







Ollama是一款专注于简化大型语言模型本地部署和运行的开源框架,基于Go语言实现,支持跨平台运行,并以“开箱即用”为核心理念,适合个人开发者和轻量化场景。
而vLLM是一个高效的大模型推理与服务引擎,基于PyTorch构建,创新性地引入了PagedAttention技术,旨在解决大模型服务中的显存效率与吞吐量瓶颈,支持张量并行和流水线并行,可横向扩展至多机多卡集群。

一、Ollama
Ollama是什么?Ollama 是一个专注于本地运行大型语言模型(LLM)的工具,支持macOS/Linux/Windows,ARM架构设备友好,提供简洁的命令行接口,适合个人开发者和研究者快速体验模型。

Ollama以“开箱即用”为核心理念,专为个人开发者和轻量化场景设计。
Ollama基于Go语言实现,通过模块化封装将模型权重、依赖库和运行环境整合为统一容器。这种设计使得用户无需关注底层依赖,仅需一条命令行即可启动模型服务。
Ollama的优势在于开发友好性,但生产部署时面临性能、稳定性和运维能力的全方位挑战。对于关键业务系统,建议仅将其作为实验阶段的验证环节,而非最终部署方案。
# Linux/macOS 一键安装脚本curl -fsSL https://ollama.com/install.sh | sh# 拉取 DeepSeek-R1 模型ollama pull DeepSeek-R1# 启动 DeepSeek-R1 模型ollama run DeepSeek-R1 # 启动交互式对话# 通过 API 调用 DeepSeek-R1 模型curl http://localhost:11434/api/generate -d '{"model": "DeepSeek-R1","prompt": "为什么天空是蓝色的?"}'
二、vLLM
vLLM(Vectorized Large Language Model Serving System)是什么?vLLM 是一个高效的大模型推理与服务引擎,旨在解决大模型服务中的显存效率与吞吐量瓶颈,适合生产环境部署。
# 安装 vLLMpip install vllm # 需要 Python 3.8+ 和 CUDA 11.8+#启动 vLLM 推理服务,并使用 DeepSeek-R1 模型# 单卡启动 DeepSeek-R1python -m vLLM.entrypoints.api_server \--model deepseek/DeepSeek-R1 \--tensor-parallel-size 1# 使用 curl 命令调用 DeepSeek-R1 模型的推理服务curl http://localhost:8000/generate \-H "Content-Type: application/json" \-d '{"prompt": "解释量子纠缠", "max_tokens": 200}'
# 使用 vLLM 的 Python SDK 调用 DeepSeek-R1 模型from vllm import LLMllm = LLM("deepseek/DeepSeek-R1")outputs = llm.generate(["AI 的未来发展方向是"])print(outputs)
分页注意力机制(PagedAttention)是什么?分页注意力机制借鉴了计算机操作系统中的内存分页管理,通过动态分配和复用显存空间,显著提升大模型推理的效率和吞吐量。
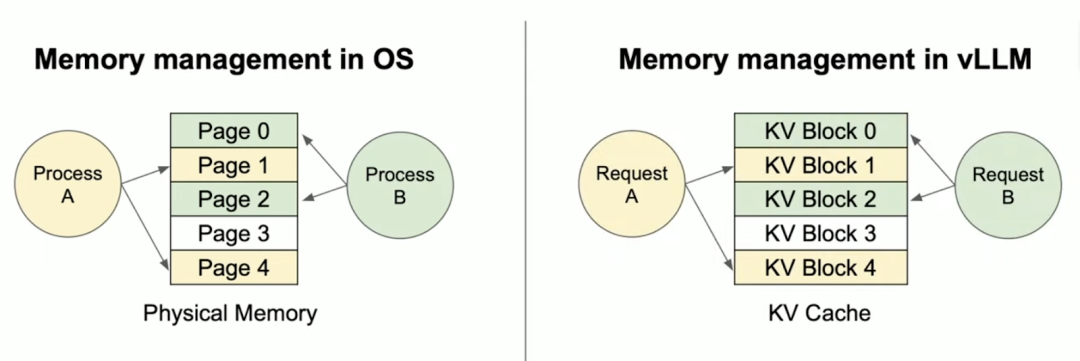
在传统的大模型推理中,注意力机制(Transformer的自注意力层)需要为每个请求的序列分配连续的显存块,存储以下数据:
(1)键值缓存(Key-Value Cache,KV Cache):存储历史token的键值对,用于生成后续token。
(2)中间激活值:计算注意力权重时的中间结果。
vLLM基于PyTorch构建,创新性地引入了PagedAttention技术。该技术借鉴操作系统的虚拟内存分页机制,将注意力键值对(KV Cache)存储在非连续显存空间,显著提高了显存利用率。
PagedAttention通过分块管理显存、动态按需分配和跨请求共享内存,解决了传统方法中显存碎片化、预留浪费和并发限制三大瓶颈。


















 219
219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











