



从我个人意愿来说呢,更想跳过这一章节。为什么呢?因为对我自己而言,再重温机器学习的基本概念,意义并不大,毕竟算法的代码实现都在玩了,基本概念也是清楚的,又不用参加考试,那么就更没有必要将概念教条式的背下来了。
不过,考虑到学习机器学习的还是存在一批“纯白”,甚至于是转行过来的,这些概念就有似乎有必要了。记得前段时间,我有个前同事,就报了一个人工智能的学习班。她的专业以及技能偏向,应属于广告营销领域,但即便是这样的跨行幅度,也因为人工智能的热门而被拉进课堂学习,甚至包括编码部分。对于她们而言,由于之前没有接触过基本的编程知识,以及人工智能领域的一些专业基础知识,学起来就会很累。
所以呢,我想还是先来说一说基本概念吧。
这本书里给了一个定义,一个很简短的定义:机器学习就是把无序的数据转换成有用的信息。
可以说,机器学习有很多种不同的定义。吴恩达的视频里,就给出了两个定义,我们也一并来看一下:

截图来自于吴恩达机器学习视频
大家大概看下理解下就行。也就是说,机器学习是从无序的数据中,通过一定的手段方式,获取到了有用的信息,而这个过程又不是跟问题逻辑强相关的硬编码,是一种算法,这种算法具备通用性。Tom同学给出的定义就像说相声一样,不过其实是表达了机器学习训练及测试验证的整个过程,用来定义机器学习也无可厚非,但确实不算是一个很友好、一眼就能看懂的定义。
相比之下,反而是这本书的定义简单易懂,当然也会忽略掉细节。这些细节,倒是可以通过后面的学习来补全,所以也不用心急。大概理解了书中的定义,也已经达到了目的。
机器学习横跨计算机科学、工程技术和统计学等多个学科,需要多学科的专业知识。其中统计学知识很重要,我们要为各个具体的问题建立统计学模型。要想学好人工智能、机器学习,就免不了要成为一名通才,啥都要懂一些,因为这门学科确实跨度有点大。
机器学习里,又会涉及到监督学习和非监督学习。监督学习是你用来训练的样本,本身是有标记(正确答案)可以用来对比你用模型跑出来的结果的。这样的话,就能够利用这些结果来校准模型,并且对测试数据进行结果预测(预测结果可以分为值预测和分类预测)。而非监督学习,则是数据没有标记,你只是从这些数据中去识别出其结构,从而进行分群归类等。
一般来说,监督学习是主要的机器学习任务,我们运用带有标记的数据,去训练出模型,并对测试数据进行预测。监督学习的算法也更多一些,也不排除是大家的注意力都集中在这块,导致算法百花齐放吧。也有大佬们探讨过到底监督学习还是非监督学习才是人工智能的未来。从直觉上来说,非监督学习应该更像是自然界生物智能的学习方法,但就目前而言,监督学习的成果会远大于非监督学习。
其他的几个概念:
训练样本:即用来训练用的数据,含有一系列的属性值;
训练集:用于训练机器学习算法的数据集合;
目标变量:机器学习算法的预测结果,也分为标称型和数值型,一般标称型是用来分类的,数值型是用来预测数值的;
特征(属性):数据里的每一列,都是一项特征,如鸟的体重;特征分为两种值属性,一种是数值型,如体重XX公斤,另一种是标称型,就是在有限的集合里选一个,如是否有脚蹼(是,否,二值选择);
测试样本:是用来评估算法模型是否真正可用的数据,比较测试样本预测的目标,变量值与实际样本类别之间的差别,就可以得出算法的实际精确度;
机器学习的几大任务(其实前面也已经讲到了):
1)回归:预测数值型数据,形成拟合曲线,简单理解就是生成一个多项式的拟合,最终是做数值预测(如线性回归);回归一般都是监督学习;
2)分类:预测标称型数据,形成分类;但很奇怪的是逻辑回归也带“回归”两个字,实际又属于分类;分类一般也是监督学习;
3)聚类:将数据集合分成由类似的对象组成的多个类,算是统计学意义上的密度估计;比如营销上的客户画像分群,就可以考虑用类似的算法(在没有标记值的情况下对客户群体进行聚类,再去分析为什么某些客户会形成同一分群,寻找其“意义”);聚类一般是无监督学习;
如下是书中的一幅图,包括了常用的算法,可以了解一下:
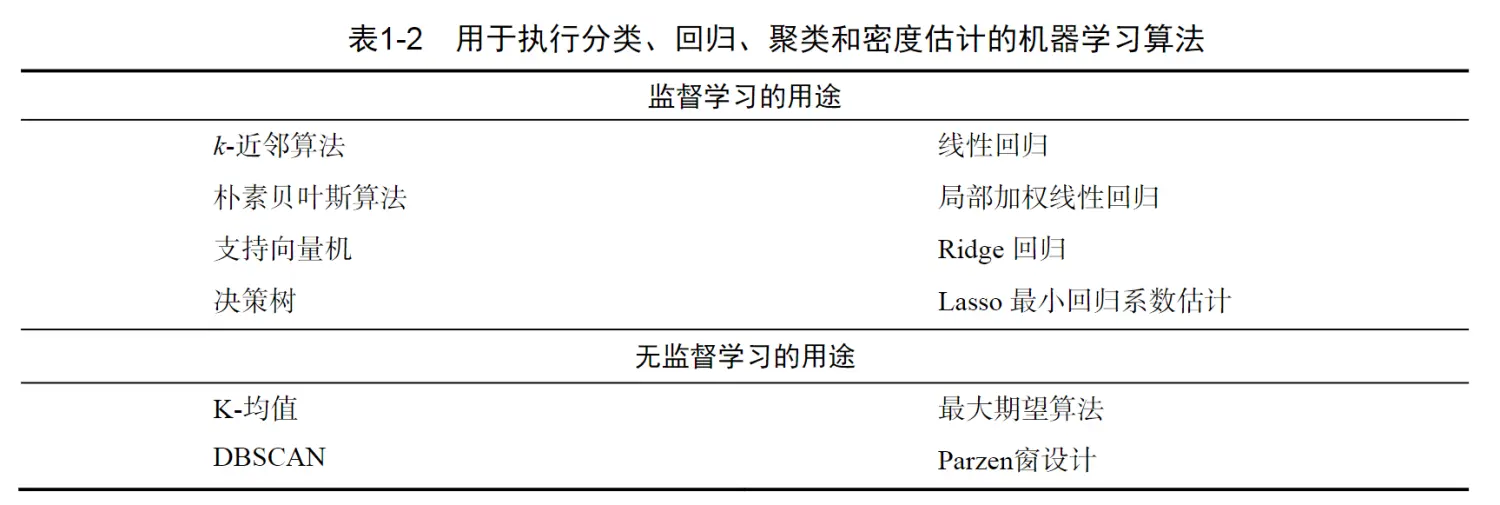
图来自于《机器学习实战》
从上面可以看到,监督学习的算法确实会多一些。无监督学习一般提到最多的就是K-均值。
好了,基本概念就讲到这里。下一章节,将讲一讲开发机器学习应用程序的常用步骤。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

















 8674
8674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









