




对于 RAG 系统而言,从文档中提取信息是一个不可避免的情况。最终系统输出的质量很大程度上取决于从源内容中提取信息的效果。
对于 RAG 系统而言,从文档中提取信息是一个不可避免的情况。最终系统输出的质量很大程度上取决于从源内容中提取信息的效果。
过去,我曾从不同角度探讨过文档解析问题[1]。本文结合近期一篇 RAG 调查报告[2]的发现与我之前的部分研究,对 RAG 系统如何解析和整合结构化、半结构化、非结构化和多模态知识进行了简明概括。
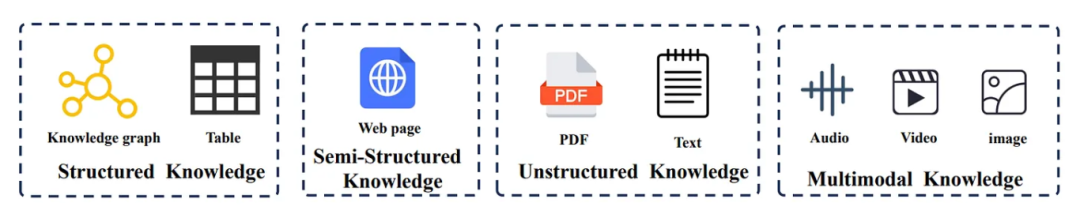
image.png
Figure 1: RAG 系统整合的多种知识类型,涵盖结构化、半结构化、非结构化和多模态知识。[Source[2]]
1.结构化知识:数据按规则组织的范式
1.1 知识图谱:易于查询,便于使用,难以集成
知识图谱以一种清晰、互联的方式描述实体及其关系,使其成为机器系统的图谱遍历与查询的理想选择。
RAG 系统非常喜欢这样的结构化数据源 —— 它们精确且语义丰富。但真正的挑战不在于查找数据,而在于如何有效地利用它。
- 如何从海量知识图谱中提取有意义的子图?
- 如何将结构化的图谱数据与自然语言对齐?
- 随着图谱规模的增长,系统是否仍能保持高效?
一些有前景的解决方案正逐步解决这些问题:
- GRAG 从多个文档中检索子图,来生成更聚焦的输入。
- KG-RAG 采用探索链算法(Chain of Explorations,CoE)来优化基于知识图谱的问答性能。
- GNN-RAG 采用图神经网络(GNN)检索和处理来自知识图谱(KG)的信息,在数据输入大语言模型(LLM)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1298
1298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









