



本文章目录
前情摘要
零基础学AI大模型之向量数据库介绍与技术选型思考
一、核心疑问:为什么不能用MySQL存储向量?
1. 维度灾难:高维向量索引失效
2. 缺乏高效相似度计算能力
3. 实时性与扩展性不足
二、向量数据库的核心能力:解决什么问题?
1. 核心能力拆解
2. 典型应用场景
三、主流向量数据库详解(含优缺点对比)
3.1 开源分布式向量数据库(企业级首选)
1. Milvus(米洛数据库)
2. Qdrant
3.2 云原生托管向量数据库(中小团队首选)
1. Pinecone
2. 腾讯云VectorDB
3.3 轻量级向量数据库工具(开发/测试首选)
1. Chroma
2. Faiss(Meta开源)
3.4 传统数据库扩展方案(渐进式改造首选)
MongoDB Atlas
其他扩展方案
四、综合选型对比表(一目了然)
五、技术选型实战建议(避免踩坑)
1. 按数据规模选型
2. 按部署复杂度选型
3. 按成本预算选型
4. 按生态兼容性选型
六、总结
零基础学AI大模型之向量数据库介绍与技术选型思考
大家好,我是工藤学编程 🦉 !在上一篇内容中,我们搞定了RAG系统中嵌入模型的性能优化,而嵌入生成的高维向量该如何高效存储和检索?这就轮到向量数据库登场了——它是RAG系统的“向量仓库”,直接决定检索的速度和精度,也是面试中“RAG技术栈选型”的高频考点。今天就来彻底搞懂:为什么不能用MySQL存向量?主流向量数据库该怎么选?

一、核心疑问:为什么不能用MySQL存储向量?
在RAG系统中,文档块通过嵌入模型处理后会生成768维、1536维甚至更高维度的向量,下一步需要快速根据用户查询向量,找到最相似的文档向量。很多开发者会想:“我已有MySQL,直接存进去不行吗?”答案是:小规模测试可以,生产环境必踩坑。
先看两个直观对比:
-- 传统MySQL查询(精确匹配):只能根据固定字段筛选
SELECT * FROM document WHERE category = 'AI技术' AND status = 'valid';
-- 向量数据库查询(相似度匹配):根据语义相关性排序
Find top 5 documents WHERE vector_similarity(embedding, 【用户查询向量】) > 0.8
ORDER BY similarity_score DESC;
传统数据库(MySQL/PostgreSQL)存储向量的核心局限性的在于三点:
1. 维度灾难:高维向量索引失效
MySQL的B-Tree、Hash索引是为低维结构化数据设计的,当向量维度超过100时,索引效率会断崖式下降——对于768维的OpenAI Embeddings向量,B-Tree索引几乎等同于全表扫描,时间复杂度O(N),百万级向量查询就需要秒级响应,完全无法满足实时场景。
2. 缺乏高效相似度计算能力
向量检索的核心是计算“余弦相似度”(语义相关性)、“欧氏距离”(空间距离)等复杂运算,而MySQL没有原生支持这些算法,需要手动实现UDF函数(用户自定义函数),不仅开发复杂,还会导致查询性能暴跌,亿级向量场景下根本无法使用。
3. 实时性与扩展性不足
当向量数据达到亿级规模时,MySQL的分库分表方案难以支撑高并发检索(比如每秒数千次查询),且数据更新后索引重建成本高,无法满足RAG系统中“实时新增文档、实时检索”的需求。
简单说:MySQL是“精准筛选专家”,而向量数据库是“语义匹配高手”,二者适用场景完全不同。
二、向量数据库的核心能力:解决什么问题?

向量数据库是专为高维向量设计的存储系统,核心能力围绕“高效相似性检索”展开,具体包括:
1. 核心能力拆解
相似性搜索:原生支持余弦相似度、欧氏距离、曼哈顿距离等算法,无需手动实现,检索精度和速度远超传统数据库;
混合查询:支持“向量相似度 + 结构化条件”混合筛选(比如“检索AI技术类文档中,与‘大模型幻觉’语义相似的前10条,且创建时间在30天内”);
动态扩展:分布式架构支持水平扩容,可应对从百万级到千亿级的向量规模增长,且支持实时数据插入/更新;
高效存储:内置向量压缩技术(如量化、降维),能将高维向量压缩为低精度格式存储,降低存储成本(比如将1536维浮点向量压缩为8位整数,存储量减少75%)。
2. 典型应用场景
向量数据库不止用于RAG,更是所有AI驱动的相似性匹配场景的核心:
应用场景 实际案例 核心需求
推荐系统 电商商品推荐、短视频推荐 高并发(每秒万级查询)、低延迟(≤100ms)
语义搜索 法律条文检索、文档知识库 高精度召回(相关文档不遗漏)、支持长文本
AI代理记忆 GPT长期记忆存储、智能助手 快速上下文检索(支撑多轮对话)
图像检索 以图搜图、商品图像匹配 多模态支持(图像向量、文本向量混用)
金融风控 欺诈交易识别、用户行为匹配 高可用(99.99%稳定性)、毫秒级响应
三、主流向量数据库详解(含优缺点对比)
目前市面上的向量数据库主要分为:开源分布式、云原生托管、轻量级工具、传统数据库扩展四大类,各自适配不同场景,下面逐一拆解:
3.1 开源分布式向量数据库(企业级首选)
1. Milvus(米洛数据库)
核心优势:专为千亿级向量设计,分布式架构支持水平扩展,QPS可突破百万级,提供HNSW、IVF-PQ等多种索引算法,适配金融风控、生物医药分子库等高性能场景;
优点:多租户支持(隔离不同业务数据)、完整API生态(Python/Java/Go/RESTful)、兼容LangChain/LLaMA Index等大模型框架;
缺点:部署复杂度高(需配置集群、监控、备份),运维成本大,适合有专业DevOps团队的企业;
适用场景:企业私有云部署、亿级以上向量规模、高并发检索需求(如银行风控系统)。
2. Qdrant
核心优势:基于Rust开发(性能强劲),支持稀疏向量检索(比传统稠密向量检索速度提升16倍),内置标量量化和产品量化技术,存储效率高;
优点:云原生设计(支持K8s部署)、高性能过滤(结构化字段筛选不影响检索速度)、支持地理空间向量(适配LBS场景);
缺点:社区生态较新,中文文档和实战案例相对较少,大规模集群运维经验不足;
适用场景:电商推荐、广告投放、中大型企业私有化部署(有一定技术储备)。
3.2 云原生托管向量数据库(中小团队首选)
1. Pinecone
核心优势:全托管服务(无需部署运维),实时数据更新延迟低于100ms,支持Serverless计费模式(按查询次数付费),开箱即用;
优点:零运维成本、与LangChain生态无缝集成、支持动态扩容(无需手动调整集群);
缺点:成本较高(大规模数据场景费用显著,亿级向量年费用可达数万元)、数据存储在海外(部分合规场景受限);
适用场景:SaaS产品快速集成、中小团队验证RAG方案、无运维资源的创业公司。
2. 腾讯云VectorDB
核心优势:国产化方案(数据合规有保障),单索引支持千亿向量,集成AI套件可实现文档自动向量化(无需手动调用嵌入模型);
优点:端到端RAG解决方案(含文档解析、嵌入生成、检索优化)、与腾讯云生态深度整合(兼容云服务器、对象存储);
缺点:依赖腾讯云基础设施,跨云部署受限,小规模场景性价比不高;
适用场景:政务、金融等数据主权敏感场景,国内企业生产环境部署。
3.3 轻量级向量数据库工具(开发/测试首选)
1. Chroma
核心优势:“零门槛上手”,无需数据库背景,5分钟即可完成单机部署,支持内存/文件两种存储模式;
优点:API简洁(几行代码实现向量增删改查)、支持LangChain/Python客户端、适合快速原型验证;
缺点:不支持分布式部署,性能上限低,无法承载生产级大规模数据(百万级向量以上易卡顿);
适用场景:学术研究、本地开发测试、初创团队验证RAG原型。
2. Faiss(Meta开源)
核心优势:GPU加速检索库,性能标杆级存在——百万级向量查询延迟低于10ms,常作为其他向量数据库的底层检索引擎;
优点:算法丰富(支持10+索引类型)、支持混合检索架构、可自定义优化检索策略;
缺点:无托管服务,需自行处理分布式部署和高可用性(如集群容错、数据备份),更偏向“工具库”而非“数据库”;
适用场景:本地测试、自定义向量检索引擎开发、作为分布式数据库的底层组件。
3.4 传统数据库扩展方案(渐进式改造首选)
MongoDB Atlas
核心优势:在文档数据库基础上嵌入向量索引,每个文档可存储16MB向量数据,适合已有MongoDB基础设施的企业;
优点:事务处理与向量检索一体化(无需跨数据库操作)、兼容现有业务逻辑、支持混合查询;
缺点:向量检索性能弱于专用向量数据库(亿级向量查询延迟超500ms),扩展性受限;
适用场景:传统文档系统智能化升级、向量数据与业务数据需强一致性的场景。
其他扩展方案
PostgreSQL(pgvector插件):适合已有PostgreSQL集群的团队,开发成本低,但高维向量性能较差;
ElasticSearch:通过 dense_vector 类型支持向量存储,适合“全文检索+向量检索”混合场景,但纯向量检索效率不如专用数据库。
四、综合选型对比表(一目了然)
选型维度 Milvus Qdrant Pinecone Chroma MongoDB Atlas
部署模式 私有化/云集群 私有化/云集群 全托管Serverless 单机嵌入/文件存储 全托管/私有化
学习曲线 复杂(需运维团队) 中等(Rust生态) 简单(零运维) 极简(开箱即用) 低(熟悉MongoDB即可)
扩展能力 千亿级向量(自动分片) 十亿级向量(自动分片) 亿级向量(自动扩容) 百万级向量(无扩展) 千万级向量(分库分表)
典型场景 企业私有云、高并发 电商推荐、高性能过滤 中小团队SaaS集成 本地开发、原型验证 传统业务智能化改造
成本模型 基础设施+运维成本 基础设施+运维成本 按查询/存储量付费 免费(单机) 数据库集群费用
生态兼容性 支持LangChain/LLaMA 支持LangChain/云原生 深度集成LangChain 支持LangChain/OpenAI 兼容MongoDB生态
五、技术选型实战建议(避免踩坑)
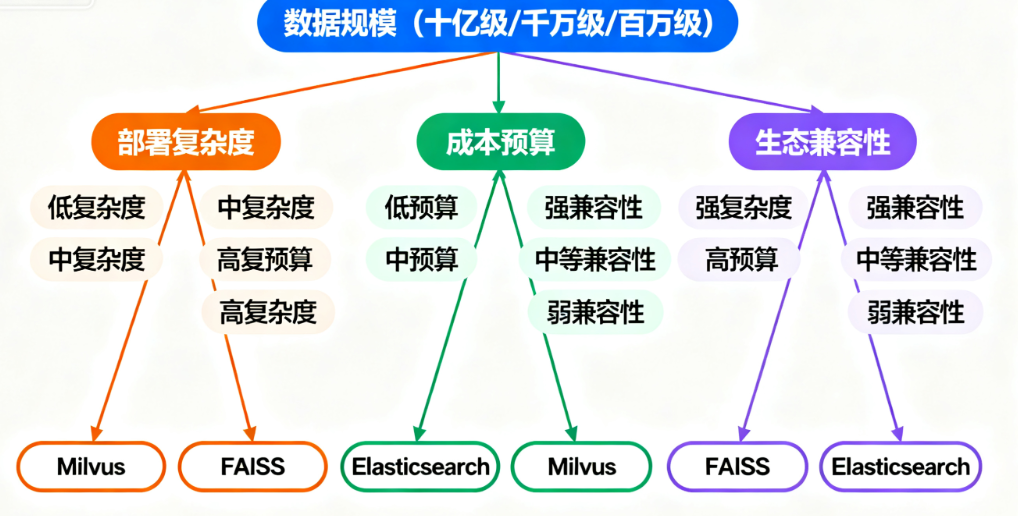
选型的核心逻辑是:匹配业务场景、团队能力和成本预算,而非盲目追求“性能最强”或“功能最全”,具体可按以下维度决策:
1. 按数据规模选型
十亿级以上:优先选分布式方案(Milvus、腾讯云VectorDB),支持水平扩容,能承载高并发检索;
千万-亿级:可选Qdrant(私有化)或Pinecone(托管),平衡性能和运维成本;
百万级以下:轻量级工具(Chroma、Faiss)足够,开发快、成本低,适合原型验证或小流量场景。
2. 按部署复杂度选型
无运维团队(中小团队):优先云原生托管方案(Pinecone、腾讯云VectorDB),零部署成本,专注业务开发;
有运维团队(大企业):私有化部署(Milvus、Qdrant),可控性强,数据安全性更高;
已有传统数据库:渐进式改造(MongoDB Atlas、pgvector),降低技术迁移成本。
3. 按成本预算选型
长期可控成本:开源方案(Milvus、Qdrant),一次性投入基础设施,后续无额外费用;
短期试错:Serverless方案(Pinecone),按用量付费,无需提前投入;
零成本测试:Chroma、Faiss,本地部署免费,适合前期技术验证。
4. 按生态兼容性选型
国产化需求:腾讯云VectorDB、华为云向量数据库,符合数据合规要求;
RAG系统集成:优先选支持LangChain的方案(Milvus、Pinecone、Chroma),减少开发工作量;
多模态场景:Qdrant(支持稀疏/稠密向量)、Pinecone(多模态向量兼容),适配文本、图像等多类型数据。
六、总结
向量数据库是AI时代的“专用存储工具”,选型的关键是“对症下药”——不用盲目追求千亿级性能,也别用MySQL硬扛高维向量检索。对于RAG系统开发者来说:
快速验证原型:选Chroma(5分钟上手);
中小团队生产环境:选Pinecone(零运维);
大企业私有化部署:选Milvus(稳定可靠);
传统系统改造:选MongoDB Atlas/pgvector(降低迁移成本)。
如果觉得本文有帮助,欢迎关注我的博客,后续会更新「Milvus实战部署」
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

















 2203
2203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









