



一、基础概念(10个)
1、人工智能(AI)
让机器模拟人类智能行为的技术。
2、机器学习(ML)
从数据中自动学习规律的AI子领域。
3、深度学习(DL)
基于神经网络的机器学习方法。
4、大模型(Large Model)
参数量巨大、泛化能力强的AI模型。
5、大语言模型(LLM)
专用于处理和生成自然语言的大模型。
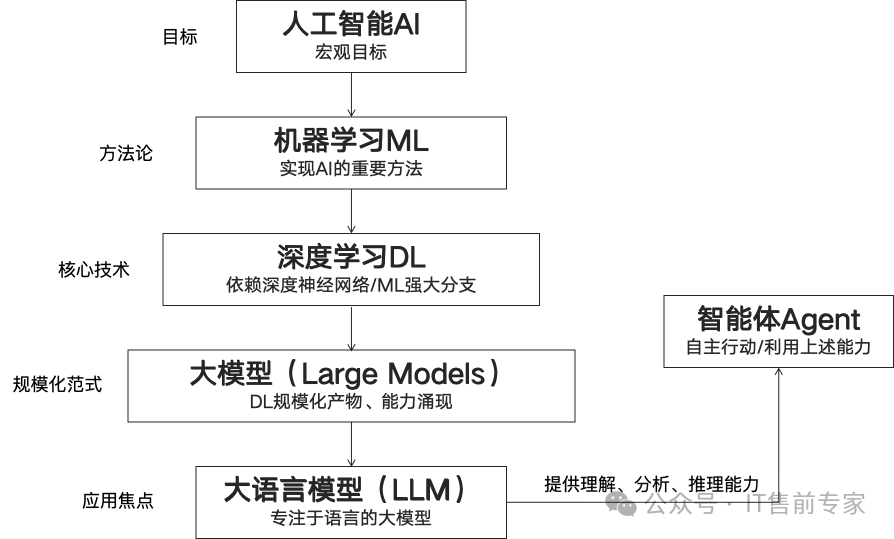
6、生成式AI(Generative AI)
能创造新内容(文本、图像、音频等)的AI。
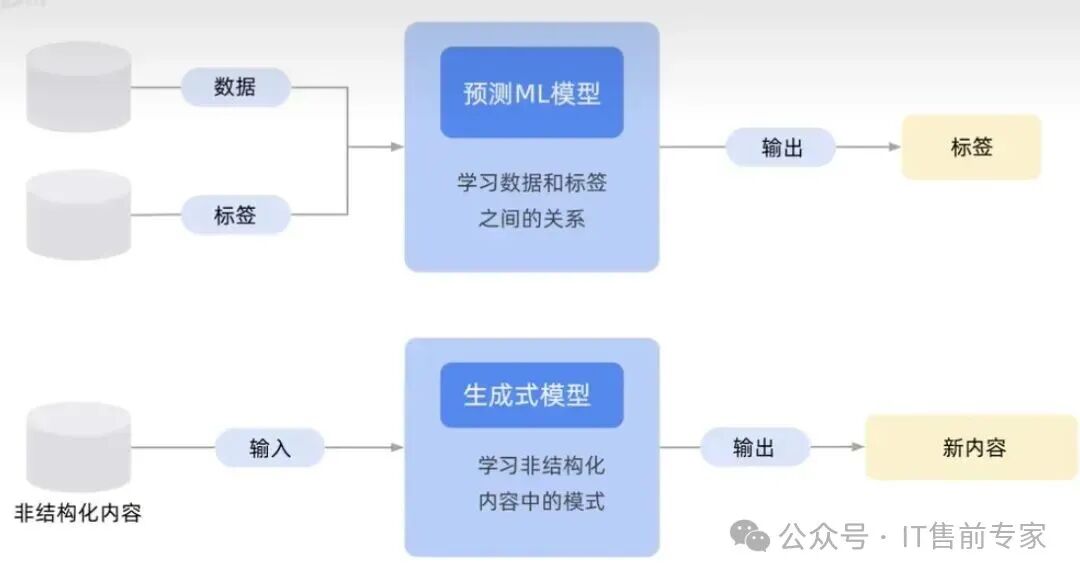
7、多模态(Multimodal)
能同时处理文本、图像、音频等多种模态数据。
8、通用人工智能(AGI)
具备人类水平通用智能的终极目标(尚未实现)。
9、涌现(Emergence)
模型规模达到阈值后出现的新能力(如推理、代码生成)。
10、Token(词元)
大模型处理文本的最小单位(如单词、子词、汉字)。
二、模型架构(12个)
11、Transformer
基于自注意力机制的主流大模型架构。
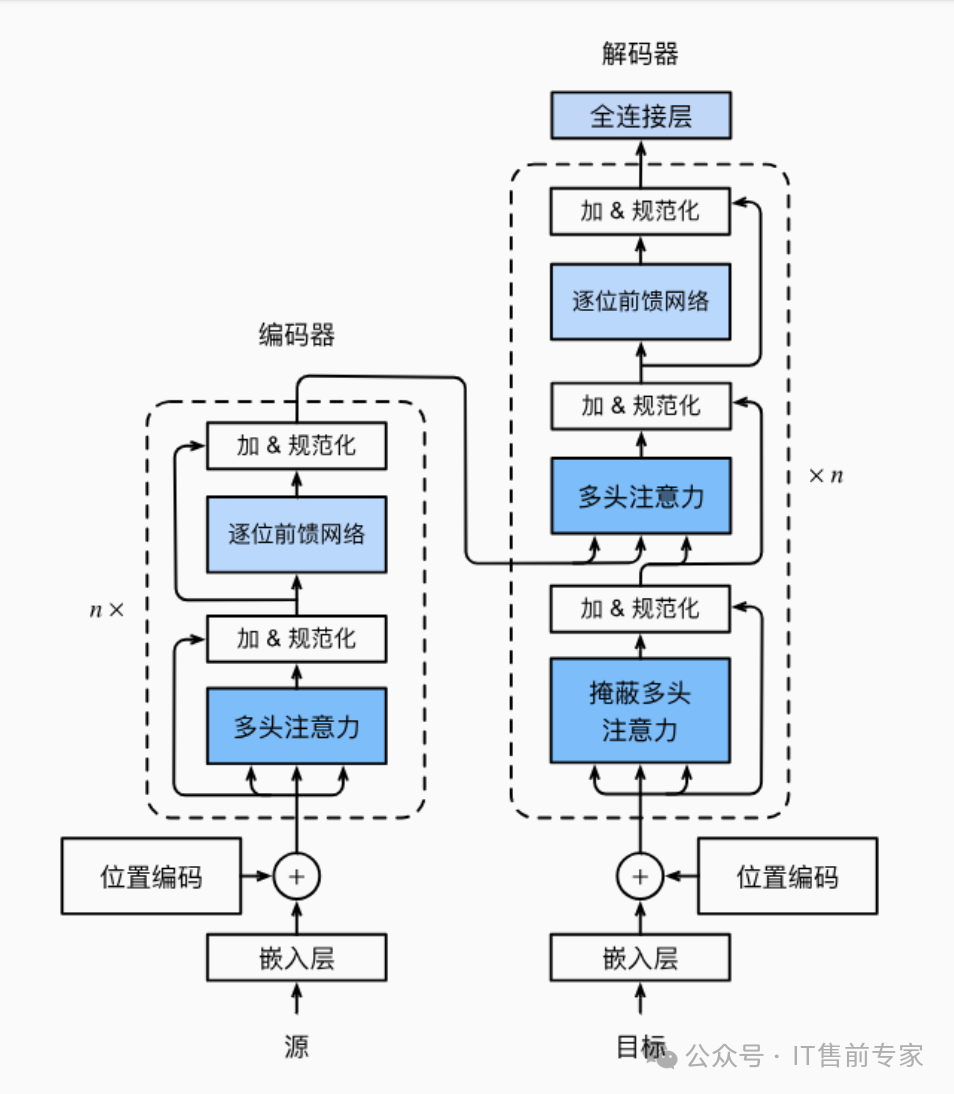
Transformer的架构如上图,分成编码器和解码器两大部分,根据模型参数量的不同堆叠的层数也是不同的。
12、自注意力机制(Self-Attention)
让模型动态关注输入不同部分的机制。
13、多头注意力(Multi-Head Attention)
并行多个注意力头,提升表达能力。
14、编码器(Encoder)
将输入转化为语义向量(如BERT)。
15、解码器(Decoder)
根据上下文生成输出(如GPT)。
16、Encoder-Decoder
用于翻译、摘要等任务的架构(如T5)。
17、位置编码(Positional Encoding)
为Token添加顺序信息。
18、前馈神经网络(FFN)
Transformer中的非线性变换层。
19、残差连接(Residual Connection)
缓解梯度消失,加速训练。
20、层归一化(LayerNorm)
稳定训练过程的归一化技术。
21、MoE(Mixture of Experts)
稀疏激活多个专家子网络,提升效率。
22、稀疏模型(Sparse Model)
每次推理只激活部分参数的模型。
三、训练技术(18个)
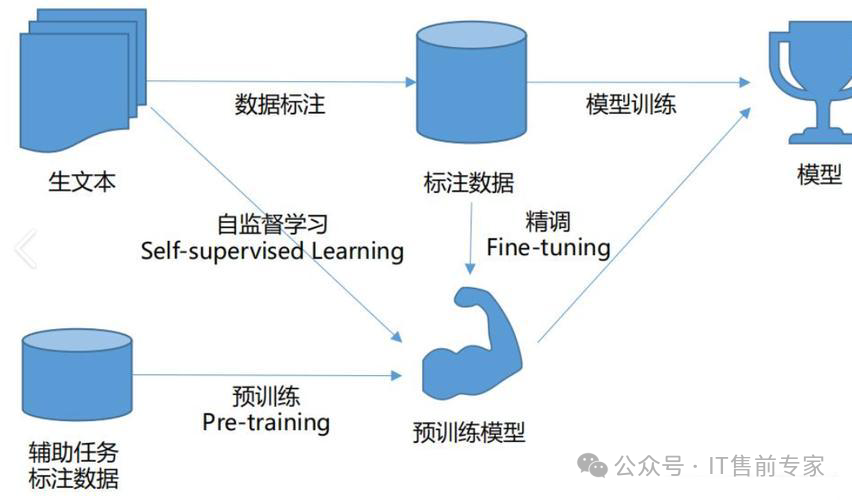
23、预训练(Pre-training)
在海量无标签数据上学习通用知识。
24、微调(Fine-tuning)
在特定任务数据上调整模型参数。
25、指令微调(Instruction Tuning)
用“指令-响应”对训练模型理解任务。
26、全量微调(Full Fine-tuning)
更新所有模型参数。
27、参数高效微调(PEFT)
只训练少量参数,降低成本。
28、LoRA(Low-Rank Adaptation)
通过低秩矩阵注入适配信息。
29、Adapter
在层间插入小型可训练模块。
30、Prompt Tuning
训练可学习的软提示(Soft Prompt)。
31、Prefix Tuning
在输入前添加可训练前缀。
32、迁移学习(Transfer Learning)
将在一个任务学到的知识迁移到新任务。
33、自监督学习(Self-supervised Learning)
利用数据自身结构作为监督信号。
34、掩码语言建模(MLM)
BERT类模型的预训练任务(如“填空”)。
35、因果语言建模(CLM)
GPT类模型的预训练任务(预测下一个词)。
36、对比学习(Contrastive Learning)
拉近正样本、推开负样本。
37、模型蒸馏(Distillation)
大模型“教”小模型,压缩知识。
38、数据增强(Data Augmentation)
扩充训练数据多样性。
39、课程学习(Curriculum Learning)
从简单到复杂逐步训练。
40、混合精度训练(Mixed Precision)
用FP16+FP32加速训练并节省显存。
四、推理与部署(12个)
41、推理(Inference)
输入问题,模型生成答案的过程。
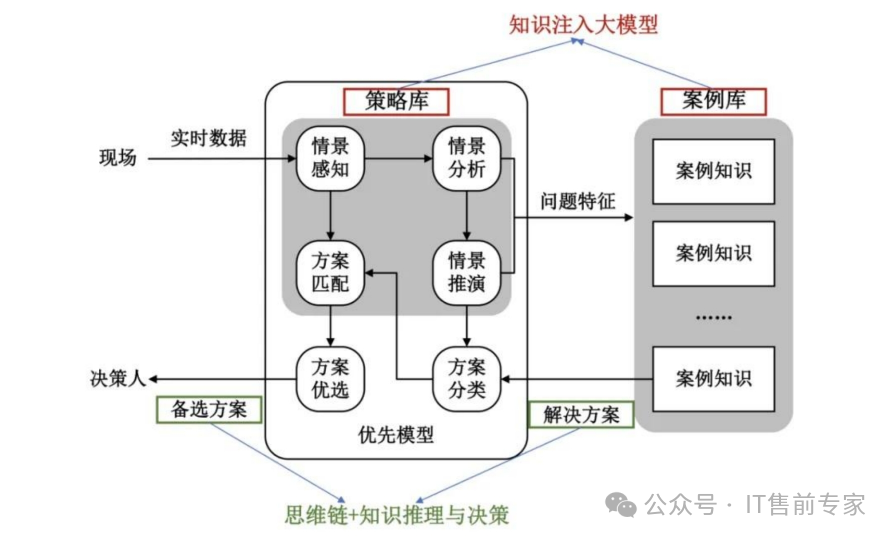
42、私有化部署(On-premise Deployment)
在本地服务器运行模型。
43、云部署(Cloud Deployment)
通过云服务调用模型API。
44、量化(Quantization)
用低比特(如INT8)表示权重,压缩模型。
45、剪枝(Pruning)
移除不重要的神经元或连接。
46、知识蒸馏部署
用蒸馏后的小模型替代大模型推理。
47、推理加速(Inference Acceleration)
通过编译、缓存等技术提速。
48、批处理(Batching)
一次处理多个请求,提升吞吐。
49、KV Cache(键值缓存)
缓存注意力键值,避免重复计算。
50、流式输出(Streaming Output)
边生成边返回结果。
51、镜像(Docker Image)
打包环境、依赖、模型的一体化部署单元。
52、边缘部署(Edge Deployment)
在终端设备(如手机)运行模型。
五、提示与交互(10个)
53、提示词(Prompt)
用户输入给模型的指令或上下文。
54、上下文窗口(Context Window)
模型一次能处理的最大Token数(如128K)。
55、提示工程(Prompt Engineering)
设计高效Prompt引导模型输出。
56、思维链(Chain-of-Thought, CoT)
让模型“分步推理”提升准确性。
57、少样本学习(Few-shot Learning)
在Prompt中提供少量示例。
58、零样本学习(Zero-shot)
不给示例,直接提问。
59、系统提示(System Prompt)
设定模型角色或行为规则。
60、温度(Temperature)
控制输出随机性(高=创意,低=确定)。
61、Top-p / Top-k 采样
限制生成时的候选词范围。
62、停止词(Stop Token)
指定生成结束的标志。
六、知识增强与外部工具(10个)
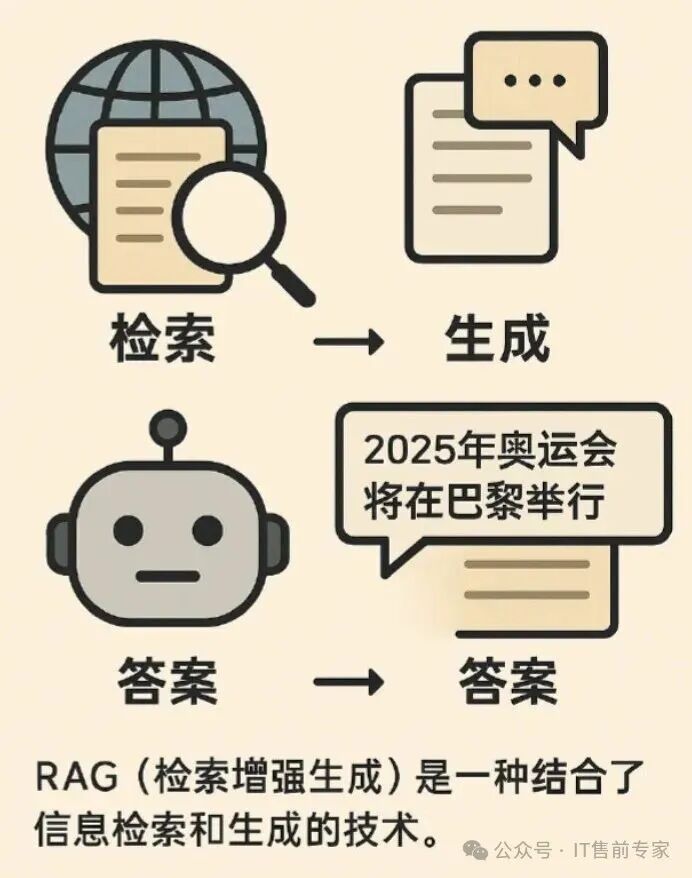
63、RAG(检索增强生成)
先检索知识库,再生成答案。
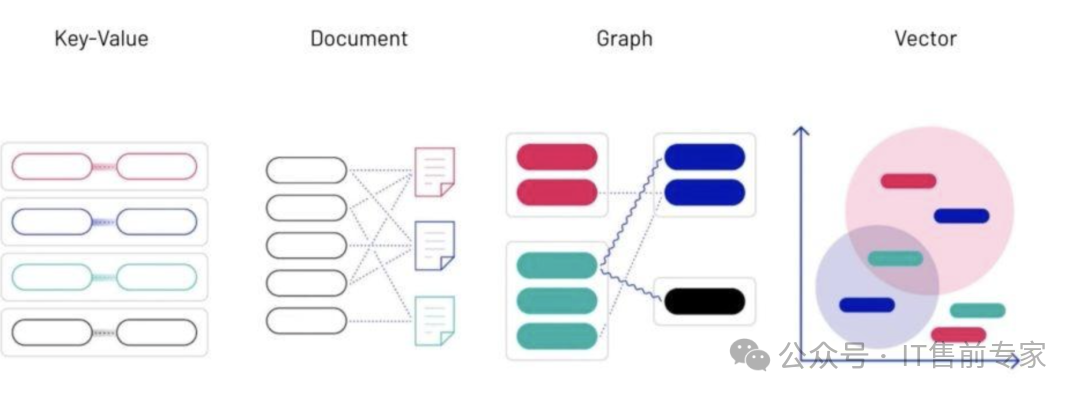
64、向量数据库(Vector Database)
存储文本向量,支持语义检索。
65、嵌入(Embedding)
将文本转化为语义向量。
66、向量检索(Vector Search)
基于相似度查找相关文档。
67、智能体(Agent)
能自主规划、调用工具、执行任务的AI程序。
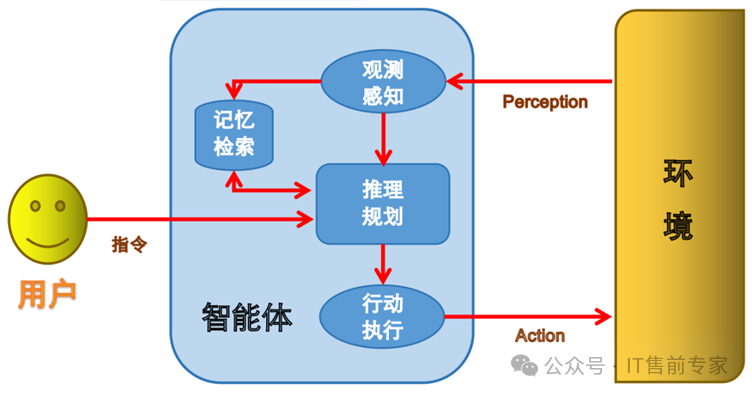
68、工作流(Workflow)
多个AI步骤串联的自动化流程。
69、MCP(Model Context Protocol)
AI操作外部工具的通用接口标准。
70、AutoGen / LangGraph
构建多智能体协作的框架。
71、Function Calling
模型调用外部函数(如查天气、计算)。
72、插件系统(Plugin System)
扩展模型能力的模块化设计。
七、评估与安全(10个)
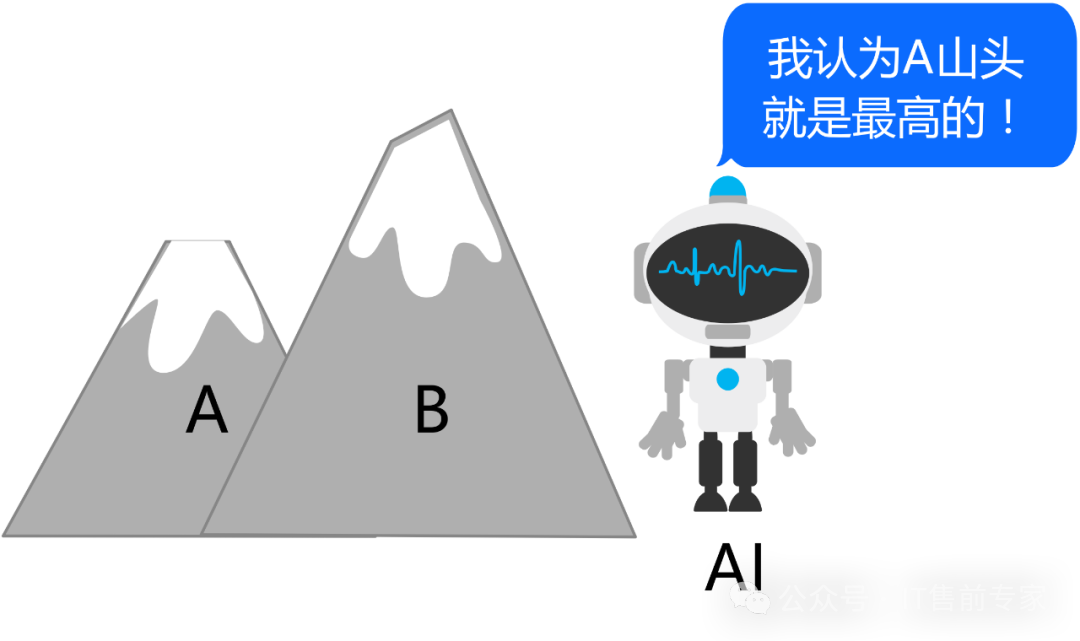
73、幻觉(Hallucination)
模型生成看似合理但错误的内容。
74、偏见(Bias)
模型输出反映训练数据中的不公平倾向。
75、对抗攻击(Adversarial Attack)
恶意输入误导模型。
76、鲁棒性(Robustness)
模型在扰动下保持性能的能力。
77、BLEU / ROUGE
自动评估生成文本质量的指标。
78、Perplexity(困惑度)
衡量语言模型预测能力的指标。
79、人类反馈强化学习(RLHF)
用人类偏好优化模型输出。
80、DPO(Direct Preference Optimization)
RLHF的高效替代方案。
81、内容安全过滤
防止生成违法、有害内容。
82、可解释性(Interpretability)
理解模型决策过程的能力。
八、开源与生态(8个)
83、闭源模型(Closed-source)
不公开权重和代码(如GPT-4)。
84、开放权重(Open-weight)
可下载权重但不一定开源训练代码(如Llama)。
85、完全开源(Fully Open)
代码、权重、数据全部公开。
86、Hugging Face
全球最大的AI模型开源社区。
87、LangChain / LlamaIndex
建AI应用的开发框架。
88、Ollama / vLLM / Text Generation WebUI
本地运行大模型的工具。
89、卖铲子(Tooling Providers)
为AI开发者提供基础设施的公司。
90、套壳(API Wrapper)
封装大模型API做成产品,无核心技术。
九、前沿趋势(10个)
91、Agent 智能体
能自主思考、行动、协作的AI。
92、世界模型(World Model)
模拟现实世界动态的AI。
93、推理模型(Reasoning Model)
专精逻辑、数学、代码的模型。
94、长上下文(Long Context)
支持百万Token输入的模型。
95、模型即服务(MaaS)
通过API提供模型能力。
96、AI Infra(AI基础设施)
芯片、框架、云平台等底层支撑。
97、AI for Science
用AI加速科研(如蛋白质结构预测)。
98、具身智能(Embodied AI)
在物理世界中行动的AI(如机器人)。

99、联邦学习(Federated Learning)
在不共享数据的前提下协同训练。
100、AI治理(AI Governance)
对AI发展进行伦理与法律监管。
✅ 建议使用方式:
-
先通读分类,建立框架;
-
对不熟悉的词,逐个追问AI或查资料。

















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









