




性能永远是最令人着迷的技术领域,也是互联网公司软件工程师水平的体现。

引言:从“救火队员”到“性能神探”
在前面两篇文章中,我们学习了如何诊断系统的“结构性疾病”——从研发效能的“坏味道”到系统复杂度的“量化度量”。这些问题,如同慢性病,会逐渐侵蚀系统的健康和团队的士气。然而,在电商系统中,有问题的架构通常还会带来第三个问题,这是一个更为紧急、更为致命的“急性病”——性能瓶颈。
当大促洪峰来临,用户下单一直提示失败;当一个核心接口响应超时,导致下游服务连锁雪崩……这种时刻,性能问题就不再是一个技术指标,而是真金白银的损失和用户信任的崩塌。
在这样的高压场景下,我们经常看到两种截然不同的工程师:
第一种:“无头苍蝇式”的救火。开发人员接到“系统很卡”的报警后,凭借直觉和零散的经验,开始一连串的操作:重启一下应用?是不是缓存满了?加大数据库连接池?给服务器扩容?这些操作就像是乱枪打鸟,偶尔能蒙对一次,但更多时候是浪费了宝贵的排障时间,甚至可能让问题更加恶化。
第二种:则是我们这篇文章希望培养的“性能神探”。他们面对同样的问题,内心有一个清晰的罗盘和一套系统的方法论。他们不猜测,只测量;他们不盲动,只推理。他们会从最顶层的用户体验指标出发,像剥洋葱一样,一层一层地往下分析,利用各种现代化的“勘测工具”,最终在复杂的系统调用链中,精准地定位到那个拖慢了整个系统的“罪魁祸首”。
这篇文章的核心目的,就是要为大家装备上这套自顶向下的性能瓶颈定位方法论。我们将建立一套结构化的性能分析思维,彻底摒弃“我感觉是这里慢了”的直觉式优化。我们将遵循“先定位、再优化”的科学流程,学习如何将模糊的“慢”,转化为精准的、可度量的证据链。最终,通过一个真实感十足的大促故障演练,将这套方法论深植于你的架构师工具箱中。
一、 性能分析的基石:指标、定律与黄金准则
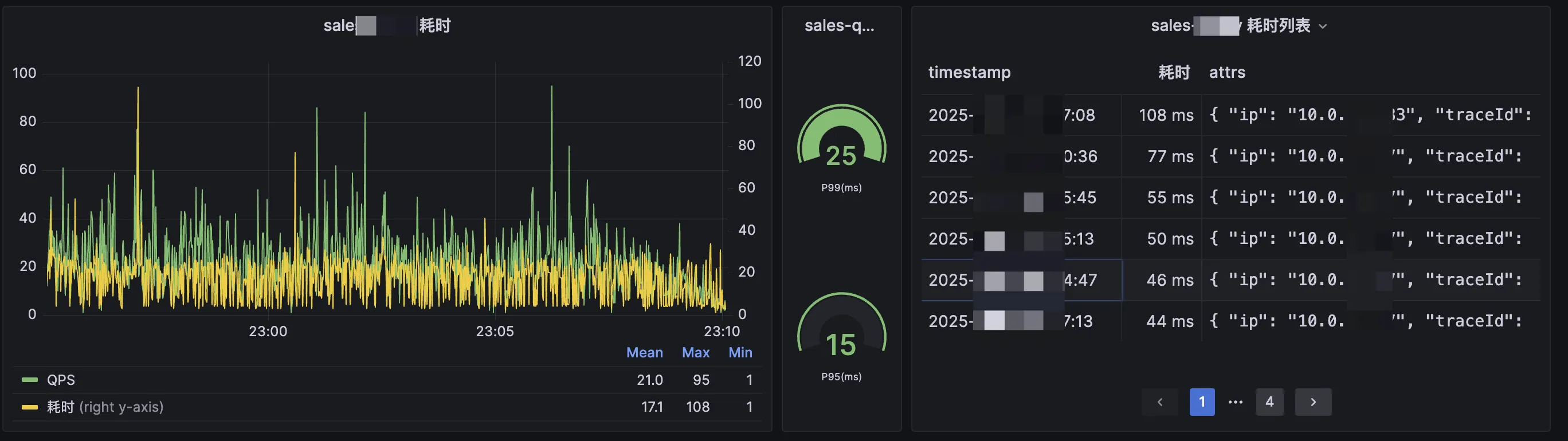
在成为“神探”之前,我们必须先学会同一种“语言”——性能度量的语言,并遵守其基本法则。
1. 三大核心性能指标
-
响应时间(Response Time, RT):这是从用户视角出发的“王者指标”。它衡量的是从用户发起请求到收到完整响应所花费的时间。但平均RT往往具有欺骗性,一次10秒的超时,可能被99次100毫秒的正常请求“平均”掉。因此,我们必须关注百分位RT:
-
P99:99%的请求响应时间都在这个数值以内。这个指标反映了系统最极端情况下的表现。
-
P95:95%的请求耗时。有些技术人员的观点认为,这通常是我们优化时重点关注的SLA(服务等级协议)目标。其实,不管是B端应用还是C端应用,这其实还不太够的,一流电商的核心应用都是4个9甚至是6个9,而低于P95的一般不用考虑。
-
-
吞吐量(Throughput):衡量系统处理能力的指标,通常用TPS(每秒事务数)或QPS(每秒查询数)来表示。它代表了系统的“带宽”,即单位时间内能处理多少请求。
-
并发数(Concurrency):系统在同一时刻正在处理的请求数量。
一般来说,对于一个接口而言,并发数不变的情况下,RT越长,同一时刻线程hold的资源越多,不光会导致系统处理能力下降而无法达到目标QPS,同时如果一旦系统资源被打满,然后还不断有请求进来,那么系统就危在旦夕,随时有崩掉的风险。
2. 性能优化的黄金准则
-
准则一:绝不猜测,永远测量 这是性能分析的第一铁律。任何没有数据支撑的性能优化,都是在“耍流氓”。人的直觉在复杂系统面前极不可靠,你以为的瓶颈,往往不是真正的瓶颈。所有的性能工作,必须始于测量,终于测量。
-
准则二:遵循科学流程 性能调优不是一蹴而就的撞大运,而是一个严谨的科学实验过程:
-
设立明确目标:例如,“将P99响应时间从500ms降低到200ms”。
-
建立性能基线:在优化前,通过压力测试,测量并记录系统当前的性能表现。
-
链路分析和定位瓶颈:基于数据分析,对调用链路分析,找出瓶颈点,即性能最差的那个模块,有可能是应用、数据库或者是外部接口等。
-
实施单点优化:一次只做一个变更。如果你同时改了JVM参数和SQL索引,那么当性能提升时,你无法判断是哪个改动起了作用。
-
再次测量与验证:在相同条件下再次进行压力测试,验证优化是否有效,效果有多大。
-
我司曾经有一个架构师对所在系统进行优化,解决OOM的问题,搞了两周,最后一点效果都没有,他是怎么做的呢?一会去翻翻代码, 一会去看看系统日志,一会去找运维看下CPU是不是满了。后来我来辅导他,让他先看并发量50的情况下,接口的QPS和耗时,然后去分析整个调用链,确定耗时最长的那一段耗时占比99%,然后定位到应用xx,因为是Java应用,再去dump堆栈信息,用JProfile去找是否有大对象,用了1个晚上定位到问题,修改jvm参数和对应代码,并通过压测实验验证OK,最终解决。
二、 自顶向下的分层定位法:架构师的“CT扫描”
一个完整的用户请求,会穿越一个庞大而复杂的系统。我们的方法,就是模拟这个请求的路径,从用户端开始,逐层进行“CT扫描”,检查每一层的“健康状况”。
第一层:用户端—— 浏览器里的“蛛丝马迹”
很多时候,服务器快如闪电,但用户依然觉得“卡”,问题可能出在用户的浏览器或者APP里。
-
分析方法:打开任何现代浏览器的开发者工具(F12),其中的
Network和Performance面板就是你的“放大镜”。 -
常见瓶颈:
-
网络瀑布流(Waterfall):
Network面板会展示每个资源的加载过程。是否存在某个巨大的图片或JS文件,加载耗时数秒?是否存在过多的HTTP请求(上百个),导致连接开销巨大? -
渲染阻塞:
<script>标签是否没有使用async或defer,阻塞了页面的渲染? -
前端性能:
Performance面板可以录制页面加载过程,分析是否存在耗时过长的JavaScript计算或页面重绘(Repaint/Reflow)。
-
-
诊断结论:如果分析发现,服务器的TTFB(Time To First Byte,首字节时间)很短(例如<200ms),但整个页面的
Load时间很长(例如>3s),那么瓶颈大概率就在前端。
第二层:网络—— 请求路上的“交通拥堵”
当请求离开浏览器,它就进入了复杂的互联网。
-
分析方法:使用
ping来测试延迟(RTT),traceroute来跟踪路由路径,并检查CDN(内容分发网络)的监控仪表盘。 -
常见瓶颈:
-
高延迟:用户与服务器的物理距离过远,导致RTT居高不下。
-
DNS解析慢:DNS服务器响应缓慢。
-
CDN配置不当:CDN回源率过高,没有起到缓存加速的作用。
-
-
诊断结论:如果TTFB本身就很高,且在不同地理位置的用户那里表现差异巨大,需要重点排查网络层。
第三层:应用服务(Application Server)—— 性能问题的“主战场”
这是绝大多数性能问题的“震中”。我们需要对应用服务器进行精细化的“解剖”。
1. CPU分析:谁“吃掉”了计算资源?
-
初步诊断:使用
top或htop命令,观察CPU使用率。是长期处于100%吗?是用户态(us)高,还是内核态(sy)高,或是IO等待(wa)高?-
us高:意味着是应用程序本身在进行大量计算。 -
wa高:这是个强烈的信号——CPU在空等,它在等待磁盘或网络IO的返回。应用本身可能不是瓶颈,瓶颈在它调用的下游服务(如数据库、缓存)。 -
sy高:可能是内核在进行大量的线程切换或内存分配。
-
-
精准定位——火焰图(Flame Graph):
-
这是CPU分析的“核武器”。火焰图是一个可视化的CPU性能分析工具,它能将CPU的耗时,按照代码的调用栈,清晰地展示出来。
-
如何阅读:Y轴代表调用栈的深度,X轴代表CPU时间的占比。火焰图顶部的“平顶”越宽,就意味着这个函数本身(不包括它调用的子函数)消耗的CPU时间越多,它就是最“热”的代码,是首要的优化目标。
-
2. 内存分析:GC是否在“拖后腿”?
-
诊断方法:分析GC日志,或使用
jstat、Arthas等工具。 -
常见瓶颈:
-
频繁的Full GC:当发生Full GC时,整个应用程序的所有线程都会被暂停(Stop-The-World),如果Full GC过于频繁或耗时过长,会严重影响响应时间。
-
内存泄漏:对象无法被回收,导致堆内存持续增长,最终引发
OutOfMemoryError。
-
第四层:中间件(Middleware)—— 依赖的“高速公路”是否畅通?
-
缓存(如Redis):缓存命中率(Hit Rate)是否过低?是否存在缓存雪崩、穿透、击穿问题?Redis本身是否存在慢命令?
-
消息队列(如Kafka):是否存在大量的消息积压(Lag)?是生产者太快,还是消费者太慢?
第五层:数据库(Database)—— 系统的“万瓶之源”
在绝大多数IO密集型的Web应用中,数据库往往是最终的性能瓶颈。
-
诊断方法:
a. 连接池:应用层的数据库连接池是否已经耗尽?
b. 慢查询日志:这是排查数据库问题的“第一神器”。开启它,所有执行时间超过阈值的SQL都会被记录下来。
c.执行计划:对找到的慢SQL,执行EXPLAIN命令。这是数据库的“自白书”,它会告诉你,为了执行这条SQL,它内部都做了些什么。
-
常见瓶颈:
-
未使用索引导致的全表扫描。
-
索引设计不当,导致索引失效。
-
不合理的JOIN操作,特别是跨越多张大表的JOIN。
-
锁竞争:大量的更新操作导致行锁或表锁的等待。
-
三、 案例实战:一场惊心动魄的“大促”故障排查
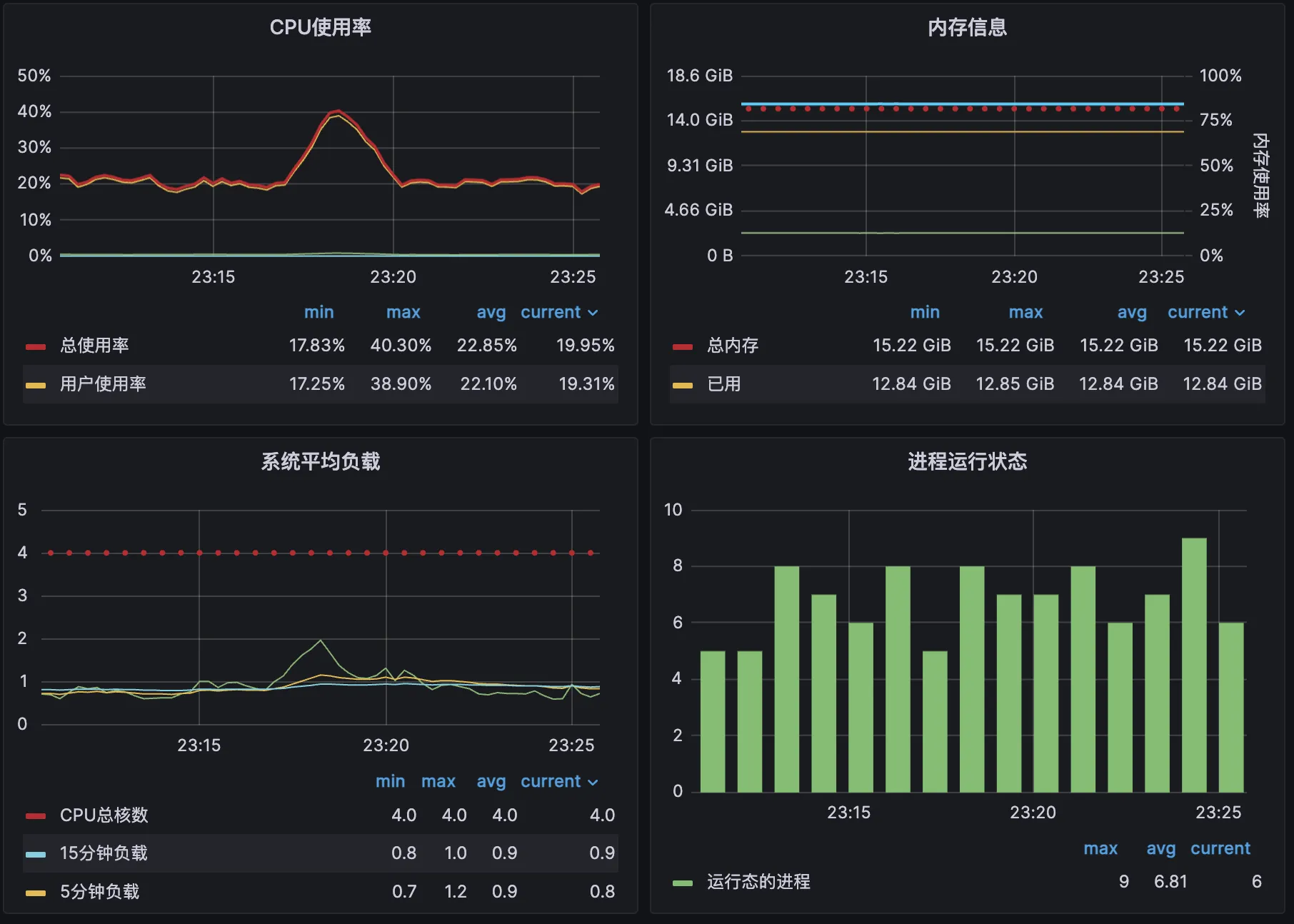
场景:双十一零点刚过,你是电商平台的核心架构师。突然,监控系统警报声四起,用户群里开始刷屏:“商品详情页打不开了!”、“加载太慢了!”。一场高压下的性能排查战开始了。
第一步:顶层分析(作战室看板)
-
你冲进“作战室”,第一眼看向大盘监控:
-
APM系统:显示
ProductDetailService的P99响应时间,从平时的80ms飙升到了8000ms!TPS从峰值的20000急剧下跌到2000。 -
用户端监控:印证了APM的数据,页面的TTFB时间极长。
-
-
初步结论:问题源头在服务端,具体就是
ProductDetailService。
第二步:应用层“CT扫描”
-
你立刻登录到一台
ProductDetailService的服务器上。 -
top命令显示,CPU使用率在70%左右,但IO等待高达40%! -
你的大脑中立刻闪过一个假设:应用不“忙”,应用在“等”! 它在等下游的IO资源。
-
为了验证是谁在等,你果断地对Java进程进行了CPU采样,并生成了火焰图。
-
火焰图的结果一目了然:在图的底部,调用栈的根部,出现了一座极其宽广的“平顶”,函数名赫然是
com.mysql.jdbc.SocketInputStream.read()。 -
精准结论:所有的应用线程,都把时间花在了等待MySQL数据库返回数据上!
第三步:直捣黄龙,聚焦数据库
-
你立刻联系DBA,此时DBA也反馈,数据库的CPU使用率已经100%,并且有大量活跃的连接。
-
DBA打开慢查询日志,瞬间被刷屏,指向了同一条SQL语句。
第四步:根因分析——罪恶的慢SQL
-
你们拿到了这条SQL,发现它是一条为了展示商品详情页而设计的复杂查询,
JOIN了商品主表、SKU表、库存表、价格表、促销活动表等6张表。 -
DBA对这条SQL执行了
EXPLAIN,真相大白:在与促销活动表进行JOIN时,由于查询条件中的一个字段activity_type没有建立索引,导致MySQL放弃了索引,对这张有数千万条记录的促销活动表,进行了全表扫描! -
在平时,数据量小,问题没有暴露。但在大促零点,海量的并发请求,每一个都要对这张千万级大表进行一次全表扫描,瞬间就将数据库的CPU和IO资源全部耗尽。
第五步:紧急止血与事后复盘
-
紧急方案:DBA以最快速度,为
促销活动表的activity_type字段加上了索引。 -
效果:索引生效的瞬间,数据库CPU使用率应声回落。APM监控上,
ProductDetailService的响应时间在几十秒内恢复到了100ms以内,一场危机解除了。 -
复盘:商品详情页这种读多写少的场景,不应该在每次请求时都进行如此复杂的实时
JOIN。后续的架构优化方案是:通过离线任务,提前将商品的所有信息预计算好,聚合到一个宽表或直接写入Elasticsearch/Redis中,将前台的读请求,从对数据库的复杂查询,转变为对缓存或文档数据库的简单查询。
结语:性能是设计出来的,不是优化出来的
今天,我们学习了一套强大的、从现象到本质的性能瓶颈定位方法论。这套方法的核心,在于它的结构化和数据驱动。它能帮助我们在混乱和高压的故障环境中,保持清晰的思路,做出最有效的决策。
请大家牢记,性能排查的过程,就是一次对系统架构的深度体检。你在排查过程中发现的每一个瓶颈,都是对你过去架构决策的一次拷问。
而一个真正卓越的架构师,不仅要擅长在事后“侦破案件”,更要在事前就“预防犯罪”。最好的性能优化,发生在编码之前。在你的每一次技术选型、每一次数据模型设计、每一次接口契约定义中,都注入对性能的敬畏和思考。因为,卓越的性能,最终是设计出来的,而不是在深夜的“作战室”里优化出来的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









