 显著实例分割新突破
显著实例分割新突破





 介绍一种新型显著实例分割方法,不仅提供boundingbox,还能高质量分割图像中最突出目标。提出RoIMasking,结合背景信息,提升分割精度。
介绍一种新型显著实例分割方法,不仅提供boundingbox,还能高质量分割图像中最突出目标。提出RoIMasking,结合背景信息,提升分割精度。
介绍
这篇文主要讲的是显著实例分割(salient instance segmentation),输入一张图不仅能获得bounding box,还可以获得高质量的分割。显著实例分割只针对图像中最“突出”、最“感兴趣”的目标,而不是所有目标。标题的single stage是指边框回归只有一次。

上图就是本文模型的实现效果。
CNN最近几年在很多领域都取得了不错的效果,对于提取特征有着显著的成就,但是作者认为CNN无视了目标及其附近背景的重要特征分离能力,此外实例分割中的RoIPooling、RoIWarp、RoIAlign方法都有缺点。基于上述所说,作者提出了一种新的方法:RoIMasking。
主要工作分为两部分:
- 设计了一个新的端到端的单阶段显著实例分割模型
- 提出RoIMasking
这篇笔记我会把这个模型和Mask R-CNN、MaskX R-CNN对比起来看。(这两个模型的具体介绍见【论文笔记】Learning to Segment Every Thing)
相关工作
显著实例分割目前来说算是比较新的一个任务,主要与三种计算机视觉任务有关:
- 显著目标检测
- 目标检测
- 语义实例分割
相关工作是R-CNN、Fast R-CNN、Faster R-CNN、Mask R-CNN的一系列介绍,具体见上面那个网址。
这里主要讲下作者的灵感来源。
在CNN方法流行之前,在显著实例分割中常用前背景间的分离特征,不需要学习大量数据,就能很好的实现显著实例分割。如下图:

GrabCut 方法中使用前背景颜色模型,如高斯混合模型,只需要在目标附近画一个框,就可以获得很好的分割结果。可以看出例图中其实目标和背景有些颜色还特别相近,但也分割得很好。作者就想到,如果要用CNN来分割这种背景和目标有点相近的图,需要大量的训练集,并且训练集中还有很多目标和背景色调很像的图,既耗时又难以训练出好的模型。所以作者认为或许可以把目标附近的背景结合起来,扩大感受野的同时增强前后景之间的对比。
S4Net
整体的简单框架见下图:
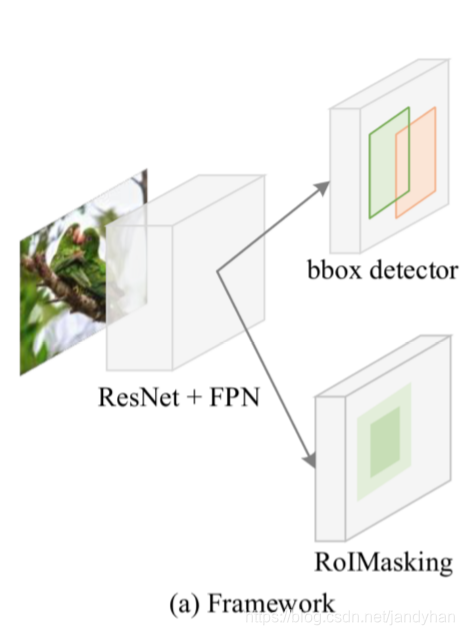
整体包含两个部分:bounding box检测器和分割部分。base模型是ResNet-50+FPN,为了减少时间,作者抛弃了conv2的连接。这里提了一句跟Faster R-CNN使用FPN差不多,也就是根据RoI的尺度来决定RoIpooling层的输入来自FPN网络的哪一层特征图,这篇文章主要是讲分割方面的创新,就不过多赘述。
分割部分有一点要注意的是RoIMasking的输入包含预测的bbox和backbone里步长为8的特征图,与Mask R-CNN不一样。具体我会在后续进行对比。
RoIMasking
RoIPooling和RoIAlign的具体实现也见上面那个链接,两者都是用来提取特征图上proposal的对应位置的,后者相比前者更精确——不进行四舍五入,后续用双线性插值法。但两者提取的区域通常都要resize成固定的大小,比如7x7/28x28,会影响最终的分类/分割效果。此外两者都局限于proposals的矩形框范围内,背景信息没有利用。于是作者就提出了RoIMasking。
Binary RoIMasking:先从最简单的二元开始,Binary RoIMasking层的输入为特征图和来自检测分支预测的proposals。然后根据矩形框的位置和大小获得一个二元mask,框内为1,框外为0。要注意的是这个框的大小是原来的proposal有多大就是多大,如下图所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2571
2571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









