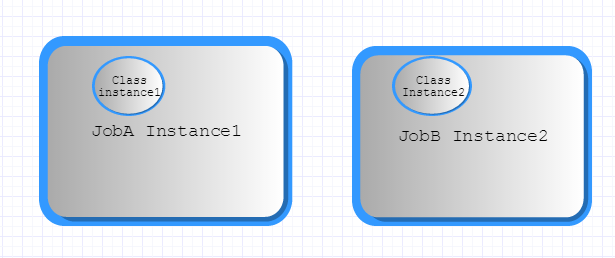
job scope一样可以通过使用batch命名空间或者显式声明:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="...">
<batch:job .../>
...
</beans>
<bean class="org.springframework.batch.core.scope.JobScope" />
Step执行过程:
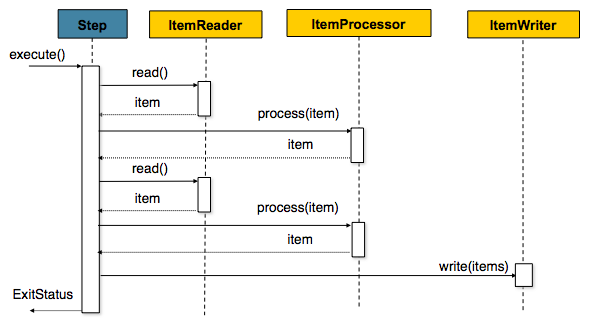
Spring Batch在其最常见的用法是面向块的处理方式。面向块的处理是指一次读取一个数据,并在事务边界内创建将被写出的chunk。 从DB或是文件中取出数据的时候,read()操作每次只读取一条记录,之后将读取的这条数据传递给processor(item)处理,框架将重复做这两步操作,直到读取记录的件数达到batch配置信息中commin-interval的设定值的时候,就会调用一次write操作。然后再重复上图的处理,直到处理完所有的数据。当这个Step的工作完成以后,或是跳到下一个Step,或者结束处理。
这就是一个SpringBatch的step基本工作流程。
Job-Step-Tasklet-Chunk
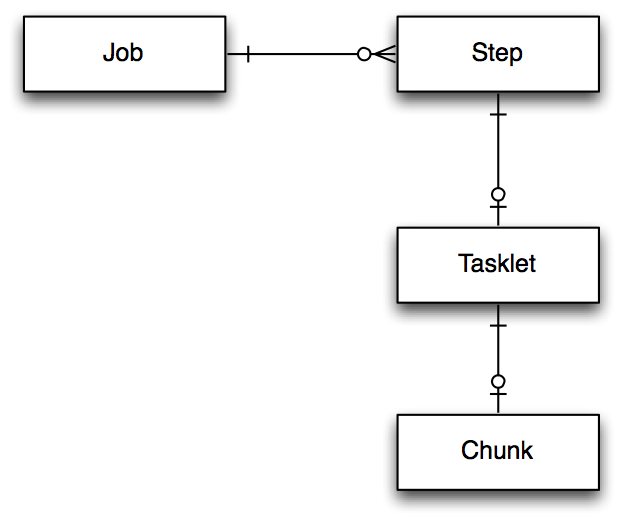
一个 job 可以包含 0到多个 step; 一个 step 可以有 0或1 个 tasklet; 一个 tasklet 可以有 0或1 个 chunk。
<job id="JobName" xmlns="http://www.springframework.org/schema/batch">
<step id="StepName1" next="StepName2">
<tasklet>
<chunk reader="someReader" processor="someProcessor" writer="someWriter" commit-interval="5" />
</tasklet>
</step>
<step id="StepName2">
<tasklet ref="someTasklet" />
</step>
<listeners>
<listener ref="someListener"/>
</listeners>
</job>
若step例的tasklet为实现TaskLet接口的实例,则这个step只会调用一次tasklet。
Spring Batch的监听器
Spring 支持如下监听器。
| 监听器 | 说明 |
| JobExecutionListener | 在 Job 开始之前(重写beforeJob方法)和之后(afterJob)触发 |
| StepExecutionListener | 在 Step 开始之前(beforeStep)和之后(afterStep)触发 |
| ChunkListener | 在 Chunk 开始之前(beforeChunk),之后(afterChunk)和错误后(afterChunkError)触发 |
| ItemReadListener | 在 Read 开始之前(beforeRead),之后(afterRead)和错误后(onReadError)触发 |
| ItemProcessListener | 在 Read 开始之前(beforeProcess),之后(afterProcess)和错误后(onProcessError)触发 |
| ItemWriteListener | 在 Read 开始之前(beforeWrite),之后(afterWrite)和错误后(onWriteError)触发 |
| SkipListener | 在 Read 开始之前(beforeWrite),之后(afterWrite)和错误后(onWriteError)触发 |
Reference
Spring Batch官方文档
https://docs.spring.io/spring-batch/2.2.x/reference/html/index.html

















 517
517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









