




随着大语言模型(LLM)技术的快速发展,人们期望利用 LLM 解决各种复杂问题,在此背景下,构建智能体(Agent)应用受到了广泛关注。用户与 LLM 的交互可以被视为一种 单智能体(Single-Agent) 行为:用户通过提示词(prompt)与通用 LLM 进行对话,LLM 理解问题并提供反馈。然而,单一智能体在处理复杂任务时存在明显局限性,例如需要用户多次引导、缺乏对外部环境的感知能力、对话历史记忆有限等。
试想以下场景:在不同处理阶段调用不同的模型;当 LLM 无法完成任务时,自动查询外部知识库;或者由 LLM 自主纠正生成内容中的幻觉和错误。这些需求如何实现? 多智能体(Multi-Agent) 系统正是解决这类问题的有效工具。通过提示词模板为每个智能体分配角色并规范其行为,多个智能体相互协作,从而完成复杂的任务。
然而,构建多智能体应用并非易事,开发者需要面对智能体设计、通信协议、协调策略等多方面的问题。LangGraph 提供了一种以图(graph)为核心的解决方案,清晰定义了智能体之间的关系与交互规则,并通过内置的通信接口和协调策略,帮助开发者快速构建高效且可扩展的分布式智能系统。
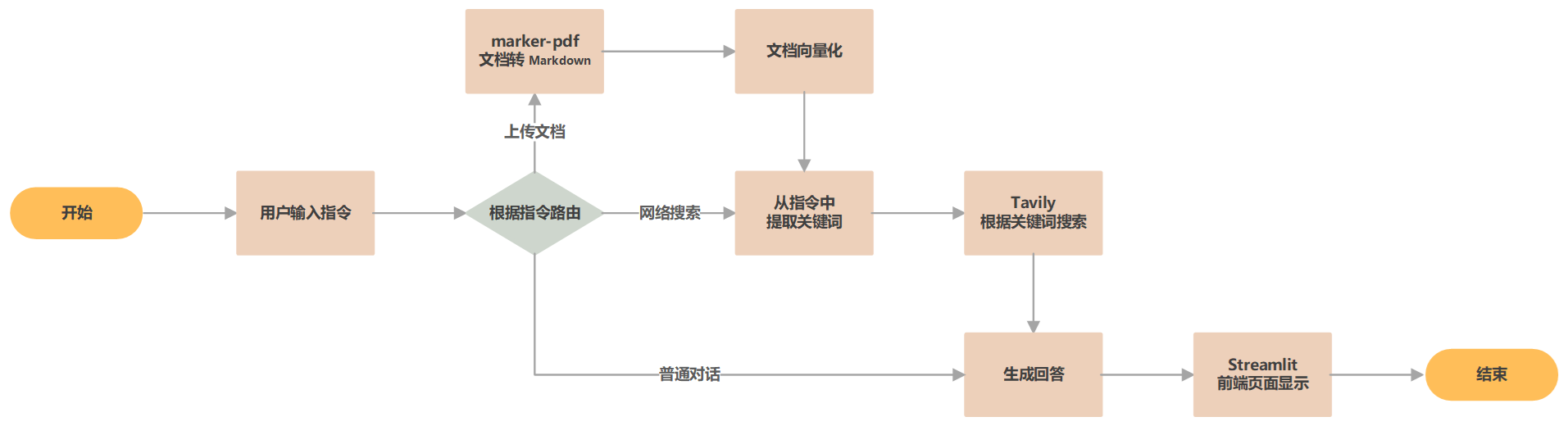
接下来,我们将通过一个实例展示如何使用 LangGraph 构建一个多智能体应用,并结合 Streamlit 实现用户友好的前端界面。 该应用具备以下功能:
- 根据对话类型将请求路由到适当的处理节点。
- 支持联网搜索,获取实时信息。
- 根据问题和对话历史生成优化的搜索提示词。
- 支持文件上传与处理。
- 利用编程专用的 LLM 解决代码相关问题。
- 基于提供的文档内容,总结生成答案。
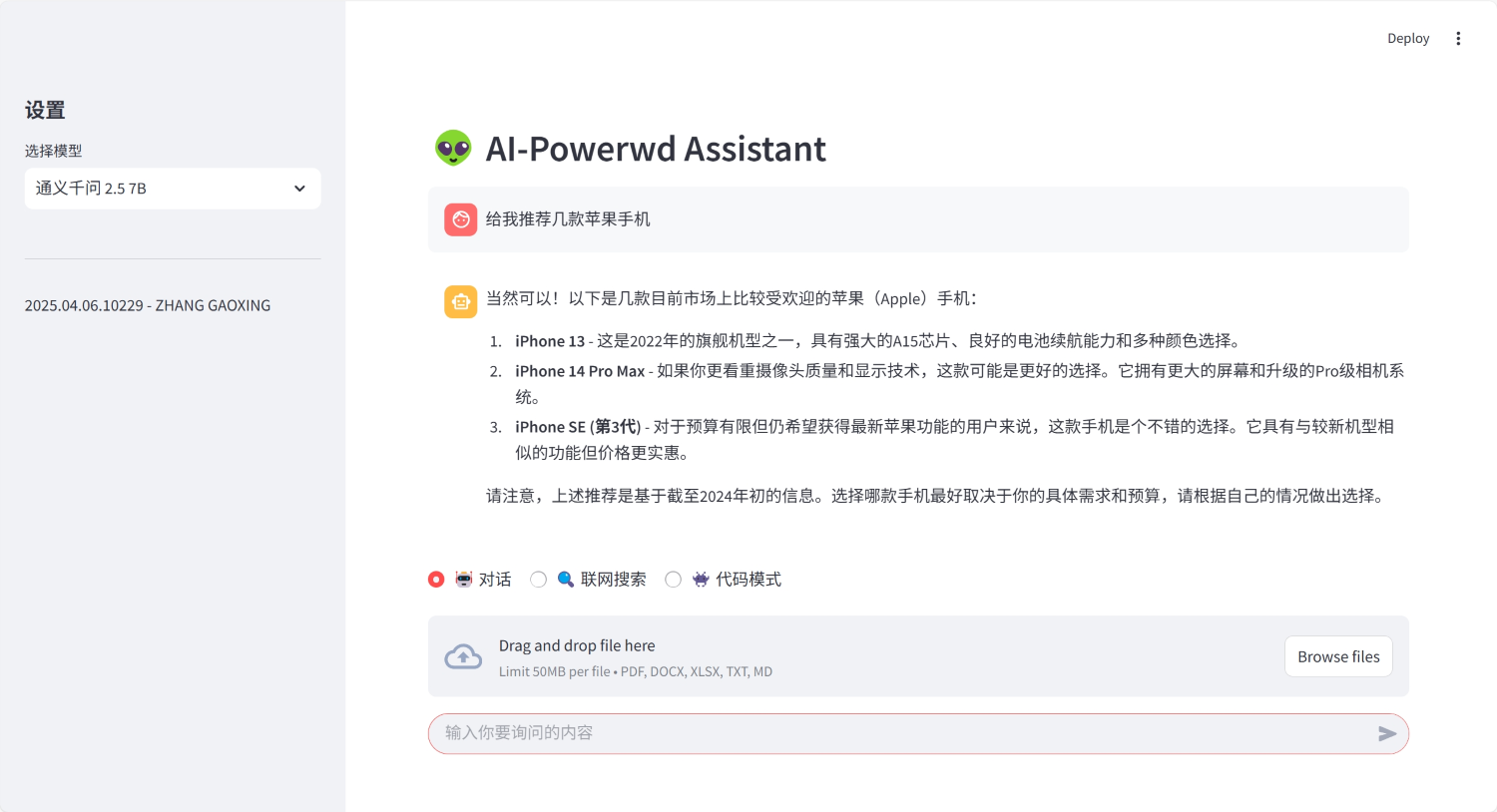
环境搭建与配置
项目结构如下:
.
├── .streamlit # Streamlit 配置
│ └── config.toml
├── chains # 智能体
│ ├── generate.py
│ ├── models.py
│ └── summary.py
├── graph # 图结构
│ ├── graph.py
│ └── graph_state.py
├── upload_files # 上传的文件
│ └── .keep
├── .env # 环境变量配置
├── app.py # Streamlit 应用
├── main.py # 命令行程序
└── requirements.txt # 依赖
requirements.txt 中列出了程序必要的包,使用命令 pip install -r requirements.txt 安装依赖。
# LangChain 相关包
langchain
langchain-ollama
langchain-chroma
langchain-community
langgraph
chromadb
tavily-python
python-dotenv
# 文档处理相关包
marker-pdf
weasyprint
mammoth
openpyxl
unstructured[all-docs]
libmagic
# Streamlit 相关包
streamlit
streamlit-chat
streamlit-extras
# 文档使用GPU处理时,安装GPU版PyTorch
# use 'pip install -r requirements.txt --proxy=127.0.0.1:23474' to accelerate download speed
# --extra-index-url https://download.pytorch.org/whl/cu124
# torch==2.6.0+cu124
# torchvision==0.21.0+cu124
相关的环境变量配置在 .env 文件中,在程序中通过 dotenv 包读取。
TAVILY_API_KEY=tvly-dev-xxxxxx # Tavily API 密钥
OMP_NUM_THREADS=8 # 设置线程数
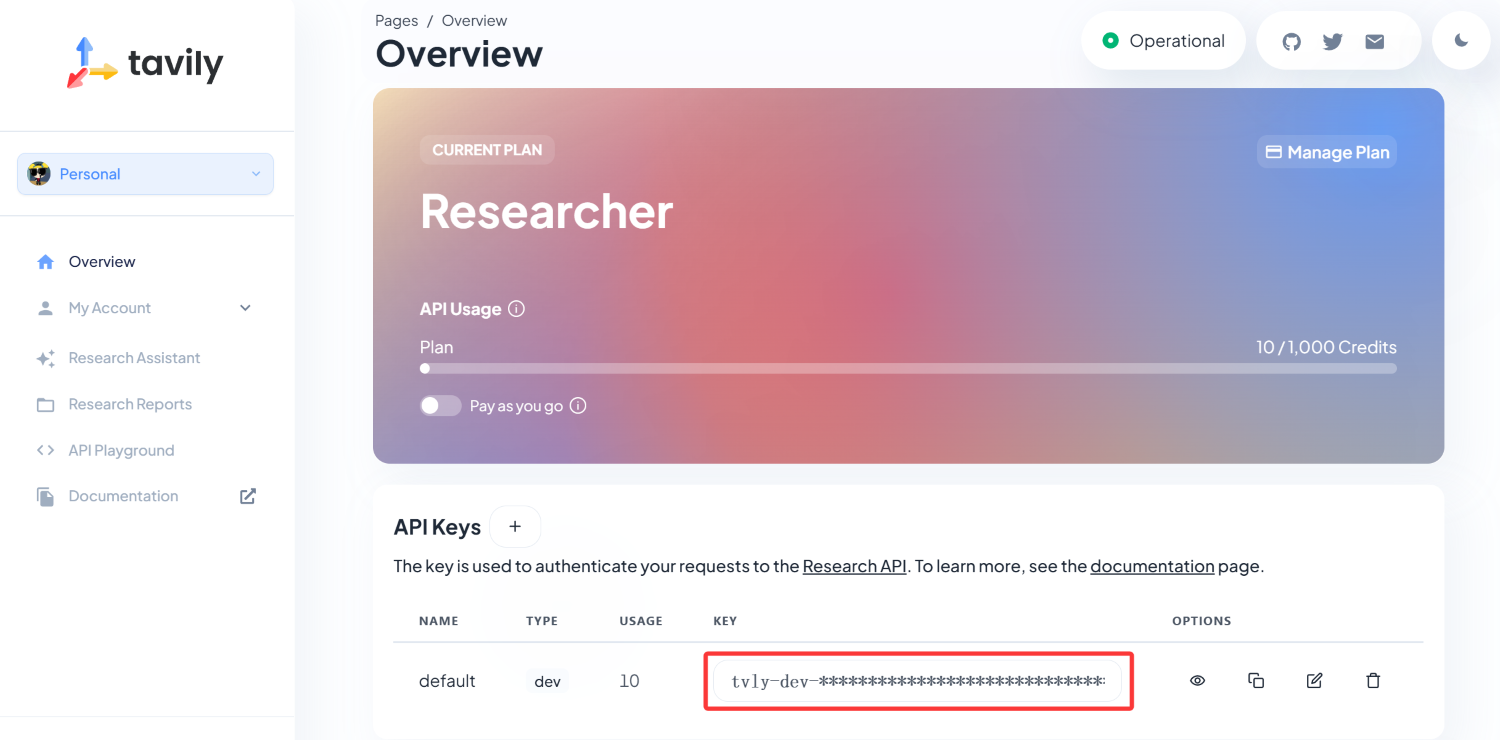
其中 TAVILY_API_KEY 是 Tavily 的 API 密钥,用于网络搜索服务,需要在 Tavily AI 注册并获取,每月有 1000 次的免费额度。
定义智能体
在 LangChain 中,使用 链(chain) 来定义用户与 LLM 交互的行为,即智能体。链是一个可调用的对象,接收输入并返回输出。在 chains 目录下,定义了两个链:summary.py 和 generate.py,分别用于提取关键词和生成回答。
.
├── chains # 智能体
│ ├── generate.py
│ ├── models.py
│ └── summary.py
加载模型
在定义智能体之前,需要先定义好加载模型的方法。models.py 文件负责根据提供的模型名称加载相应的模型。
from langchain_ollama import ChatOllama, OllamaEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
def load_model(model_name: str) -> ChatOllama:
"""
加载语言模型
参数:
model_name (str): 模型名称
返回:
ChatOllama实例,用于生成文本和回答问题
"""
return ChatOllama(model=model_name)
def load_embeddings(model_name: str) -> OllamaEmbeddings:
"""
加载嵌入模型
参数:
model_name (str): 模型名称
返回:
OllamaEmbeddings实例,用于将文本转换为向量表示
"""
return OllamaEmbeddings(model=model_name)
def load_vector_store(model_name: str) -> InMemoryVectorStore:
"""
创建内存向量存储
参数:
model_name (str): 用于生成嵌入的模型名称
返回:
InMemoryVectorStore实例,用于存储和检索向量化的文本
"""
embeddings = load_embeddings(model_name)
return InMemoryVectorStore(embeddings)
提取关键词
在 summary.py 文件中,定义了 SummaryChain 类,用于从用户问题和聊天记录中提取关键词,并生成高效的搜索查询。
from langchain.prompts import ChatPromptTe 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1054
1054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









