# 一个单变量特征选择的例子
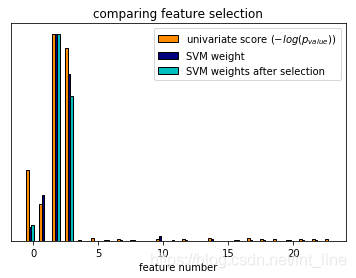
# 在使用iris数据集时,会往里添加噪音特征,然后再应用单变量特征选择。对于每一个特征,会同时展示出单变量特征选择给出的p值和SVM算法给出的权重值
# 可以看到单变量选择会把拥有较高SVM权重的特征选择出来
# 全量特征集中,只有4个是关键特征,它们在单变量特征选择中也拥有最高分
# SVM虽然给这些特征赋予了最大权重,但仍然会选择其他无关特征
# 在训练SVM模型之前,应用单变量特征选择对数据进行转换可以促使SVM将权重分配到最重要的那部分特征上,并且提高分类效果
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets, svm
from sklearn.feature_selection import SelectPercentile, f_classif
# import iris dataset
# 导入训练数据,数据形状为(150,4)
iris = datasets.load_iris()
# some noisy data not correlated
# 生成噪音数据,数据形状为(150,20)
E = np.random.uniform(0, 0.1, size=(len(iris.data), 20))
# add the noisy data to the informative features
# 将噪音数据添加到训练数据,新的训练数据形状为(150,24)
X = np.hstack((iris.data, E))
y = iris.target
plt.figure(1)
plt.clf()
# 生成训练数据特征索引,从0开始直到23。arange函数左闭右开
X_indices = np.arange(X.shape[-1])
# univariate feature selection with F-test for feature scoring
# we use the default selection function: the 10% most significant features
# 应用基于F检验的单变量特征选择,按评分从高到低选择前10%的特征
# SelectPercentle类,根据评分函数给出的评分,按给定百分比选择特征,默认前10%
# 类属性包括F值和p值
# f_classif类,根据方差分析计算F值和p值
selector = SelectPercentile(f_classif, percentile=10)
# 匹配训练数据和标签数据
selector.fit(X, y)
# 特征p值对数化
scores = -np.log10(selector.pvalues_)
# 特征p值正则化,统一取值范围 0~1
scores /= scores.max()
# 用柱状图可视化p值,参数分别为:柱状图位置、柱状图高度、柱状图宽度、柱状图标签、壮壮图颜色、柱状图边框颜色
plt.bar(X_indices - .45, scores, width=.2,
label=r'univariate score ($-log(p_{value})$)', color='darkorange', edgecolor='black')
# compare to the weights of an SVM
# 实例化SVC分类器
clf = svm.SVC(kernel='linear')
# 训练模型
clf.fit(X, y)
# 正则化SVC特征权重,权重取值范围为 0~1
svm_weights = (clf.coef_**2).sum(axis=0)
svm_weights /= svm_weights.max()
# 柱状图可视化权重,参数同上
plt.bar(X_indices - .25, svm_weights, width=.2, label='SVM weight',
color='navy', edgecolor='black')
# 实例化SVC分类器
clf_selected = svm.SVC(kernel='linear')
# 先用单变量特征选择对元树数据进行转换,再训练分类模型
clf_selected.fit(selector.transform(X), y)
# 正则化新分类模型的权重
svm_weights_selected = (clf_selected.coef_**2).sum(axis=0)
svm_weights_selected /= svm_weights_selected.max()
# 柱状图可视化新特征权重
plt.bar(X_indices[selector.get_support()]-.05, svm_weights_selected,
width=.2, label='SVM weights after selection', color='c',
edgecolor='black')
plt.title('comparing feature selection')
plt.xlabel('feature number')
plt.yticks(())
plt.axis('tight')
plt.legend(loc='upper right')
plt.show()
print(iris.data.shape)
print(E.shape)
print(X.shape)
print(scores)
print(svm_weights)
print(selector.get_support())
print(svm_weights_selected)
(150, 4)
(150, 20)
(150, 24)
[3.40023500e-01 1.75404693e-01 1.00000000e+00 9.31982956e-01
4.84838523e-03 1.44660170e-02 5.43086781e-03 1.09236463e-02
2.31751532e-03 1.67390458e-05 8.62127705e-03 8.77580361e-04
7.71874738e-03 1.16995322e-03 1.59215706e-02 2.46085855e-04
4.20414737e-03 1.13601613e-02 7.24168285e-03 7.67741484e-03
1.85821739e-03 6.90814695e-03 1.02542495e-02 9.69346040e-03]
[6.52829321e-02 2.21457858e-01 1.00000000e+00 8.03981594e-01
3.66844225e-04 2.50121675e-05 2.32778421e-03 2.59312393e-03
2.26319998e-03 4.39828920e-04 2.49510595e-02 1.74691867e-03
2.62280244e-03 2.62203257e-04 9.25326284e-03 9.87155952e-04
4.10793213e-03 2.34023190e-03 1.72658141e-03 6.26172314e-04
3.93877462e-03 2.45925689e-03 3.37272762e-03 8.46258754e-04]
[ True False True True False False False False False False False False
False False False False False False False False False False False False]
[0.07565093 1. 0.6996112 ]





 本文深入探讨了如何利用sklearn库进行单变量特征选择。通过介绍和实例,展示了如何有效地从数据集中筛选出最相关的特征,提高模型的性能和解释性。
本文深入探讨了如何利用sklearn库进行单变量特征选择。通过介绍和实例,展示了如何有效地从数据集中筛选出最相关的特征,提高模型的性能和解释性。

















 1104
1104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









