




 从FCN到DeepLabV3+,回顾语义分割领域的关键进展。本文详细介绍了FCN、SegNet、Dilated convolution、U-Net、V-Net、RefineNet、PSPNet、DeepLab系列等模型,探讨了它们如何解决多尺度问题,提升分割精度。
从FCN到DeepLabV3+,回顾语义分割领域的关键进展。本文详细介绍了FCN、SegNet、Dilated convolution、U-Net、V-Net、RefineNet、PSPNet、DeepLab系列等模型,探讨了它们如何解决多尺度问题,提升分割精度。
1. FCN(2014)
论文链接:Fully Convolutional Networks for Semantic Segmentation
之前有做过笔记:语义分割的一些笔记,FCN是语义分割的基础,后续很多分割方法都是在FCN的基础上发展的。
简单总结:
- FCN把一些分类网络(如VGG)的全连接层变成全卷积层,获得低分辨率的特征图后再利用反卷积上采样到原图尺寸
- 池化能获得带有高级特征同时也会导致分辨率减小、丢失空间信息,所以FCN融合不同粗糙度的特征(笔记里有提),能细化分割结果
2. SegNet(2015)
论文链接:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
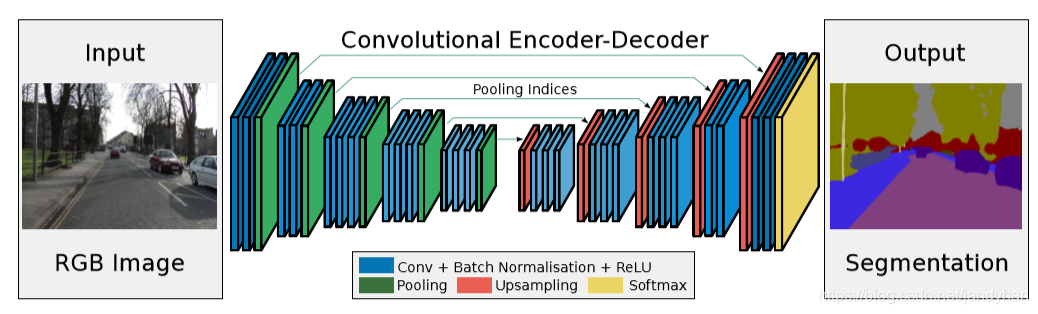
总体结构如下图,相比较FCN加了更多的跳接(FCN只有两个),并且传过去的也不是Encoder部分的特征图,而是Maxpooling层的max-pooling indices。
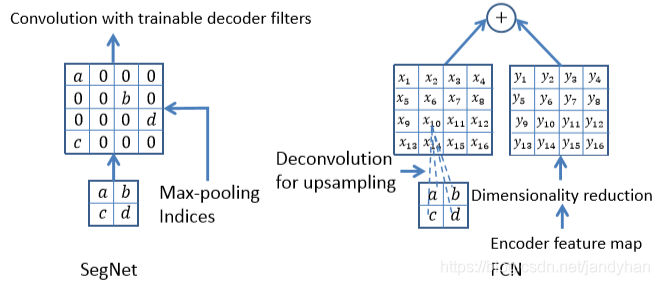
下图是SegNet和FCN在Decoder部分的区别:SegNet在上采样时用的是max-pooling indices信息,也就是在下采样阶段池化时的每个2x2 filter的索引值,上采样按照索引信息将像素放至对应位置,到这时其实不是密集分割的,因为有很多位置的像素值都是0(如左边示例),所以在上采样后还要接几个可训练的卷积层,获得密集特征图;而右边的FCN是利用反卷积上采样后与Encoder部分的特征图直接融合。
简单总结:
- 其主要贡献为不是传统的复制encoder部分的特征图,而是复制max-pooling indices来进行上采样
- 由于复制信息减少,所以效率更高
- SegNet的上采样层参数是不可学习的,Encoder部分训练后直接将indices复制到上采样部分,但后续的卷积层参数是要经过训练的
3. Dilated convolution(2015)
论文链接:Multi-Scale Context Aggregation by Dilated Convolutions
空洞卷积也是现在用的比较多的优化结构了。之前的图像分割,都是Pooling来增大感受野,同时也降低了分辨率,然后为了获得密集分割再上采样。这个过程肯定损失了信息,所以为了增大感受野的同时保证分辨率不变,提出了空洞卷积。
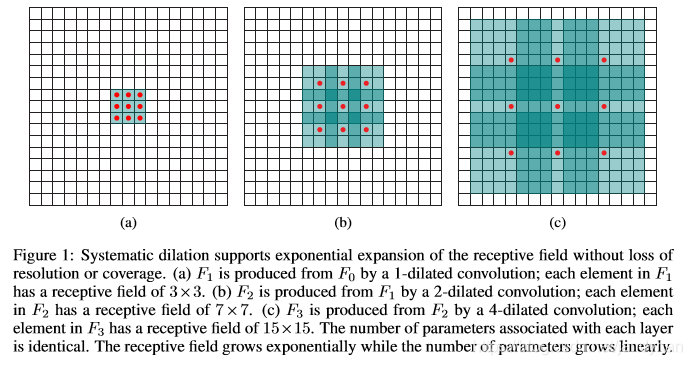
简单总结:
- 空洞率rate,看图理解的话,rate = 两个取值点中间的空格数+1
- 空洞卷积在高层使用的rate变大时,对输入的采样将变得很稀疏。比如某个像素可能一直没被计算,局部的信息丢失,信息之间太远不相关。Understanding Convolution for Semantic Segmentation里面提到了一些约束(HDC)可以解决上述问题,按照HDC能做到最后的接收野全覆盖整个区域,所有像素均被计算。
HDC的约束:
- dilation rate 不能有大于1的公约数
- 锯齿波(sawtooth wave-like)变化: 每个卷积块的扩张率逐渐增大
- 满足公式: M i = m a x [ M i + 1 − 2 r i , M i + 1 − 2 ( M i + 1 − r i ) , r i ] , M n = r n , M i < K M_i =max[M_{i+1}-2r_i,M_{i+1}-2(M_{i+1}-r_i),r_i],M_n = r_n,M_i<K Mi=max[M
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









