### 轻量化注意力机制概述
轻量化注意力机制是一种旨在减少计算复杂性和内存占用的同时,提升深度学习模型性能的技术。其核心理念在于通过设计高效的网络结构,在不显著增加参数量的前提下增强模型对重要特征的关注能力。
#### 1. **概念**
轻量化注意力机制的核心是引入一种高效的方式让神经网络能够自适应地关注输入数据中的关键部分。这种技术通常用于卷积神经网络(CNN)、目标检测框架以及其他视觉任务中。例如,ECA-Net 提出了基于一维卷积的通道注意力机制[^1],而 YOLOv8 和 YOLOv9 则分别采用了 MLCA 和 iRMB 来进一步优化模型效率和准确性][^[^23]。
#### 2. **实现方法**
以下是几种常见的轻量化注意力机制及其具体实现:
##### (1) ECA-Net 的实现
ECA-Net 使用了一种简单却有效的策略——通过调整核大小的一维卷积操作替代复杂的多层全连接网络来捕获通道间的依赖关系。这种方法不仅减少了计算开销,还提升了模型的表现。其实现过程如下:
```python
import torch.nn as nn
class ECALayer(nn.Module):
def __init__(self, channels, gamma=2, b=1):
super(ECALayer, self).__init__()
t = int(abs((log(channels, 2) + b) / gamma))
k_size = t if t % 2 else t + 1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
y = self.sigmoid(y)
return x * y.expand_as(x)
```
##### (2) MLCA 的实现
MLCA 是一种混合局部通道注意力机制,它结合了局部和全局特征以及通道和空间信息。它的特点是能够在极低的额外参数成本下大幅提升模型表现。其实现逻辑可以概括为以下几步:
- 计算局部区域内的平均池化;
- 对这些局部统计信息应用权重矩阵以捕捉跨通道的相关性;
- 将加权后的结果重新注入原始特征图中。
```python
import torch
import torch.nn.functional as F
def mlca_module(features, reduction_ratio=16):
batch_size, num_channels, height, width = features.size()
# 局部均值聚合
pooled_features = F.adaptive_avg_pool2d(features, output_size=(height//reduction_ratio, width//reduction_ratio))
# 扩展回原尺寸并融合
expanded_attention = F.interpolate(pooled_features, size=(height, width), mode='bilinear', align_corners=True)
# 应用激活函数与逐元素乘法
final_output = torch.sigmoid(expanded_attention) * features
return final_output
```
##### (3) iRMB 的实现
iRMB 结合了倒置残差块(IRB)和 Transformer 的动态建模能力。它通过对标准 IRB 进行改造,加入位置编码和支持长距离依赖的学习组件,使得 CNN 更好地适配于各种下游任务需求。代码片段展示了一个简化版本:
```python
from torchvision.models.mobilenet import InvertedResidual
class iRMB(InvertedResidual):
def __init__(self, inp, oup, stride, expand_ratio, use_transformer=False):
super(iRMB, self).__init__(inp, oup, stride, expand_ratio)
if use_transformer:
from transformers import ViTModel
self.transformer_layer = ViTModel.from_pretrained('vit-base-patch16-224').encoder.layer[0]
def forward(self, x):
identity = x
out = super().forward(x)
if hasattr(self, 'transformer_layer'):
B, C, H, W = out.shape
reshaped_out = out.permute(0, 2, 3, 1).reshape(B, H*W, C)
transformed_out = self.transformer_layer(reshaped_out)[0].permute(0, 2, 1).view(B, C, H, W)
out += transformed_out
return out + identity
```
#### 3. **应用场景**
轻量化注意力机制广泛应用于图像分类、物体检测、语义分割等领域,尤其是在移动设备上运行实时推理的任务中尤为重要。比如:
- 移动端应用程序:由于硬件资源有限,采用像 ECA-Net 或者 MLCA 这样的方案可以帮助开发者构建更紧凑但功能强大的 AI 模型。
- 自动驾驶汽车传感器处理:快速且精确的目标识别对于保障乘客安全至关重要;因此,使用经过优化过的算法显得尤为必要。
- 医疗影像分析:当面对海量医学图片资料时,如何平衡速度与质量成为亟待解决的问题之一,而这正是此类技术擅长之处。








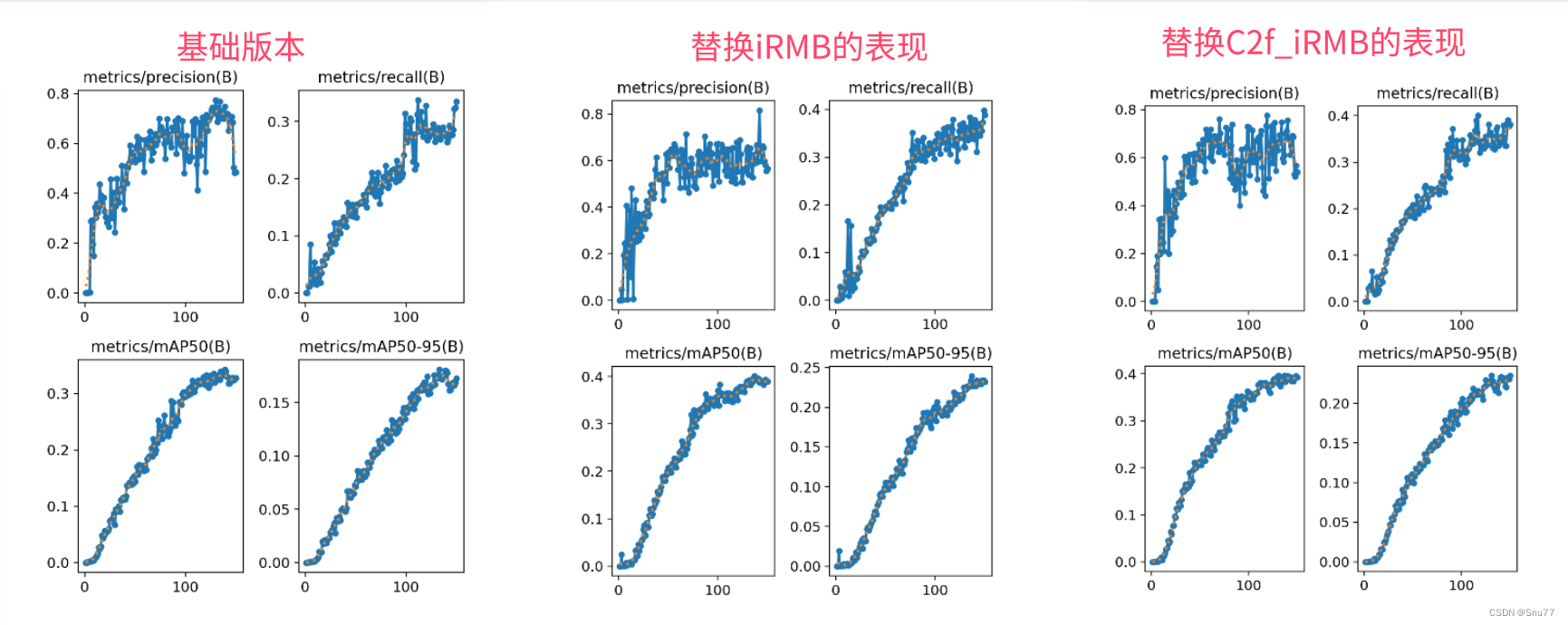
 本文详细介绍了YOLOv5改进中的iRMB(Inverted Residual Mobile Block)注意力机制,这是一种结合CNN轻量级特性和Transformer动态处理能力的结构,用于移动设备上的密集预测任务。iRMB通过倒置残差块扩展了传统CNN,增强了处理长距离信息的能力。文章包括iRMB的框架原理、核心代码、添加步骤和训练过程,旨在帮助读者理解和实现这一轻量化注意力机制。
本文详细介绍了YOLOv5改进中的iRMB(Inverted Residual Mobile Block)注意力机制,这是一种结合CNN轻量级特性和Transformer动态处理能力的结构,用于移动设备上的密集预测任务。iRMB通过倒置残差块扩展了传统CNN,增强了处理长距离信息的能力。文章包括iRMB的框架原理、核心代码、添加步骤和训练过程,旨在帮助读者理解和实现这一轻量化注意力机制。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1064
1064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











