




 这篇ECCV2018论文提出了一种新的弱监督语义分割方法,通过S4Net提取显著实例,并利用注意力模块和语义特征提取器进行类别概率预测和特征学习。通过构建相似性图并应用图划分算法,解决了实例级别的分割问题。这种方法首次在弱监督框架中使用显著实例,简化了对象识别,并在没有像素级标签的情况下实现了实例分割。
这篇ECCV2018论文提出了一种新的弱监督语义分割方法,通过S4Net提取显著实例,并利用注意力模块和语义特征提取器进行类别概率预测和特征学习。通过构建相似性图并应用图划分算法,解决了实例级别的分割问题。这种方法首次在弱监督框架中使用显著实例,简化了对象识别,并在没有像素级标签的情况下实现了实例分割。
论文标题:Associating Inter-Image Salient Instances for Weakly Supervised Semantic Segmentation
论文来源:ECCV 2018
研究内容:使用图像标记进行弱监督语义分割
1. 弱监督语义分割存在问题及本文创新
大部分state-of-the-art方法通过利用底层的的线索检测器来从原始图像获取像素级的信息。比如,使用saliency detector[4, 20, 22, 42]或注意力模型[4, 42]。因为此类方法只能给出像素级的saliency/attention 信息,从生成的启发线索中难以区分语义对象的不同种类。因此,判别不同语义实例的能力成为必要。
一些诸如MSRNet[24]和S4Net[12]等saliency检测器不仅能给出灰度级的显著目标,也能提供实例级的mask。
所提方法包含:
- 注意力模块:基于salient instance的固有特征,预测其属于特定类别的概率
- 语义特征提取器:为每一个salient instance预测一个语义特征,共享相似语义信息的salient instance具有相近的语义特征
- 基于语义特征,构件相似性图,每一节点表示一个salient instance,边上的权重记录一对salient instance的语义相似性
- 使用图划分算法将图划分为子图,每一子图表示某一特定类别。
主要创新:
- the first use of salient instances in a weakly supervised segmentation framework, significantly simplifying object discrimination, and performing instance-level seg- mentation under weak supervision.
- a weakly supervised segmentation framework exploiting not only the information inside salient instances but also the relationships between all objects in the whole dataset.
2. Overv and Network Structure
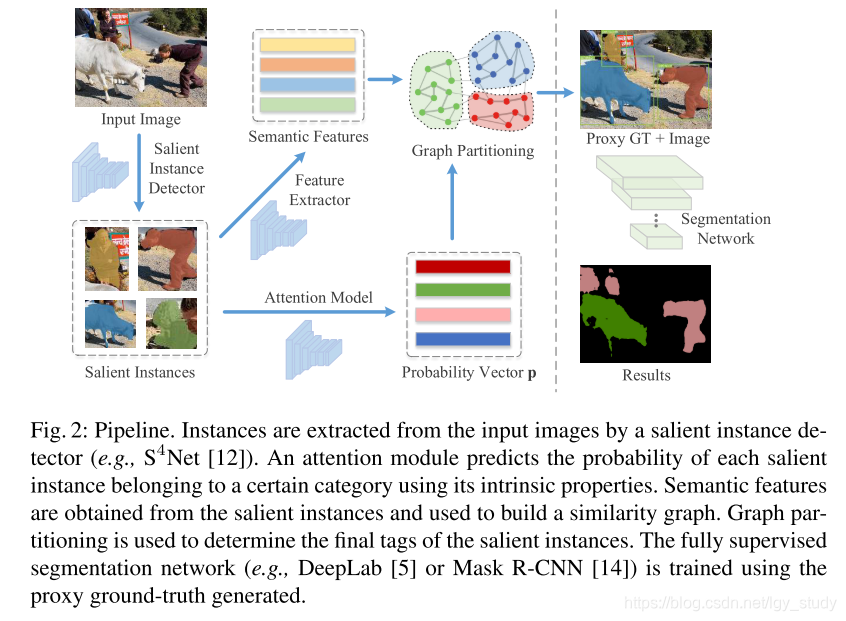
- Given training images labelled only with keywords, we use an instance-level saliency segmentation network, S4Net [12], to extract salient instances from every image. 尽管salient instance包含能用以训练segmentation mask的ground-truth mask,训练分割网络时存在两方面的限制,但可以通过解决一个tag-assignmnet问题得到解决(为每一实例关联一个存在的tag或noisy tag):
- 图像有可能包含多个关键词
- S4Net检测出来的salient instance可能不包含在训练集中的类别集合中
2.1 Attention Module
一些符号:
- C:训练集中背景除外的类别数
- I:输入图像
- Attention Module预测C个attention maps
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1842
1842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









