







 超级会员免费看
超级会员免费看
 CFNet是基于SiamFC的改进版,它引入了Correlation Filter层,允许网络端到端训练。研究证明,即使减少网络的卷积层数,也能保持高精度。CF层在训练和跟踪中都展示了其价值,通过编码先验知识,提高模板的鲁棒性。然而,文中并未明确讨论如何处理缩放问题,且某些对比实验的细节未完全提供。
CFNet是基于SiamFC的改进版,它引入了Correlation Filter层,允许网络端到端训练。研究证明,即使减少网络的卷积层数,也能保持高精度。CF层在训练和跟踪中都展示了其价值,通过编码先验知识,提高模板的鲁棒性。然而,文中并未明确讨论如何处理缩放问题,且某些对比实验的细节未完全提供。
原文:https://blog.youkuaiyun.com/u014085471/article/details/78442137
End-to-end representation learning for Correlation Filter based tracking
Jack Valmadre∗ Luca Bertinetto∗ Joao F. Henriques Andrea Vedaldi Philip H. S. Torr ˜
University of Oxford
论文地址:https://arxiv.org/abs/1704.06036v1
源码地址:https://github.com/bertinetto/cfnet
概要:
作者基于SiamFC的结构上加入CF层(Correlation Filter),网络可以端到端的训练,用实验证明了这种网络结构可以用较少网络的卷积层数而不降低精度。
动机:
CF表现不错,但是引入CNN无法端到端学习。
主要工作:
1.引入CF层,并推到了前向反向传播公式。
2.做了不同的实验证明其速度精度以及CF的作用。
基础构件:
1.SiamFC(Fully-Convolutional Siamese Networks for Object Tracking),如下图,上下两个相同结构的卷积网络,对z(目标图)和x(搜索区域图)提取卷积特征,两者卷积得到得分图,最大的响应位置是物体移动的位置。 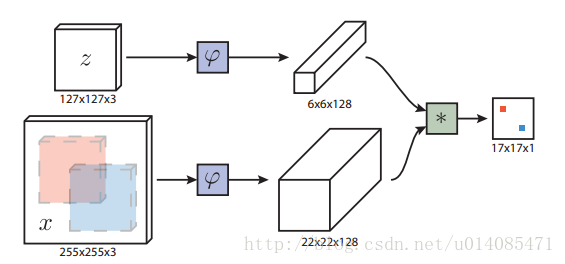
2.以前的相关滤波,如下面公式,x是一张图(可以是目标图,可以是搜索区域的图),通过高斯核变换成k,y是服从高斯分布的矩阵(中心显著),训练这么一个alphaf,对搜索图得到的K,与alphaf点乘再反傅立叶变化可以得到新的响应图,最高点为物体运动的点。这么计算的原因是信号的卷积运算在频域是点乘运算,所以通过傅立叶变换可以加快计算速度。 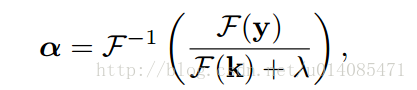
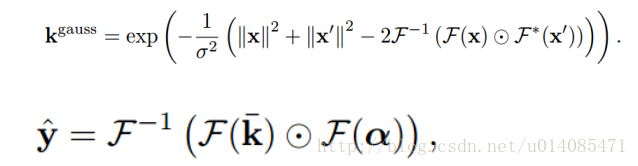
3.这里的CF层,这里没办法把SiamFC中的 * 改成上面的计算,这样没办法端到端训练。这里的CF层是这样的,对 x得到的特征,经过cf公式变换,公式有所改动。 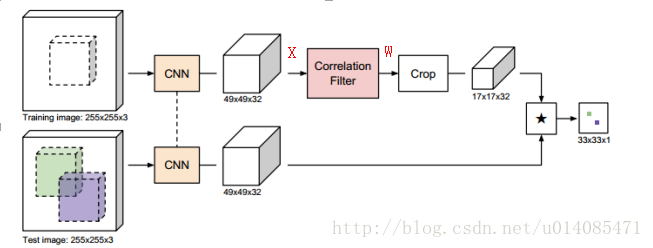
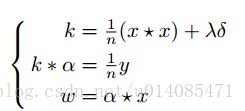
4.训练上的改变
原来: 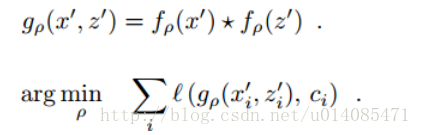
现在: 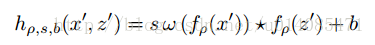
其他细节:
1.跟踪的时候,exemplar缩放比例是1.04,产生三个不同尺寸的图再经过CNN,三个不同的得分最大的那个是最佳的尺度变化
2.训练的时候还是用Logistic Loss
3.CF中的y一开始是高斯分布的响应,后面可以被训练,并没有发现被训练后的y有什么特别的好。
实验:
1.不同深度直接的对比 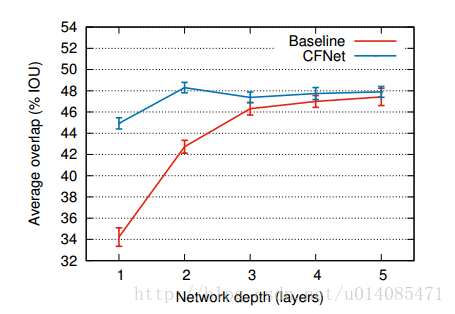
2.融合实验,为了证明假说:CF在训练中就融入会比跟踪时融入好(The motivation for this work was the hypothesis that incorporating the CF during training will result in features that
are better suited to tracking with a CF. ) 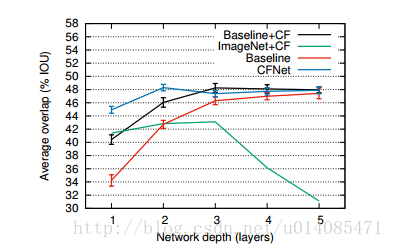
3.自适应实验,给了一个不变的CF层验证跟踪时候更新CF参数的必要 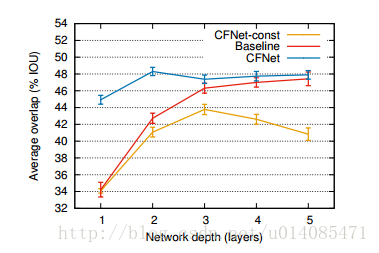
4.效果上,虽然效果不错,但是总觉得作者在刻意隐瞒什么,比如Baseline-conv3的结果没在这里写出来(速度精度可能高于CFNet-conv1),再比如SiamFC-3s在原论文里fps达到86(https://arxiv.org/abs/1606.09549)。 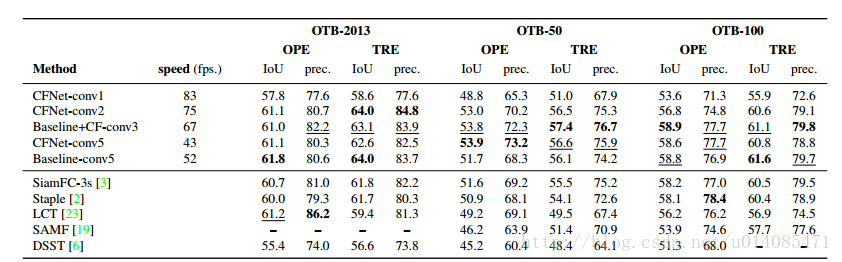
疑问:
1.实验中其他模型数据问题
2.CF层的作用?
可以将x制作成一个对变化有鲁班性的区别模板
Its effect can be understood as crafting a discriminative template that is robust against translations.
可以理解为对测试时的先验知识编码,当获得足够的数据和容量时,这个先验知识变得冗余甚至是过度限制。
The CF layer can be understood to encode prior knowledge of the test-time procedure. This prior may become redundant or even overly restrictive when enough model capacity and data are available.
3.训练时的怎么解决缩放问题(还得细看代码)

















 725
725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









