



SAIL可广泛应用于图文问答、图像字幕生成、OCR文本理解、图像分类与分割等任务。其架构简洁、计算效率高,尤其适合资源受限场景、移动端推理部署,或需要灵活扩展的多模态AI系统。
一眼概览
SAIL提出了一种统一的单Transformer多模态大模型架构,无需视觉编码器,仅凭混合注意力机制即可实现媲美模块化模型的图文理解与视觉任务表现。
核心问题
当前主流多模态大模型采用模块化架构(如CLIP-ViT + LLM),尽管性能强大,但存在模型分裂、部署复杂和视觉编码器依赖等问题。该研究试图解决:是否能用一个Transformer模型统一处理图像和文本,简化架构的同时保持或提升多模态性能?
技术亮点
1. 架构极简:SAIL摒弃视觉编码器,将图像与文本作为统一序列输入单一Transformer处理,打破图文模态界限;
2. 混合注意力机制:图像patch使用双向注意力,文本保持因果注意力,提升跨模态对齐与视觉感知能力;
3. 强视觉能力涌现:仅通过图文预训练,SAIL在图像分类与语义分割中表现出媲美ViT-22B的能力,展现其潜在的视觉主干功能。
方法框架
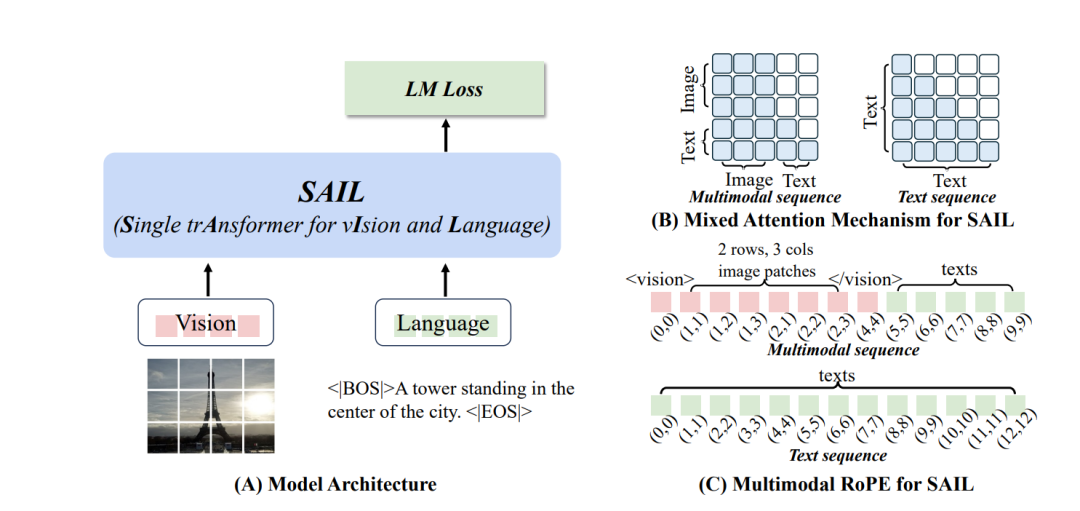
图片
SAIL方法流程如下:
1. 统一输入构建:将图像切成patch投影为向量,嵌入特殊标记,与文本序列拼接后送入统一Transformer;
2. 混合注意力应用:图像patch之间启用全连接双向注意力,文本保持因果注意力,实现高效图文融合;
3. 位置编码设计:采用多模态RoPE,对图像使用二维位置嵌入,对文本使用一维编码,统一空间表示;
4. 两阶段预训练策略:
• 阶段一:标准尺寸图像+文本混合训练,加速视觉感知;
• 阶段二:任意分辨率图像+文本,增强泛化能力;
5. 监督微调:使用多源指令数据,优化语言理解与对话能力。
实验结果速览
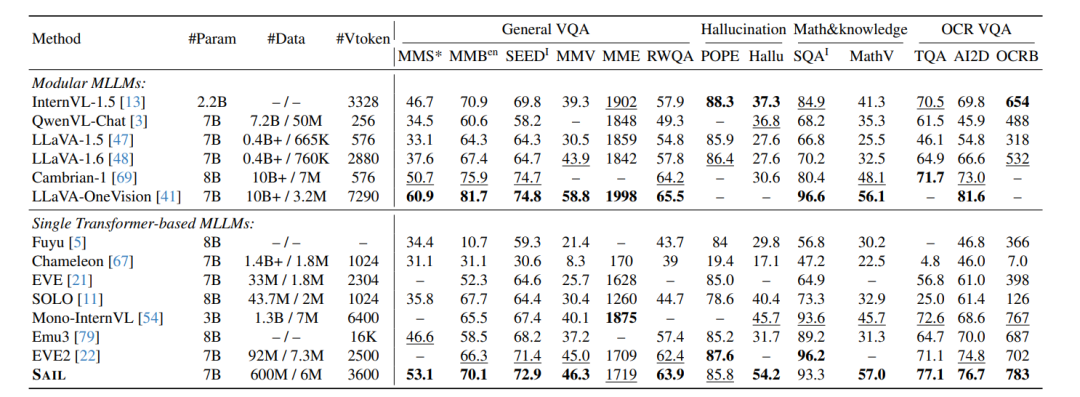
1. 多模态基准表现(Table 2):
• 在13项图文任务中,SAIL超过所有单Transformer架构,部分任务逼近模块化模型如LLaVA-OneVision。
2. 视觉任务性能(Table 3-5):
• ImageNet Top-1:84.95%;
• ADE20K语义分割mIoU:55.30%;
• ARO属性、关系、顺序理解任务:全部达到100%准确率。
3. 可扩展性分析(Figure 1 & 3):
• 数据规模提升时,SAIL性能增速高于模块化模型;
• 模型规模从0.5B扩展到7B时,训练损失显著下降,任务表现持续提升。
实用价值与应用
SAIL可广泛应用于图文问答、图像字幕生成、OCR文本理解、图像分类与分割等任务。其架构简洁、计算效率高,尤其适合资源受限场景、移动端推理部署,或需要灵活扩展的多模态AI系统。
开放问题
• SAIL在知识密集型任务中略逊于模块化模型,如何增强其通识世界知识理解能力?
• 双向注意力机制是否适用于视频等更复杂模态的统一建模?
• 如果引入更强的文本生成监督,SAIL是否能在生成质量上进一步提升?

















 2118
2118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









