




 本文深入探讨了高维数据的挑战,特别是维数膨胀带来的问题,并介绍了如何使用Lasso和前向逐步回归法进行数据降维。通过实例解释了在高维空间中样本密度降低的现象,以及这对预测准确性的影响。文章还提供了前向逐步回归法的Python代码实现。
本文深入探讨了高维数据的挑战,特别是维数膨胀带来的问题,并介绍了如何使用Lasso和前向逐步回归法进行数据降维。通过实例解释了在高维空间中样本密度降低的现象,以及这对预测准确性的影响。文章还提供了前向逐步回归法的Python代码实现。
机器学习之线性回归缩减维度
什么叫高维数据?
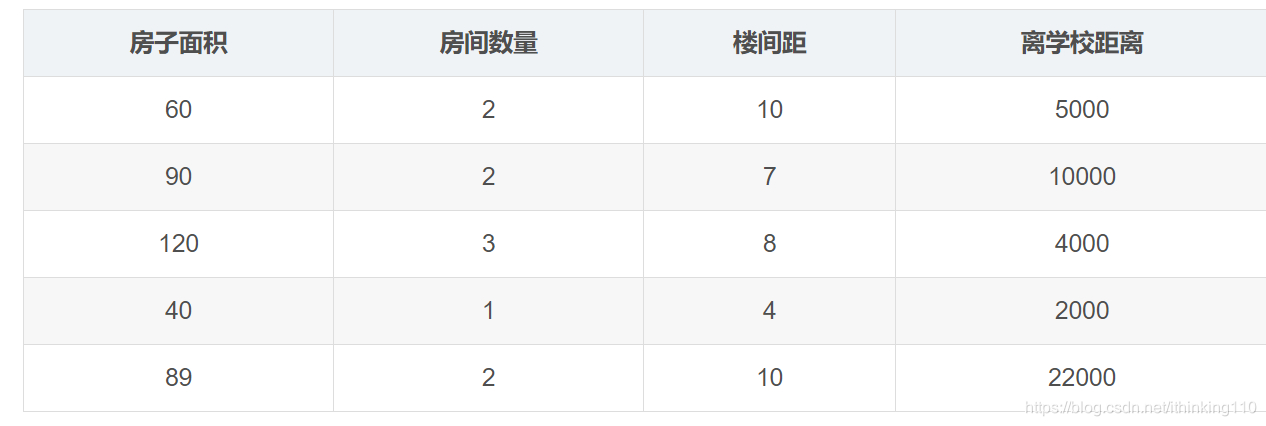
如上图 前面 我们求解线性回归的时候 列举的一个例子。
这个例子中:
房子的面积, 房间的数量 , 楼间距, 离学校的距离 我们的数据 从这四个维度取例 ,也称为数据的维度 用d表示。
下面的每一行 表示一个 房子的样本 。 样本可以有N 多个。
维数膨胀
当我们数据的维度 大于 样本的数量的时候 我们称为 维数膨胀
在分析高维数据过程中碰到最大的问题就是维数的膨胀,也就是通常所说的“维数灾难”问题。研究表明,随着维数的增长,分析所需的空间样本数会呈指数增长
如下所示,当数据空间维度由1增加为3,最明显的变化是其所需样本增加;换言之,当样本量确定时,样本密度将会降低,从而样本呈稀疏状态。假设样本量n=12,单个维度宽度为3,那在一维空间下,样本密度为12/3=4,在二维空间下,样本分布空间大小为3*3,则样本密度为12/9=1.33,在三维空间下样本密度为12/27=0.44。
设想一下,当数据空间为更高维时,X=[x1x1,x2x2,….,xnxn]会怎么样?
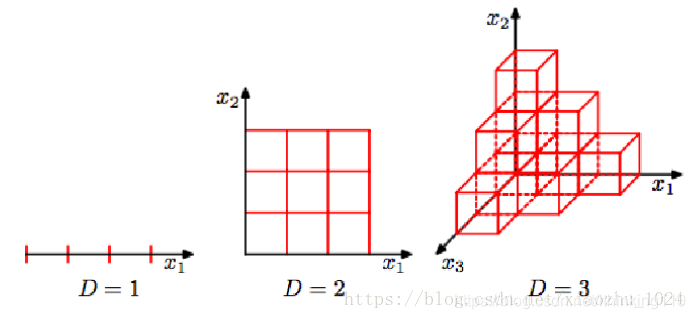
1,需要更多的样本,样本随着数据维度的增加呈指数型增长;
2,数据变得更稀疏,导致数据灾难;
3,在高维数据空间,预测将变得不再容易;
4, 导致模型过拟合。
数据降维
对于高维数据,维数灾难所带来的过拟合问题,其解决思路是:
1)增加样本量;
2)减少样本特征
而对于现实情况,会存在所能获取到的样本数据量有限的情况,甚至远小于数据维度,即:d>>n。如证券市场交易数据、多媒体图形图像视频数据、航天航空采集数据、生物特征数据等。
常见的降维方法: lasso ,前向逐步回归法,LAR,PCA 等。
这里我们先学习 两种 lasso ,前向逐步回归法。
Lasso
这篇文章详细介绍了 岭回归
我们得出如下公式:
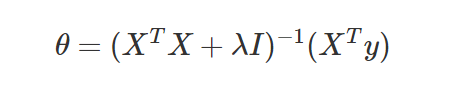
这个lamda 帮我们解决了 不是满秩矩阵的问题。 但是 其中这个lamda 该取多少值呢 ?
因为 lamda 这个 因子的不确定性 所以得到权重也不太一样 。
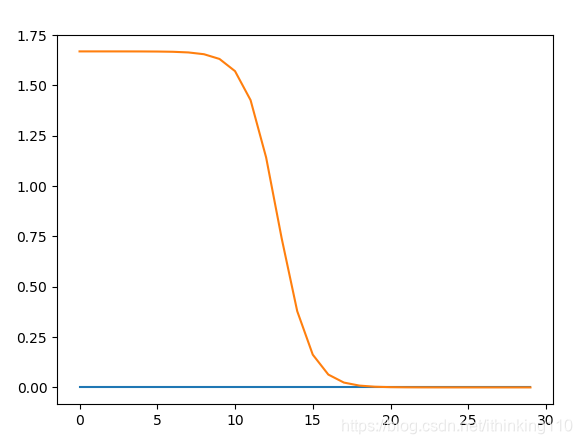
从这个图中 我们可以发现 随着 lamda 逐渐变大 ,权重中的 二维权重(x,y) y 值逐渐接近为 0 。
g(z)= w0x0 + 0x1那么我们调节 lamda值 就可以 减少 一个维度的数据 。 所以岭回归 不断可以解决 满秩矩阵的问题 ,还可以缩减 维度问题。
lasso 就是 对 上述的 权重 和 lamda 在做一个限制 。
n
Σ | Wk| ≤ λ
k=1
在λ 足够小的时候 , 一些系数会因此被迫缩减到 0 。 这样就可以减少 若干系数。
前向逐步回归法
前向逐步回归法 可以得到 跟lasso 差不多的效果。但是更加简单。 它属于 贪心算法 。
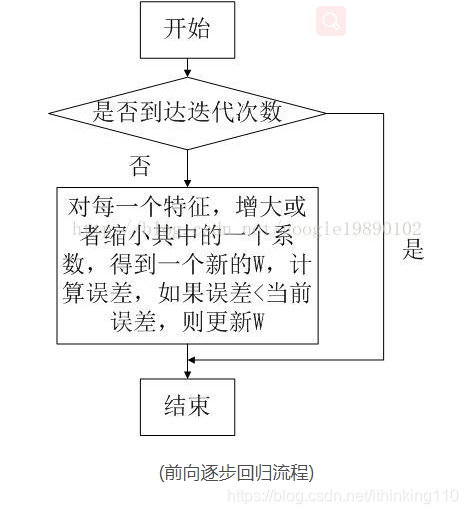
上图中的 增大 或者减少 这样操作 。 比如 g(z) = w0* X0 +w1 * X1
让W0 += 0.1 或者 W0 += -0.1 比较 哪个误差更小 。 谁小 就取哪个 。 就跟盲人探路 是一回事。 盲人没走一步 就探测一下 前面有坑没有 没有就往前走 ,否则就往后退 。
前向逐步回归法代码实现
#coding=utf-8
from numpy import *
import numpy as np
import matplotlib.pyplot as plt
filename='./ex1.txt' #文件目录
def loaddataSet(filename):
numfeat = len(open(filename).readline().split('\t'))-1
dataMat = [];labelsVec = []
file = open(filename)
for line in file.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numfeat):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelsVec.append(float(curLine[-1]))
return dataMat,labelsVec
def rssError(yArr,yHatArr): #yArr and yHatArr both need to be arrays
return ((yArr-yHatArr)**2).sum()
def stageWise(xArr,yArr,eps=0.01,numIt=10):
xMat = mat(xArr); yMat=mat(yArr).T
yMean = mean(yMat,0)
#yMat = yMat - yMean #can also regularize ys but will get smaller coef
#xMat = regularize(xMat)
m,n=shape(xMat)
returnMat = zeros((numIt,n)) #testing code remove
ws = zeros((n,1)); wsTest = ws.copy(); wsMax = ws.copy()
print("wsTest==",wsTest)
for i in range(numIt):
print( ws.T)
lowestError = inf;
for j in range(n):
# 来回试探 看看 哪个适合
for sign in [-1,1]:
wsTest = ws.copy()
print("wsTest[j]",wsTest[j])
wsTest[j] += eps*sign
yTest = xMat*wsTest
rssE = rssError(yMat.A,yTest.A)
if rssE < lowestError:
lowestError = rssE
wsMax = wsTest
ws = wsMax.copy()
returnMat[i,:]=ws.T
return returnMat
def PlotLine(X,wMat):
fig = plt.figure()
ax = fig.add_subplot(111)
#number = 20
ax.plot(wMat)
print("X",X)
#ax.plot(mat(X).T[:,1],wMat.T[:,1])
plt.show()
def TestStage():
x,y= loaddataSet(filename)
wMat=stageWise(x,y)
PlotLine(x,wMat)
TestStage()
前向逐步回归法 缩减参数
很多同学估计跟我一样 算法看明白了 但是 这个怎么就缩减参数了呢? 非常感谢 我的老朋友唐国斌 给了我很大的启发 。
比如特征值有10个, w就有10个 ,逐步向前回归就是直接把10个特征值,减少成9个 w也变成9个 然后看减少后,比减少前是否好,如果好了,就减少,一个个特征值去试,看看直接删除这个特征值,会不会让模型变得更好,有些特征值,删除反而比保留好,这个是因为这些值可能和其他几个特征值 差不多 就是信息冗余了
参考文献
https://blog.youkuaiyun.com/xiaozhu_1024/article/details/80585151
再次 感谢 老朋友 唐国斌

















 2280
2280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









