



主动式云原生机器学习服务的容器自动伸缩
摘要
了解日益增长的机器学习工作负载的资源使用行为,对提供机器学习(ML)服务的云服务商至关重要。能够为客户工作负载自动扩展资源,可显著提高资源利用率,从而大幅降低成本。本文利用AI4DL框架[1]来表征工作负载并发现资源消耗阶段。我们将现有技术推进为一种增量式阶段发现方法,适用于更广泛的训练与推理机器学习工作负载类型。我们采用时间窗口多层感知机(MLP)来预测不同类型工作负载容器中的阶段。随后,提出一种预测性垂直自动扩展策略,根据阶段预测动态调整容器大小。我们在561个长期运行的容器上评估了该预测性自动伸缩策略,这些容器承载了多种类型的机器学习工作负载。相比开发者设定的默认资源配置策略,该预测性策略最多可减少38%的分配CPU资源。通过将我们的预测性策略与常用的反应式自动伸缩策略进行比较,发现该策略能准确预测突发阶段转换(F1分数达到0.92),并显著减少内存溢出错误的数量(350次 vs. 20次)。此外,我们还表明,预测性自动伸缩策略使扩容操作次数接近最优的反应式策略水平。
关键词 —云原生;机器学习服务;容器;自动伸缩;
一、引言
容器提供了轻量级、快速且隔离的基础设施来运行应用程序。基于容器的环境,即云原生环境,正成为在云端部署服务的事实标准,尤其是对于云机器学习服务 [2],[3],[4]。在管理资源时,机器学习服务需要特别关注,因为它们的资源使用行为与传统的长期运行服务(如Web服务或数据库)有显著差异。当机器学习工作负载被容器化后,多个运行不同任务(训练或推理)的容器可以共置于同一台机器上,并交替执行数据获取和数据处理步骤,其资源使用呈动态变化。另一方面,容器编排系统(如Kubernetes)要求开发者为容器声明固定的资源大小以运行这些任务。因此,开发者往往倾向于为每个容器过度分配资源,导致集群的资源利用率非常低。自动伸缩
根据实际使用情况垂直扩展容器可以提高资源效率。然而,在使用量突然增加的情况下,可能会导致内存不足(OOM)终止或服务质量(QoS)下降。
垂直方向上的容器自动伸缩需要理解资源使用的动态特性。对于不同类型的工作负载,不存在通用的启发式方法。机器学习工作负载通常包括从数据加载到计算的任务,其内存和CPU使用率会出现随机峰值,这些峰值无法通过经典时间序列算法捕捉。这些行为的变化可能突然、复杂,并且在不同容器之间不断变化。研究运行不同模型和任务的多个容器之间的相变有助于总体了解机器学习工作负载中各阶段的转换规律;然而,传统的时间序列预测方法无法实现这一目标。容器自动伸缩本身并非易事。严格的自动伸缩会导致更频繁的扩容操作,而宽松的自动伸缩虽然减少了扩容操作次数,但会导致资源过度分配。反应式方法[5],[6],通常只能响应渐进式变化,往往无法预见突发的行为变化。
在本文中,我们采用CRBMs和聚类技术在[1]中发现阶段,并通过增量机制进行扩展,以适用于更多类型的工作负载,例如语音识别服务、机器学习训练和推理服务。我们提出使用多层感知机(MLPs)来学习从运行不同类型工作负载的多个容器中发现的阶段序列,以预测突然的行为变化。给定对阶段的预测后,我们应用主动策略,根据阶段预测自动调整容器大小。为了减少不必要的调整大小操作次数,仅当预测到显著的行为变化时,我们才对容器进行扩容。
总结来说,我们发现基于CRBM的工作负载特征描述适用于建模阶段行为,包括突发峰值或随机突发性。所提出的迭代方法能够对新型工作负载增量式地发现新阶段。我们还发现相变存在共同模式。多层感知机模型和LSTM模型均能较好地预测典型相变。多层感知机模型在一步预测中的F1分数为0.93,在四步预测中为0.79。与反应式自动伸缩相比,
II. 相关工作
在工作负载特征描述方面,已解决了多种挑战,包括自适应模型选择[7]和自适应时间窗口选择[8]。[9]专注于对工作负载进行建模以发现模式并分类应用程序,从而能够共置异构工作负载以实现更高的资源利用率。[10]首次使用条件受限玻尔兹曼机(CRBM)和隐马尔可夫模型以无监督方式发现Spark应用的配置文件。[1]进一步应用CRBM方法和聚类方法来识别容器化深度学习(DL)训练工作负载在资源使用上的阶段。然而,他们并未充分利用动态资源分配中的可预测性。
工作负载预测是一个已知的挑战。[11],[12],[13]依赖于这种假设来解决云服务和应用的资源管理问题。它们主要基于查询或客户端的到达情况,使用回归[12],、自回归滑动平均模型(ARMA)[13],和自回归积分滑动平均模型(ARIMA)[11]等预测器来预测资源利用率。这些模型以捕捉时间依赖结构(如趋势和季节性)而闻名。然而,当资源使用包含行为不规则且阶段间发生突然转换的情况时,这些模型容易失效。最近的一些研究[14]采用更先进的模型,即多种机器学习模型的集成模型,基于作业到达和监控的历史作业运行来预测未来的资源利用率。然而,这些方法无法应用于容器的垂直自动扩展,因为每个容器仅运行单个作业。
资源自动扩展多年来一直是活跃的研究领域。许多研究[15],[16],[17]集中于水平自动扩展,即在负载波动时自动调整特定应用程序的实例(容器或虚拟机)数量。少数研究则关注垂直自动扩展[18]。通常有两种方法:反应式和主动自动扩展。反应式方法通常根据资源使用的实时变化来调整容器的大小,例如Kubernetes垂直Pod自动扩缩器(VPA)[6]和[19]。Google的Autopilot系统[5]采用先进的强化学习方法,优化常见启发式方法,以减少过度配置冗余和内存不足事件。然而,当工作负载行为突然变化时,反应式策略在容器扩容上总会存在延迟。主动自动扩展[20]致力于开发良好的预测模型,基于对未来资源使用的预测来调整实例大小。然而,这些预测模型很难捕捉到机器学习工作负载中常见的突发性行为变化。
III. 方法论
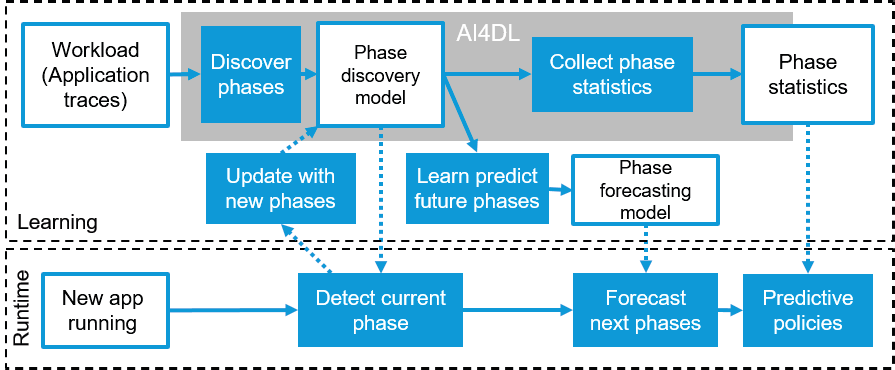
所提出的方法论扩展并实践了AI4DL [1]中描述的用于行为发现与分类的性能分析机制。AI4DL 1) 监控在生产系统中需要配置的主要容器资源(即CPU和内存消耗,以及可能的GPU和I/O),2) 对这些指标进行编码以捕捉随时间变化的动态特性(行为),3) 根据相似性对这些行为进行分类,4) 将整个正在进行的执行简化为一系列“行为阶段”,每个阶段具有独特的资源消耗特征。在本研究中,我们从正在进行的执行中预测阶段的未来转换,以推进该性能分析信息的应用,并预先配置容器。
A. 系统设计概述
图1展示了我们的主动容器自动扩展系统。AI4DL框架[1]收集工作负载轨迹以学习阶段发现模型,并在此基础上扩展了增量式阶段发现方法,以适应更多类型的工作负载。每个容器的资源消耗被建模为一系列阶段,每个阶段具有其统计特征(例如,最大值、平均值、标准差)。基于阶段序列训练阶段预测模型,用于预测运行中容器的未来阶段。一旦进入生产环境,新应用将通过阶段发现模型分析其当前行为并预测下一阶段。根据对下一个执行区间的预测,主动策略可依据预测的阶段特征决定如何调整容器大小。
B. 增量阶段发现
阶段发现过程包括以下三个主要元素:
轨迹编码 :来自容器的遥测数据通过条件受限玻尔兹曼机(CRBM)[21],进行编码,该模型能够将多维时间序列编码为特征向量,相似的输入产生相似的编码。CRBM接收一个时间窗口内的指标,即在时间点 t的CPU和内存使用情况,以及历史数据t − 1… t − d,其中 d是CRBM的超参数(时间窗口大小)。输出是一个大小为 h的向量,嵌入了整个时间窗口的轨迹,捕捉其动态特性behavior或给定时间窗口t… t − d的资源使用
阶段识别 :由于CRBM生成的编码向量具有“相似性”特性,因此使用基于邻近性的聚类方法(如 k‐means)对相似行为进行聚类,每个聚类具有相似的资源使用配置文件。聚类数量 k可以在聚类训练过程中通过经典方法确定(例如,观察簇内平方和(SSW)[10]),或采用增量式方式确定。
统计分析 :通过将实时容器指标传递给编码与聚类模块,我们可以在每个时间步识别当前执行阶段。对于发现的每个阶段,我们保留其分析统计信息,以向资源分配策略提供信息。
从初始工作负载集中,我们可以发现它们的阶段和阶段特征。然而,当来自不同类型应用的新容器到达时,系统会引入新的行为。当被分类到特定阶段的行为与通常中心差异较大时,我们应将其视为一个新阶段。实验观察表明,当新应用表现出无法识别的行为时,CRBM不需要重新训练,但聚类方法需要。此外,我们可以为该应用创建一个新的聚类模型,或者拆分发散簇并将新中心添加到阶段识别模型中。
C. 阶段预测
如在AI4DL [1],中先前所见,检测运行中的容器的当前阶段可以比从先前观察的时间窗口获取的数据提供更准确的资源使用估算。然而,如果能够进行阶段预测,则预测下一阶段应能取得更好的效果。我们提出使用带时间窗口的多层感知机(MLP)来预测给定运行中执行的下一阶段序列。在与其它预测器(如长短期记忆网络(LSTM))进行比较时,我们在基准测试执行中观察到类似的性能表现。我们还研究了朴素预测规则和更简单的预测器,它们相对于多层感知机和LSTM具有较低准确性。
给定在时间窗口(t − d… t)内从运行中的容器中发现的阶段序列,我们使用多层感知机生成(t+ 1… t+ n)。我们利用每个预测阶段的统计信息,并根据观察到的最大资源使用情况决定调整容器大小。该预测模型是在一组来自已完成容器的阶段序列上进行训练的。所有阶段均采用相同间隔,即15秒,以生成阶段ID。阶段预测任务被建模为一个分类问题。该分类器以时间段内的阶段值作为输入,输出接下来 n个时间点的阶段ID。
D. 容器自动伸缩策略
在将我们的阶段检测和阶段预测应用于容器自动伸缩时,我们探索了两种不同类型的自动伸缩策略:被动策略(例如在 [5],[1] 中使用的)和主动策略(基于预测的策略)。
被动策略 :此类策略根据过去观察到的信息调整容器大小。我们基于时间窗口统计评估两种策略。第一种策略根据上一个时间窗口的资源需求的前 95th百分位数做出调整决策。第二种策略基于时间窗口内阶段配置文件中资源需求的95th百分位数做出调整决策。
主动策略 :此类策略通过预测资源使用来分配资源,即预测接下来的多个阶段,并利用这些阶段的特征主动调整容器大小。当主动策略决定如何配置资源时,会考虑“下一个窗口”的预测结果。我们的策略会选择未来窗口内候选特征中的最大值。预测窗口大小成为一个需要研究的超参数。
最后,我们需要决定预测和调整容器大小的频率。有两种策略可供选择:1)我们周期性地调整容器大小(例如,每隔 N分钟),或 2)仅在必要时触发调整大小(例如,需要更多资源时)。在IBM云服务中,指标可以每15秒收集一次作为一个“步长”,在此期间可检测到阶段(即,使用 d= 3,CRBM +聚类可以通过4个步长的时间窗口 = 1分钟来检测阶段)。在AI4DL中,根据其系统要求,每10分钟应用一次周期性的扩容操作策略;而在 AutoPilot中,只有当资源使用与限制之间的差异超出容差时才会触发调整大小,以防止频繁且不必要的扩容操作。
这里我们应用一种自动伸缩策略,该策略在每个时间步:1)预测下一个时间窗口(1分钟)内的阶段,2)从所有预测的阶段配置文件中获取所需的CPU和内存资源,3)根据所有预测的阶段配置文件确定最大资源需求(并考虑上述百分位规则)。如果预测的资源需求表明增长超过给定容差(即当前需求的10%),则使用预测的资源对容器进行扩容。当预测的资源表明需求低于当前限制时,我们以更大的容差对容器进行缩容,以避免因轻微的使用波动导致频繁的扩缩容操作。
第四节 实验
A. 增量阶段发现
首先,我们通过将基于DLaaS工作负载训练的阶段模型应用于提供IBM Watson ML服务的集群中的VR工作负载,来评估增量式阶段发现的迭代方法。我们使用来自 DLaaS的5000个容器轨迹进行训练,500个用于验证,并使用来自VR的50个轨迹(×100比DLaaS轨迹更长)进行测试,以评估模型泛化和增量更新。
CRBM由输入数量和隐含单元数量定义。该模型使用梯度下降算法进行指定训练轮数的训练。我们采用数据重构的误差平方和作为损失来停止学习。设 d为滑动窗口大小, t为滑动窗口所处的时间点(t − d,…, t)。在探索CRBM的损失后,我们将最优延迟设为 d= 3。因此,如果我们在集群中的采样周期为15秒,则用于发现阶段的时间窗口为一分钟(包含15秒+ 3 ∗ 15= 45秒的历史数据)。通过调整超参数,我们发现当学习率为lr= 10−3、训练轮数为2000轮、隐含单元为10个时,损失最小。为了找出不同的阶段,我们使用k均值方法,该方法已被证明效果与其他复杂方法相当。k均值仅需调整集群数量 k,该值通过研究簇内平方和(SSW) [22]确定。在我们的数据中,大部分SSW可由 k= 5解释。
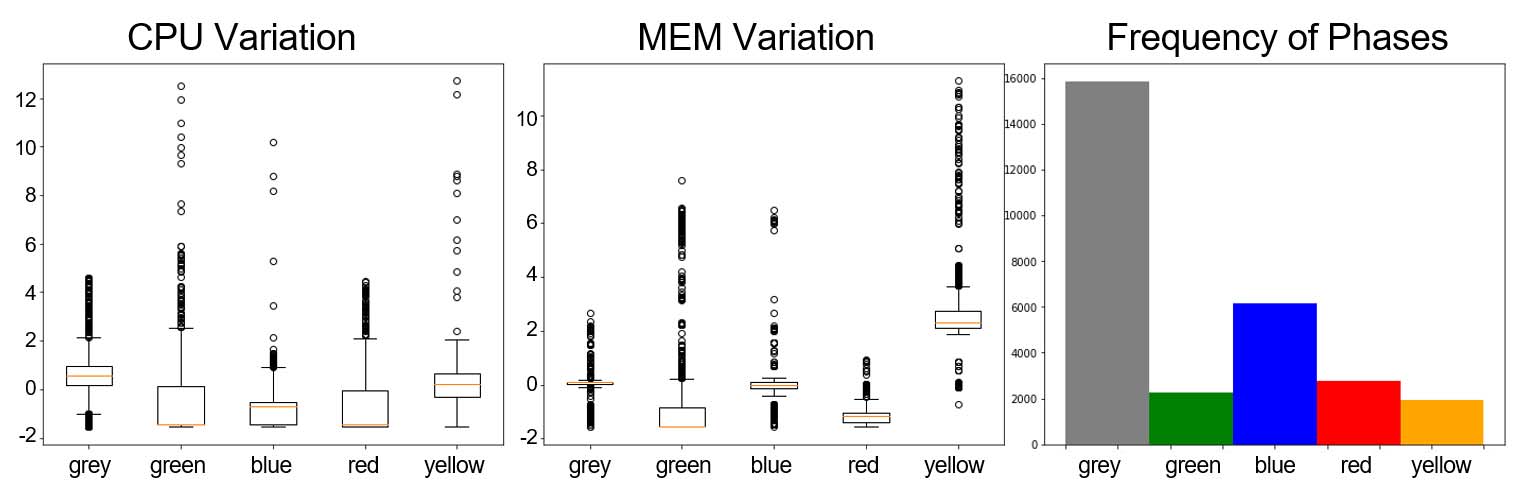
图2展示了DLaaS工作负载和VR工作负载的阶段发现与检测结果。我们首先仅使用DLaaS容器轨迹训练模型,然后增量式地更新模型,并从VR轨迹中迭代发现新阶段。我们观察到,对于DLaaS工作负载(子图2a),最常见的行为(灰色阶段)具有高且稳定的CPU消耗以及稳定的内存使用,而其他阶段则表现出内存的大幅波动(黄色阶段)、CPU/内存峰值(蓝色阶段)或低 CPU/内存使用率(红色阶段)。在图2b中,我们展示了在DLaaS工作负载上训练的默认模型在VR工作负载上的表现。我们发现,最常见的行为是黄色阶段,其资源使用行为的方差极高,表明该阶段可能包含与 DLaaS工作负载中学到的行为不同的异常行为。当通过迭代分割k均值模型中的黄色阶段(使用相同的SSW过程为聚类细分寻找合适的新 k)来更新模型时,我们观察到为VR工作负载发现了新的一组阶段,并作为新中心添加到现有模型中。
B. 阶段预测的验证
主动自动扩展管道的一个关键部分是预测未来资源需求,我们将这些需求编码为阶段。我们测试了不同的模型来预测1分钟时间窗口(4个时间步)内的下一阶段,包括:1)将最常观察到的阶段作为下一个时间窗口的预期阶段;2)将最近观察到的阶段作为下一个时间窗口的预期阶段;3)使用多层感知机预测下一个时间窗口;以及4)使用LSTM神经网络。表I显示了不同方法之间的比较。注意,随着步长数量的增加,F1分数性能会下降。我们观察到多层感知机和LSTM均能给出最佳结果,但我们将采用多层感知机,因为它更简单且更快。
| 步长 | 最近窗口模式估计器 | 最近观测阶段估计器 | 独热编码MLP | LSTM |
|---|---|---|---|---|
| t=1 | 0.654 | 0.730 | 0.926 | 0.913 |
| t=2 | 0.614 | 0.689 | 0.876 | 0.863 |
| t=3 | 0.579 | 0.648 | 0.827 | 0.812 |
| t=4 | 0.554 | 0.613 | 0.786 | 0.756 |
表I:预测模型的F1分数
C. 整体系统性能
最后,我们在不同策略下评估整体系统性能。在此,我们测量了不同策略的总松弛量(资源过度配置的数量)、由于内存溢出错误导致的容器终止次数,以及每种策略产生的调整大小操作次数。
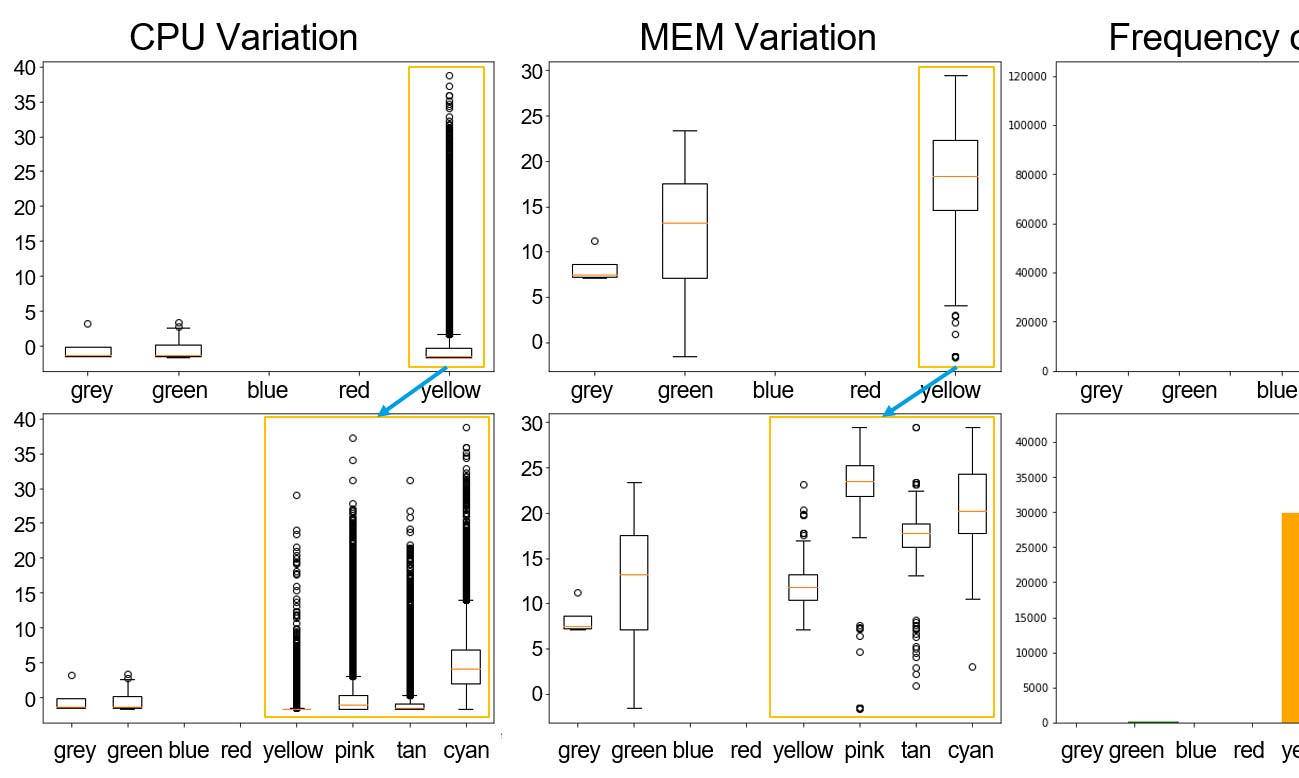
图3显示了不同策略在累积密度函数中CPU和内存的过度配置冗余情况。需要注意的是,基于阶段预测的主动策略能够实现更紧密的资源配置,使得资源限制与实际使用之间的冗余更小。此外,该主动策略因内存溢出错误导致的容器终止次数更少(20次),而两种被动策略均导致超过500次的容器终止。表二展示了各策略在自动扩展性能方面的对比结果。
| 策略 | 自动扩展变更 | 内存溢出容器 | CPU过度分配 (CPU×hour) | 内存过度分配 (KB×hour) |
|---|---|---|---|---|
| 预测性 | 3.74 | 20 | 6.37e+08 | 5.03e+07 |
| 反应式‐最大 | 33.28 | 402 | 10.20e+08 | 3.74e+07 |
| 反应式‐统计 | 3.40 | 357 | 101.79e+08 | 2.28e+08 |
表二:每种策略的平均事件数量,以及在 CPU hour和 KBytes hour中的过度配置
我们观察到,反应式最大策略的自动扩展变更平均次数非常高,达到33次。相比之下,主动式和反应式统计策略每个容器的变更次数要少得多(约为3‐4次)。需要注意的是,预测性和反应式策略均仅进行极少的变更,因为使用率的波动可能被识别为特定阶段。主动策略的主要优势在于能够预见潜在的相变,避免因内存溢出错误导致的容器终止。总体而言,我们基于阶段预测的主动式自动伸缩策略将CPU资源过度配置量从 10 · 10^8 CPU × hour降低至6 · 10^8 CPU × hour。此外,我们发现,由于内存溢出错误,我们的主动策略导致的容器终止次数显著减少(20次),而两种反应式策略分别导致数百次容器终止,即反应式统计策略为357次、反应式‐最大策略为402次内存溢出错误。因此,与反应式方法相比,我们基于预测的主动策略在更少扩容操作的情况下显得更加安全。
五、结论
受先前工作[10],[1]的启发,本文提出了一种面向容器化机器学习服务的主动式垂直自动伸缩方法。我们通过引入迭代增量方法,增强了基于CRBM的阶段发现方法,以适应更广泛类型的机器学习工作负载。此外,通过对运行不同类型工作负载的容器进行阶段发现,我们发现典型相变在各类容器中普遍存在,构成了机器学习服务中大多数突发性资源使用变化的主要原因。能够预见此类相变有助于主动调整容器规模,以应对资源需求的突变。通过使用多层感知机模型对相变进行建模,我们证明了这类突发性行为变化可以通过阶段信息进行预测,并可用于主动式自动伸缩策略中。评估结果表明,与最优的反应式策略相比,在保持相同的自动伸缩调整量的前提下,我们的主动式自动伸缩策略能更安全地显著提升资源效率(将潜在内存溢出场景从65%降低至4%)。

















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









