






引言
前面给大家初步讲解了 什么叫做 机器学习,大家不要被这个名字 迷惑了,我觉得找规律或者说映射 更能让人接受一些 ,机器学习有点抽象 也有点吓人。现在的机器没有逻辑推理能力只能去做一些 有规律或者重复脑动力的 这样的活。没有规律需要思考 联想的机器暂时还办不到 。以后说不定可以办到 ,所以我们用找规律这个词 让初学者更容易接受一些,入门了 我们在叫他机器学习,其实就是用一些算法 区别一下数据 。以后来了新数据 也按照之前的数据 经验去推测 现在的数据 得出 是什么一个分类 或者 符合一些规律的数据来。
机器学习 分类
监督学习
初中 就学过公式
y = a x + b 其中 a 和 b 是参数 x 为 自变量 y 为因变量
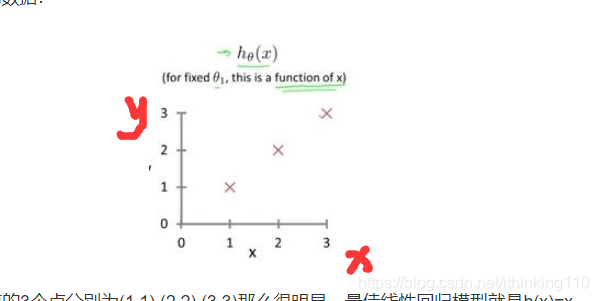
这里面 x 是 数据的值 y 是 自变量这些值的结果 。 只有 a 和 b 不确定 所以让机器去学习这些数据 得出 适当的 a 和 b 机器学习就是求这些参数的过程。
当然 我们这里只是假设了 一个自变量 x 其实有很多 自变量
y = ax1 + bx2 + cx3 + d 这样的 就有三个 自变量 x1 x2 x3 .
比如 影响房价预测: 三个自变量x1 x2 x3 一个因变量 y
1,地段 2,学区 3,楼龄 结论y
好 好 5 年 == 结论: 好
差 差 15 年 == 结论: 差
差 好 6 年 == 结论: 好
那么现在来了一个新的数据
1,地段差 2,学区差 3,楼龄 20 大致根据上面的数据 就能推测出 y 是差 。
经常 y 就称为 标签 也叫结论
数据中 有 自变量 x 和 因变量 y 用这样的数据去学习 就称为 有监督学习
无监督学习
理解了 有监督学习 很快就能理解 无监督学习 。 其实就是 没有 y 这个 因变量 让我们自动的找到 这堆数的分类 。
比如下图 黑色的点 表示数据 坐标的位置 我们根据位置的不同 可以发现这这些数据虽然只有 x 自变量 但是我们根据 这些坐标 很显然 能将数据分成 4类 。 我们不知道这4类数据的y 值代表什么意思 。 但是能分类出来。
那么来了一个 新数据 红色的点的位置 我们改归为哪一类呢 ? 明显属于 左下角那一堆数据 因为离他最近 。 所以这个分类过程 就叫 无监督学习
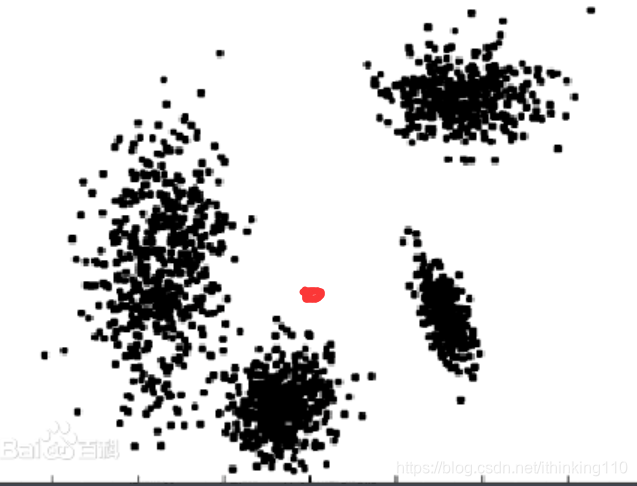
机器学习根据任务划分
分类
将数据按照 一定的规则 划分成不同的群体 。
比如上图 无监督学习 就是将 数据划分成了 4个群体 。
回归
比如上图中 数据 有一定的 规则走势 。
y = ax +b 根据历史数据求解出 a 和b 来了新数据 x 也能按照这个公式 预测出 新的值 y
在比如 天猫销售数据:
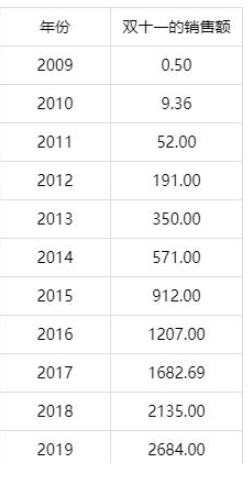
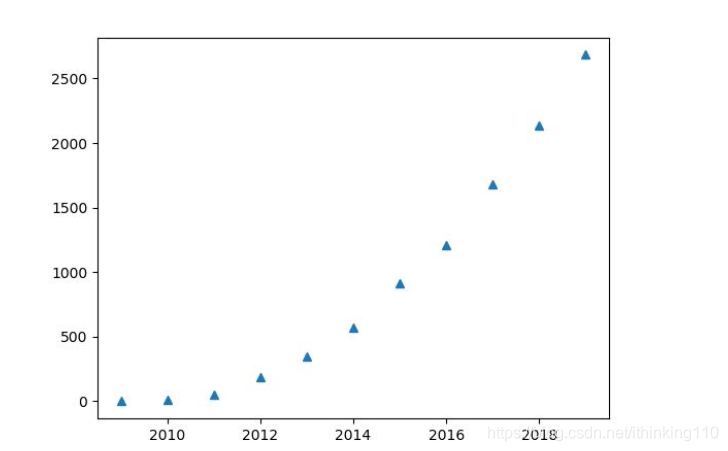
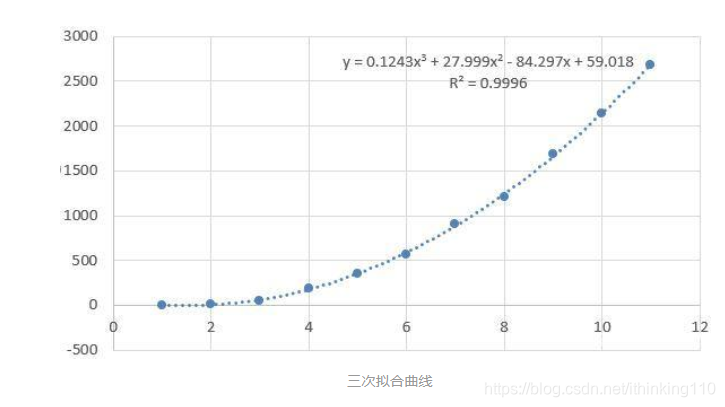
根据历史数据 可以求解出
a =00.124 b= 27.999 c= 84.297 d= 59.081 求解出 四个参数
得到公式 y= 0.124x ^3 + 27.999 x^2 - 84.297x + 59.081
按照这个规律 其实就可以预测 明年 双 11的销售额度。
还有不明白的 可以交流:
群群nub:八七四一三九四三六

















 1278
1278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









