import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import permutation_test_score
from sklearn import datasets
# loading a dataset
# 识别鸢尾花的特征数据
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 标签中一共分了几个类别
n_classes = np.unique(y).size
# some noisy data not correlated
# 添加不相关的噪音数据
# 随机数生成器生成符合高斯分布的随机数
# 参数loc,高斯分布的中心
# 参数scale,高斯分布的标准差
# 参数size,高斯分布形状,即产生多少样本
random = np.random.RandomState(seed=0)
E = random.normal(size=(len(X), 2200))
# add noisy data to the informative features for make the task harder
# np.c_函数将原数据集X和噪音数据集连接起来
X = np.c_[X, E]
# 实例化支持向量分类模型
svm = SVC(kernel='linear')
# 实例化层次交叉验证策略模型,使用2折交叉验证
cv = StratifiedKFold(2)
# model validation模型验证模块中的函数
# 使用置换检验评估交叉验证评分的重要度
# 参数estimator,基础模型,需事先fit属性,用来匹配数据
# 参数X, y,原始数据集和标签集,用于监督学习场景
# 参数groups,样本标签,如果存在,则做置换检验时会在同一标签下置换样本,否则就是在全量样本中做置换
# 参考:https://blog.youkuaiyun.com/u011467621/article/details/47971917
# 参数scoring,评估预测结果的方式,支持字符串、可调用对象、空值
# 参数cv,交叉验证策略
# 参数n_permutations,置换样本的次数
# 参数n_jobs,使用几个CPU完成计算,默认为1,-1表示所有
# 返回值score,不置换样本的条件下得到的评分
# 返回值permutation_scores,每一次置换样本后得到的评分
# 返回值pvalue,概率估计值,由公式:(C + 1) / (n_permutations + 1) 给出,C是置换后评分大于不置换评分的次数
# 最好的情况是p值为1/(n_permutations + 1),最坏的情况p值为1,最坏的情况下,表示分类结果是完全不可信的
score, permutation_scores, pvalue = permutation_test_score(svm, X, y, scoring='accuracy', cv=cv,
n_permutations=100, n_jobs=1)
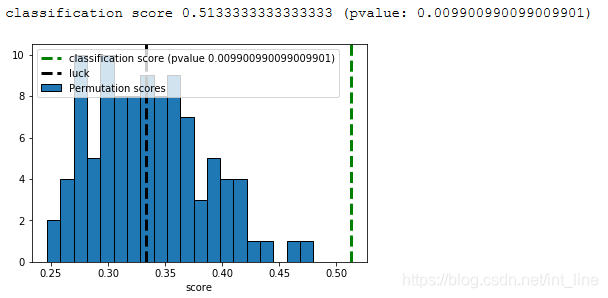
print('classification score %s (pvalue: %s)' % (score, pvalue))
# view histogram of permutation scores
plt.hist(permutation_scores, 20, label='Permutation scores', edgecolor='black')
ylim = plt.ylim()
plt.plot(2*[score], ylim, '--g', linewidth=3, label='classification score (pvalue %s)' % pvalue)
plt.plot(2*[1./n_classes], ylim, '--k', linewidth=3, label='luck')
plt.ylim(ylim)
plt.legend()
plt.xlabel('score')
plt.show()
print(score)
print(permutation_scores)






 本文通过使用支持向量机(SVM)对鸢尾花数据集进行分类,并采用置换检验来评估分类结果的重要性。在实验中,引入了额外的噪声数据以增加任务难度,并使用2折交叉验证进行模型验证。
本文通过使用支持向量机(SVM)对鸢尾花数据集进行分类,并采用置换检验来评估分类结果的重要性。在实验中,引入了额外的噪声数据以增加任务难度,并使用2折交叉验证进行模型验证。

















 1632
1632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









