




文章目录
Pytorch|李沐动手学深度学习:基础
本部分为基于李沐的《动手学深度学习》课程的学习笔记,主要内容包括深度学习基础(线性神经网络,多层感知机)、空间上的神经网络——卷积神经网络(LeNet,AlexNet,VGG,Inception,ResNet)、时间上的神经网络——循环神经网络(RNN,GRU,LSTM,seq2seq)、注意力机制(Attention,Transformer)、优化算法(SGD,Momentum,Adam)和高性能计算(并行,多GPU,分布式),以及深度学习的两大领域——计算机视觉(目标检测和语义分割)和自然语言处理(词嵌入和BERT)。
- 课程主页:https://courses.d2l.ai/zh-v2
- 教材:https://zh-v2.d2l.ai/
基础
(一)安装
- 使用 conda/miniconda 安装
conda create -n pytorch -y python=3.8 pip
conda activate pytorch
# 安装深度学习框架和d2l软件包,可以按如下方式安装PyTorch的CPU或GPU版本
conda install jupyter notebook=6.4
pip install d2l torch torchvision
- 下载课程代码
wget https://zh-v2.d2l.ai/d2l-zh.zip
unzip d2l-zh.zip
- jupyter 使用
此处正常情况下可以直接使用 pip install rise 安装 rise,即可在浏览器中以幻灯片形式查看 ipynb 文件,如果不能实现,可以采用如下方式来解决。
# jupyetr notebook(以下简称 notebook) 7.x 版本不再支持插件 nbextensions,此处需要安装 6.x 版本
conda install notebook=6.4
# 安装并启用 jupyter_contrib_nbextensions(插件管理器)
pip install jupyter-contrib-nbextensions
jupyter contrib nbextension install --user
jupyter nbextensions_configurator enable --user
# 安装并启用 rise,即可在浏览器中以幻灯片形式查看 ipynb 文件
pip install rise
jupyter-nbextension install rise --py --sys-prefix
jupyter-nbextension enable rise --py --sys-prefix
# 打开 jupyter
jupyter notebook
补充:在安装深度学习框架之前,请先检查计算机上是否有可用的GPU。 例如可以查看计算机是否装有NVIDIA GPU并已安装CUDA。 如果机器没有任何GPU,也可以使用CPU版本。
# GPU版本:CUDA + PyTorch
# 查看计算机是否装有 NVIDIA GPU
nvidia-smi
# 查看是否安装有 CUDA
nvcc --version
如果计算机已经装有NVIDIA GPU并已安装CUDA,可以按照上面的相同操作完成 GPU 版本 pytorch 的安装,通过以下方式查看 GPU 版本 pytorch 是否安装成功:
import torch
print(torch.__version__)
print(torch.cuda.is_available())
(二)数据操作
1. 前言
-
N维数组(张量,tensor)是机器学习和神经网络的主要数据结构

-
创建数组
- 形状(3✕4矩阵)
- 每个元素的数据类型(32位浮点数)
- 每个元素的值(全是0或随机数)
-
访问元素
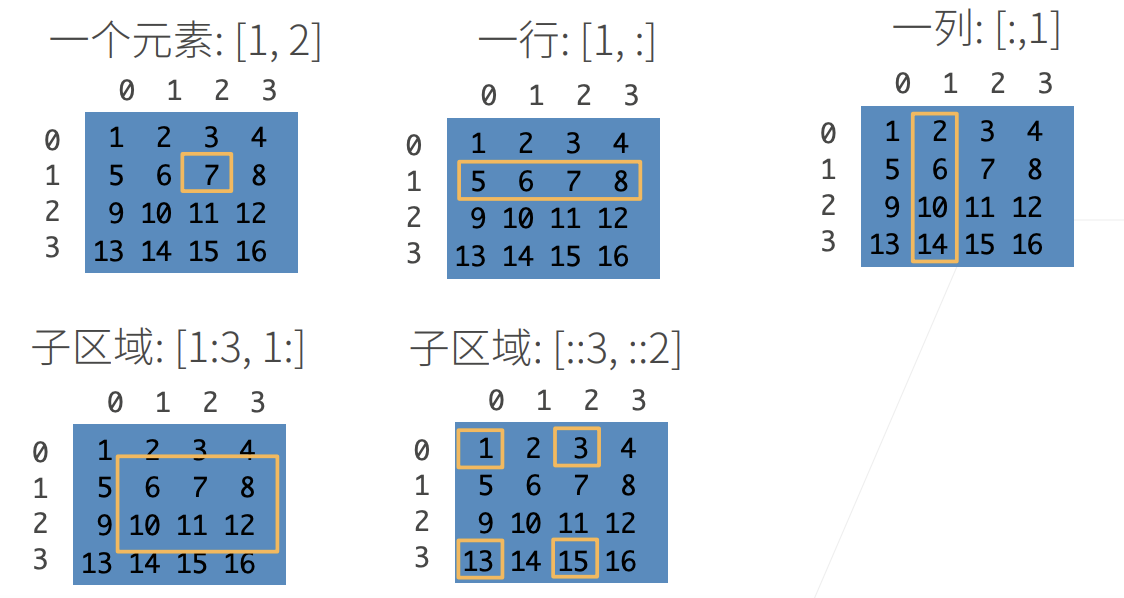
2. 实战
(1)入门
import torch
# 张量表示一个数值组成的数组,可能有多个维度,具有一个轴的张量对应数学上的向量(vector); 具有两个轴的张量对应数学上的矩阵(matrix); 具有两个轴以上的张量没有特殊的数学名称
x = torch.arange(12)
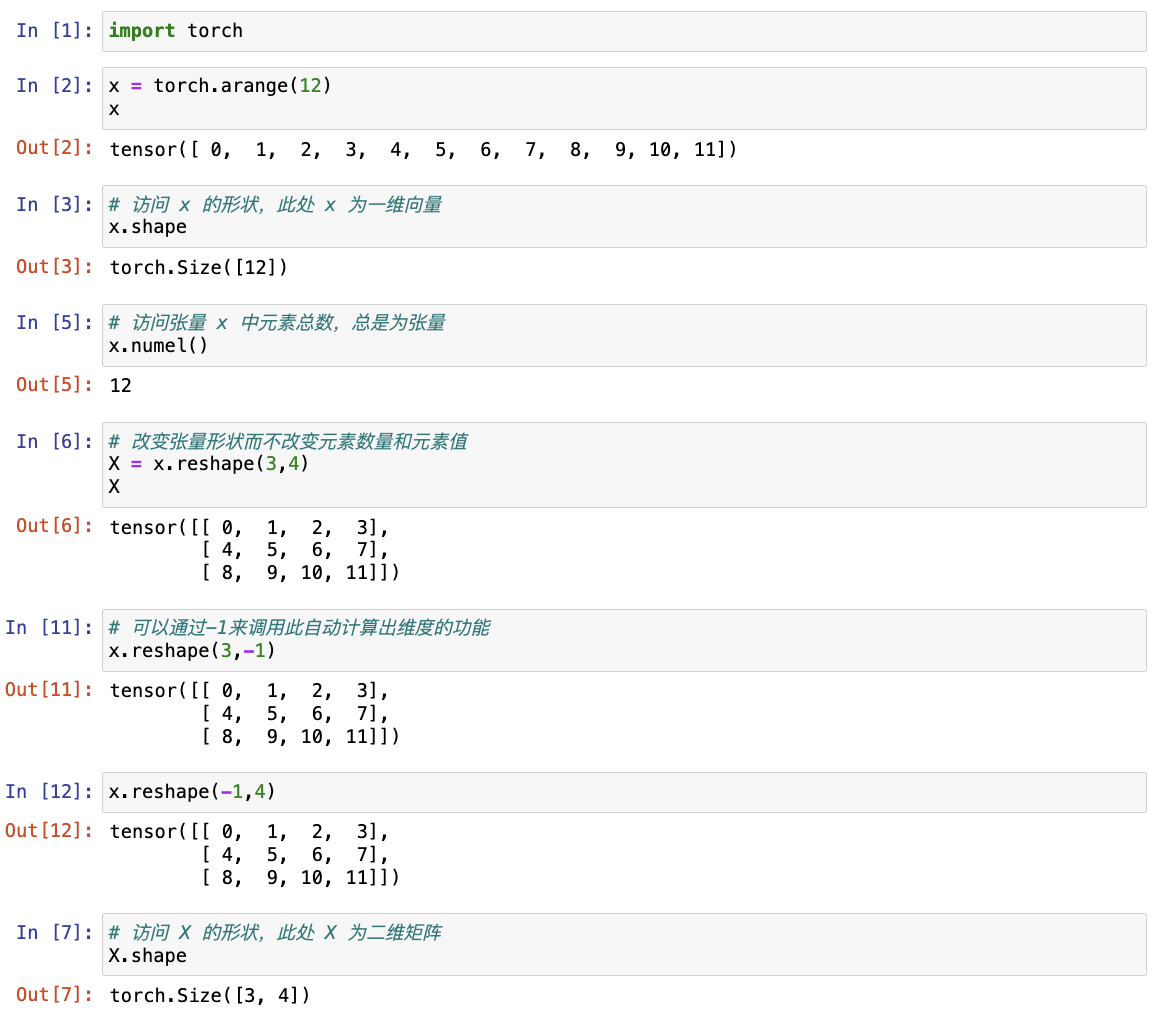
# 可以通过张量的 shape 属性来访问张量的形状和张量中元素的总数
x.shape
x.numel()
# 可以调用 reshape 函数改变张量形状而不改变元素数量和元素值
# 可以通过-1来调用此自动计算出维度的功能,即可以用x.reshape(-1,4)或x.reshape(3,-1)来取代x.reshape(3,4)
X = x.reshape(3,4)
X
注意:reshape后修改对应值会导致原来的张量也发生变化。

# 当构造数组来作为神经网络中的参数时通常会随机初始化参数的值
# 使用全0、全1、其他常量或者从特定分布中随机采样的数字
torch.zeros((2,3,4))
torch.ones((2, 3, 4))
torch.randn(3, 4)
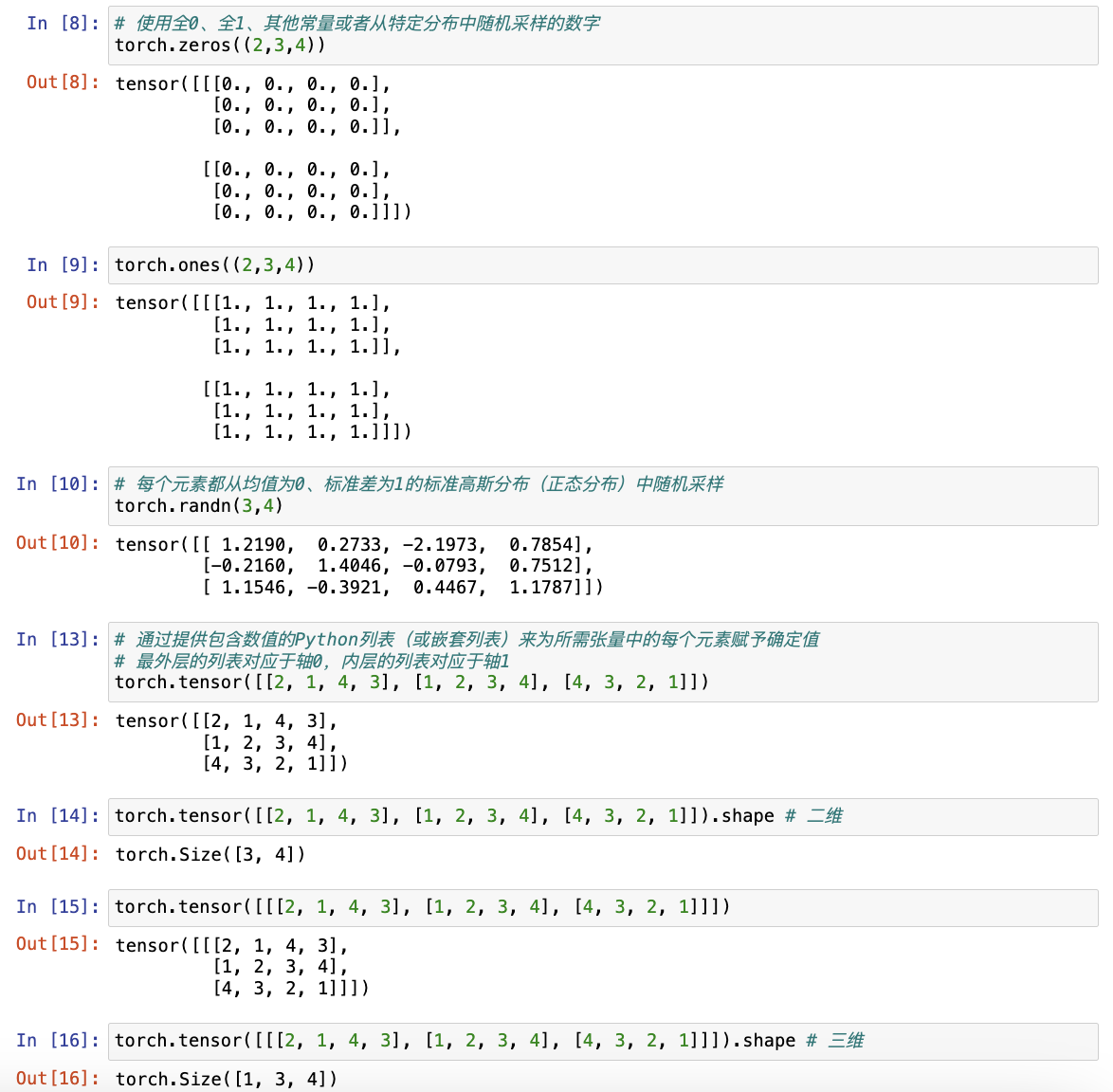
# 通过提供包含数值的Python列表(或嵌套列表)来为所需张量中的每个元素赋予确定值
# 最外层的列表对应于轴0,内层的列表对应于轴1
torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
(2)运算符
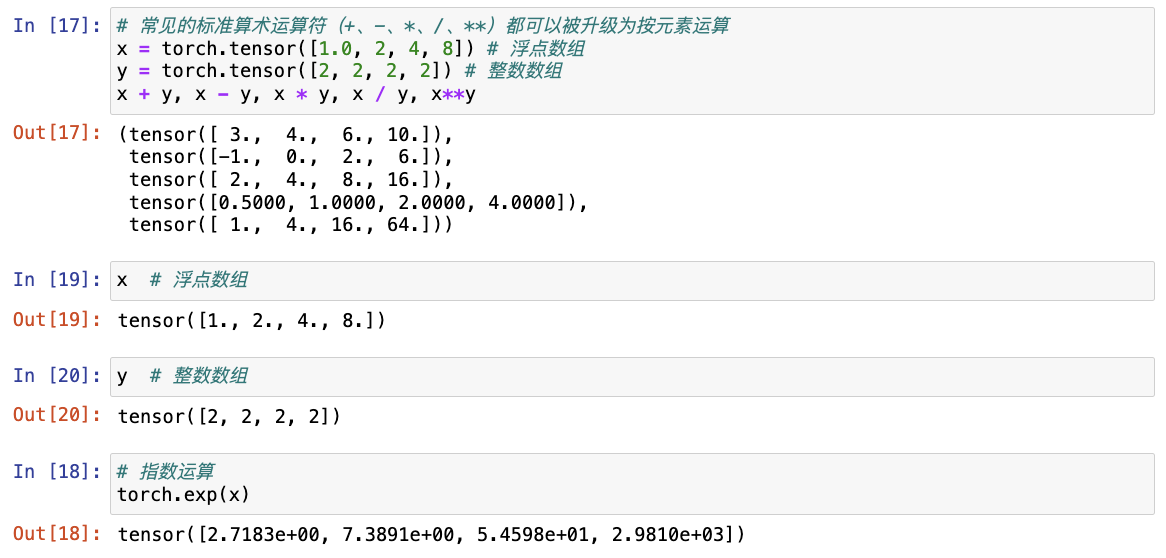
# 常见的标准算术运算符(+、-、*、/、**)都可以被升级为按元素运算
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x**y
# 指数运算
torch.exp(x)
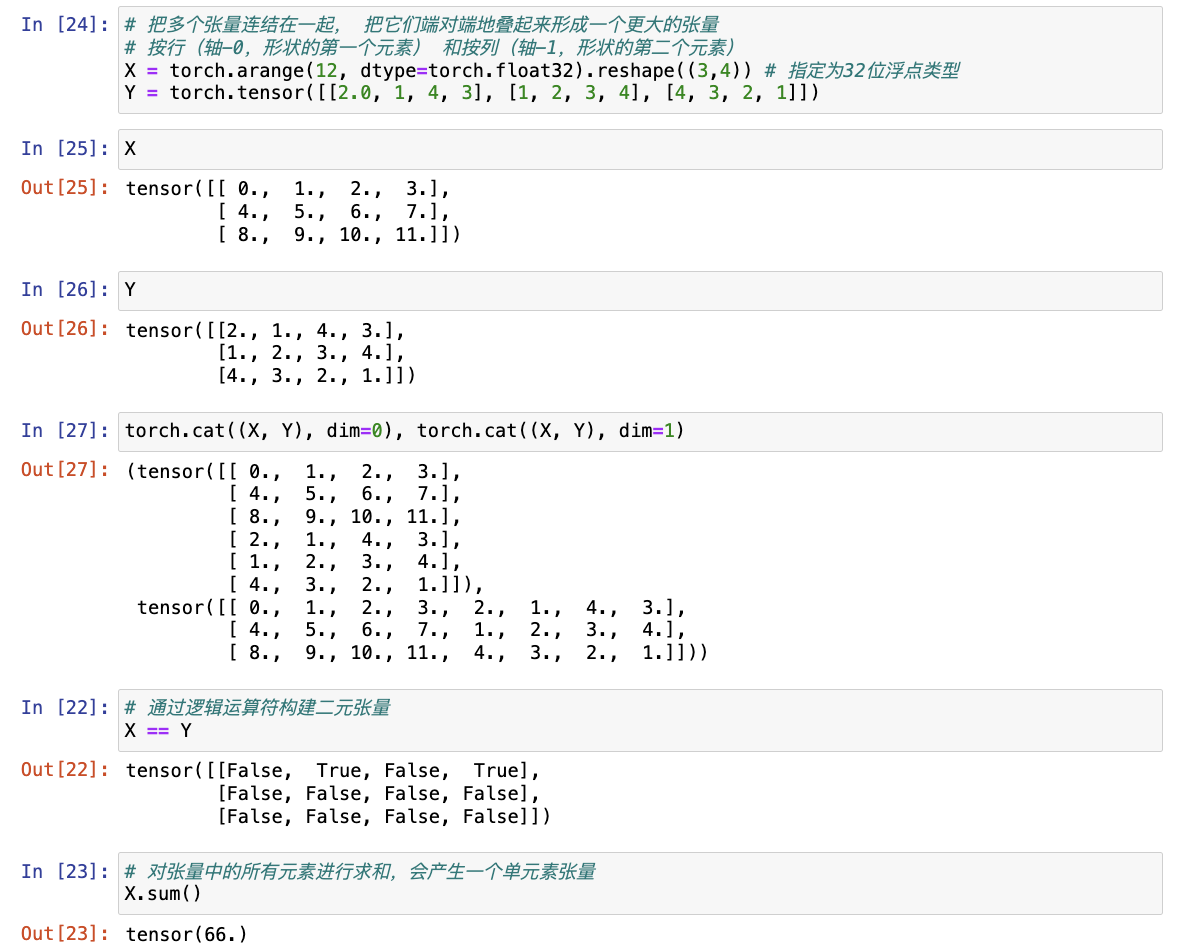
# 把多个张量连结在一起, 把它们端对端地叠起来形成一个更大的张量
# 按行(轴-0,形状的第一个元素) 和按列(轴-1,形状的第二个元素)
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1)
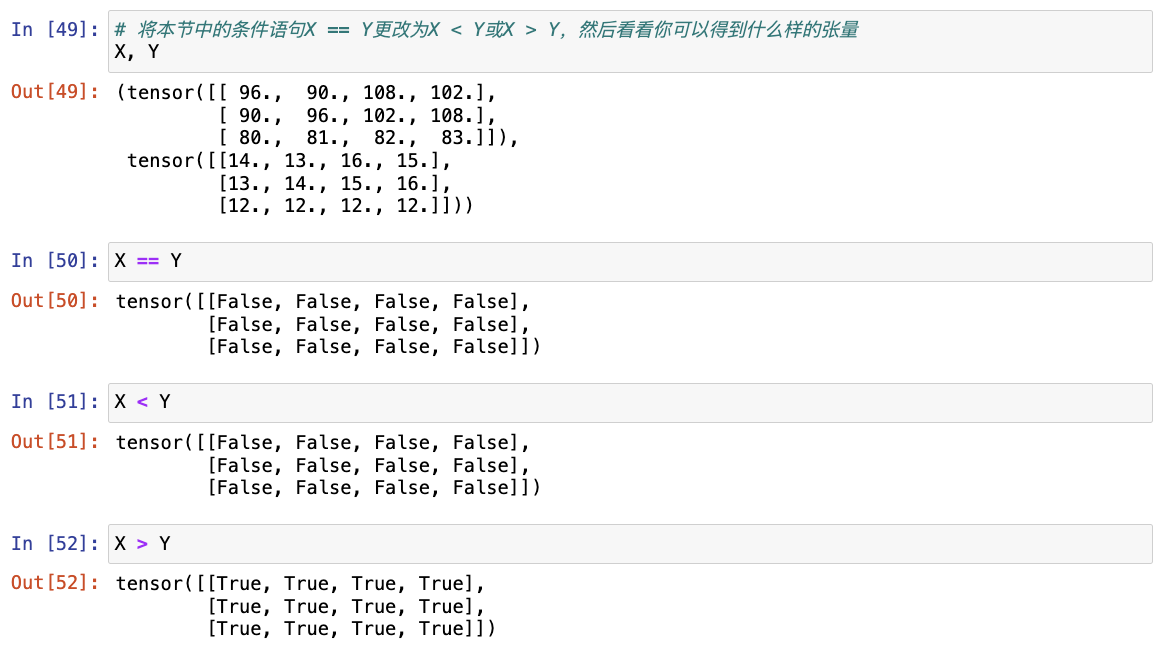
# 通过逻辑运算符构建二元张量
# 以X == Y为例: 对于每个位置,如果X和Y在该位置相等,则新张量中相应项的值为1。 这意味着逻辑语句X == Y在该位置处为真,否则该位置为0
X == Y
# 对张量中的所有元素进行求和,会产生一个单元素张量
X.sum()
(3)广播机制(broadcasting mechanism)
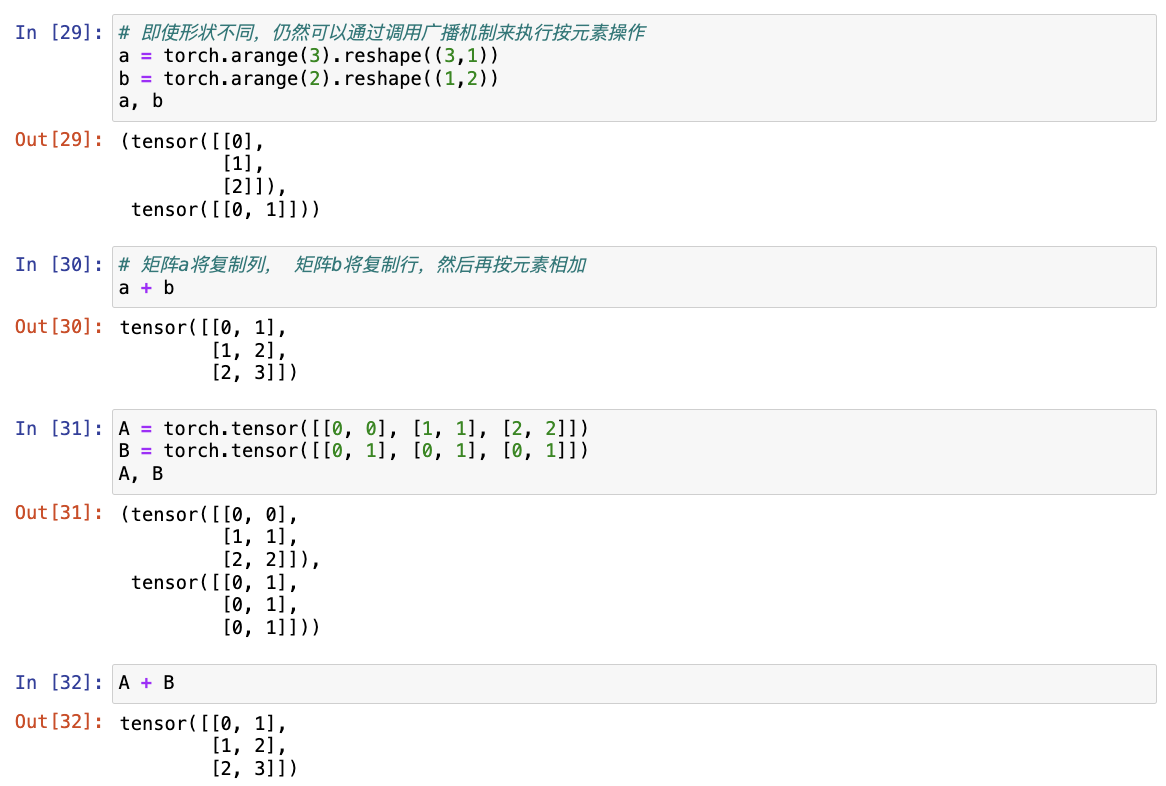
在某些情况下,即使形状不同,仍然可以通过调用广播机制来执行按元素操作,该机制的工作方式如下:
- 通过适当复制元素来扩展一个或两个数组,以便在转换之后,两个张量具有相同的形状;
- 对生成的数组执行按元素操作。
在大多数情况下将沿着数组中长度为1的轴进行广播。
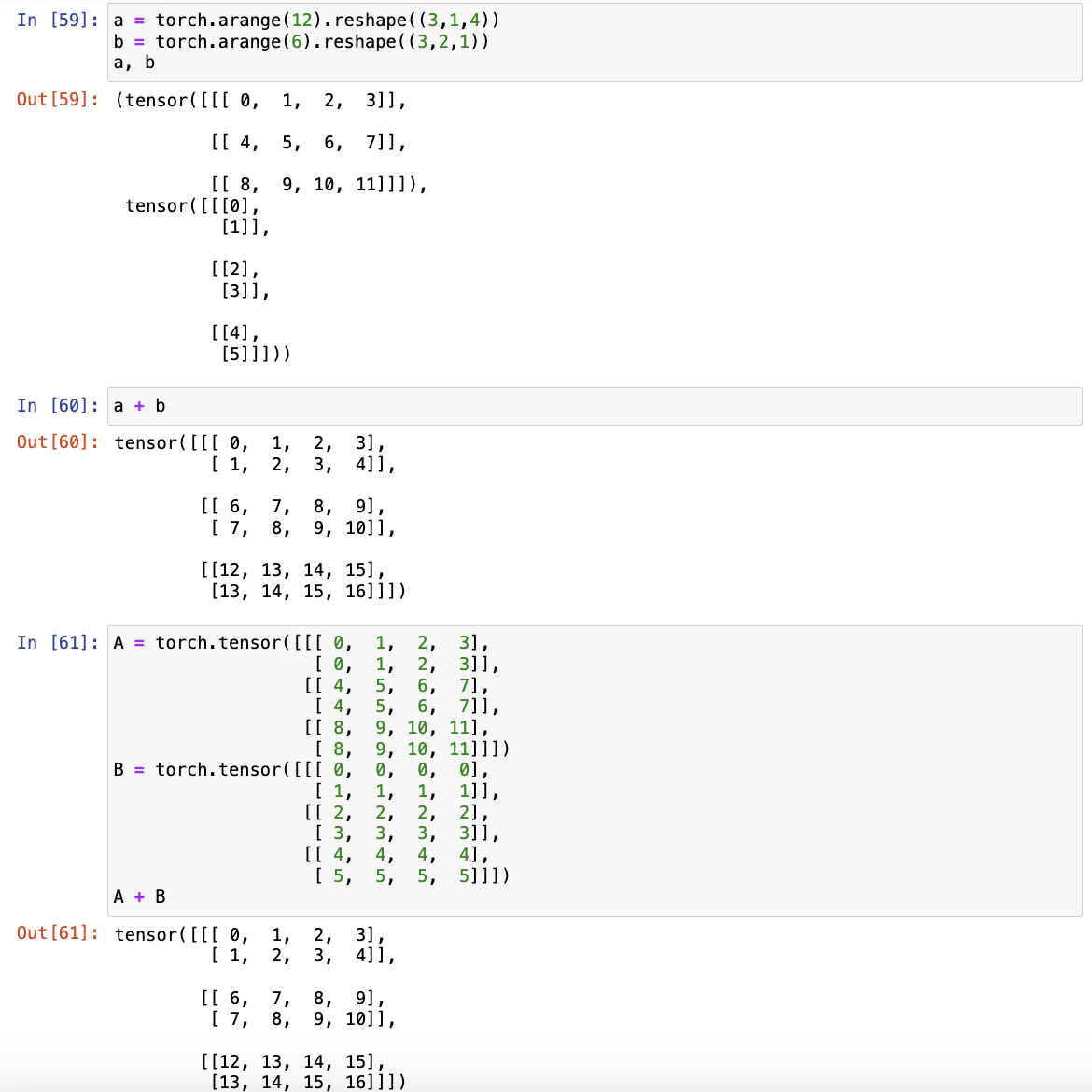
# 即使形状不同,仍然可以通过调用广播机制来执行按元素操作
a = torch.arange(3).reshape((3,1))
b = torch.arange(2).reshape((1,2))
a, b
# 由于a和b形状不匹配,此处将两个矩阵广播为一个更大的矩阵,如下所示:矩阵a将复制列, 矩阵b将复制行,然后再按元素相加
a + b
(4)索引和切片
就像在任何其他Python数组中一样,张量中的元素可以通过索引访问。 与任何Python数组一样:第一个元素的索引是0,最后一个元素索引是-1; 可以指定范围以包含第一个元素和最后一个之前的元素。
# 读取
X[-1], X[1:3]
# 指定索引将元素写入矩阵
X[1, 2] = 9
X
# 为多个元素赋值相同的值,只需要索引所有元素,然后为它们赋值
X[0:2, :] = 12
X

(5)节省内存
运行一些操作可能会导致为新结果分配内存。 例如,如果我们用Y = X + Y,我们将取消引用Y指向的张量,而是指向新分配的内存处的张量。
在下面的例子中,我们用Python的id()函数演示了这一点, 它给我们提供了内存中引用对象的确切地址。 运行Y = Y + X后,我们会发现id(Y)指向另一个位置。 这是因为Python首先计算Y + X,为结果分配新的内存,然后使Y指向内存中的这个新位置。
before = id(Y)
Y = Y + X
id(Y) == before

这可能是不可取的,原因有两个:
- 首先,我们不想总是不必要地分配内存。在机器学习中,我们可能有数百兆的参数,并且在一秒内多次更新所有参数。通常情况下,我们希望原地执行这些更新;
- 如果我们不原地更新,其他引用仍然会指向旧的内存位置,这样我们的某些代码可能会无意中引用旧的参数。
# 执行原地操作,可以使用切片表示法将操作的结果分配给先前分配的数组
Z = torch.zeros_like(Y)
print('id(Z):', id(Z))
Z[:] = X + Y
print('id(Z):', id(Z))
# 如果在后续计算中没有重复使用X,可以使用X[:] = X + Y或X += Y来减少操作的内存开销
before = id(X)
X += Y
id(X) == before
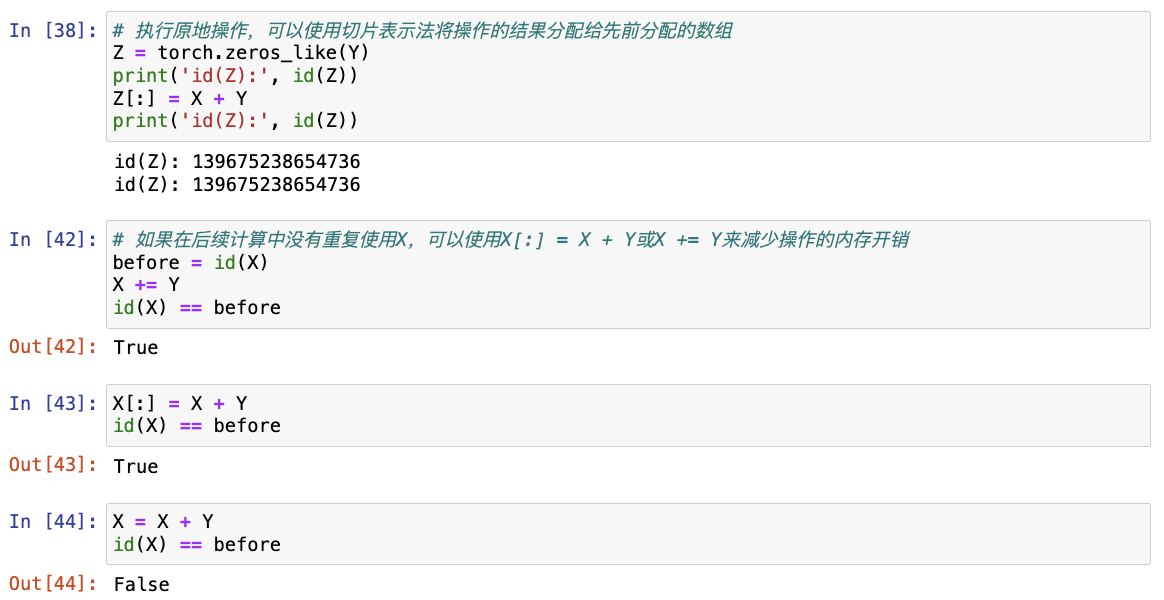
注意:此处的 X=X+Y 与 X+=Y 并不等价。
(6)转换为其他Python对象
将深度学习框架定义的张量转换为NumPy张量(ndarray)很容易,反之也同样容易。 torch张量和numpy数组将共享它们的底层内存,就地操作更改一个张量也会同时更改另一个张量。
# 将深度学习框架定义的张量与NumPy张量互相转换
A = X.numpy()
B = torch.tensor(A)
type(A), type(B)
# 将大小为1的张量转换为Python标量,可以调用item函数或Python的内置函数
a = torch.tensor([3.5])
a, a.item(), float(a), int(a)

3. 练习
(1) 运行本节中的代码。将本节中的条件语句X == Y更改为X < Y或X > Y,然后看看你可以得到什么样的张量 -> 逐元素比较
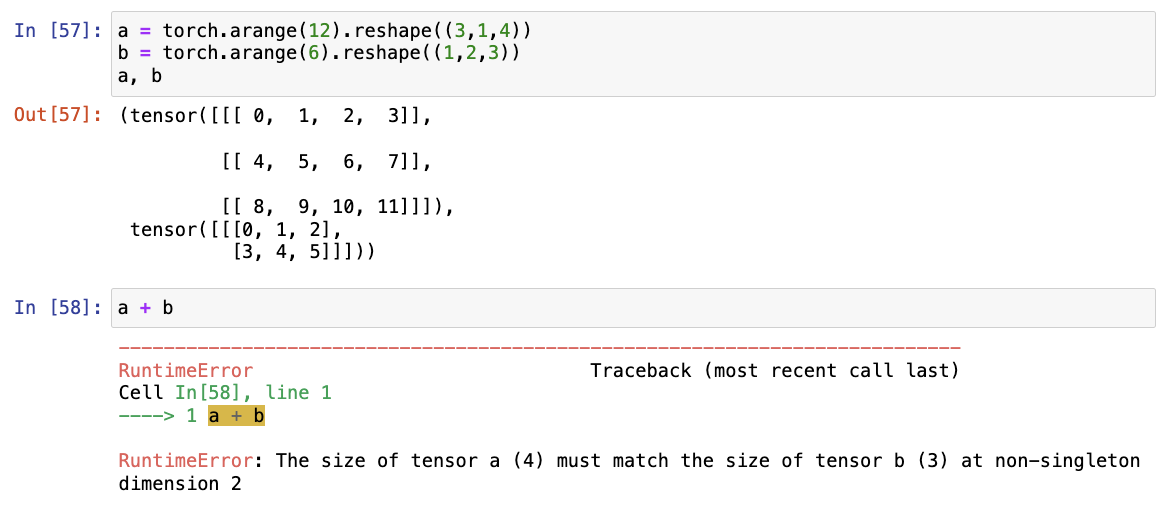
(2) 用其他形状(例如三维张量)替换广播机制中按元素操作的两个张量。结果是否与预期相同 -> 相同
注意:在尝试对两个张量进行操作时,张量 a 和 b 的维度不匹配,特别是在第2个非单例维度(即不为1的维度),它们的大小分别是4和3。这意味着你需要确保在操作(如加法)前,两个张量在所有相应的维度上具有相同的大小,如果其中一个张量的某些维度为1,可以利用广播机制让其适应另一个张量的维度。例如,如果 b 的形状是 (3, 1) 而 a 是 (3, 4),那么可以通过广播使它们相加。
(三)数据预处理
1. 实战
(1)读取数据集
# 创建一个人工数据集并存储为csv
import os
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每行表示一个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
# 从创建的CSV文件中加载原始数据集
import pandas as pd
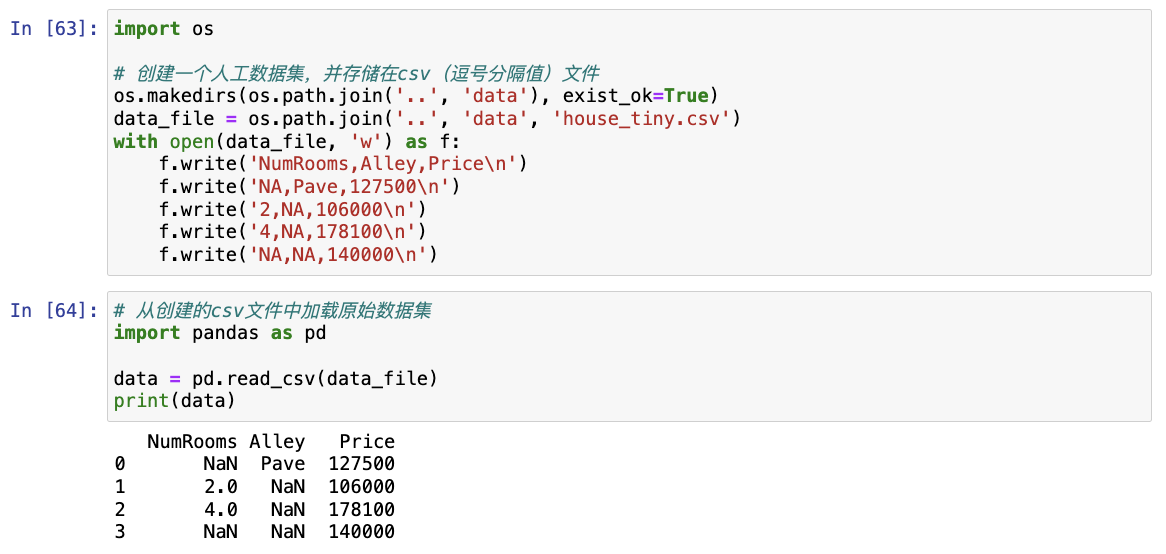
data = pd.read_csv(data_file)
print(data)
(2)处理缺失值
为了处理缺失的数据,典型的方法包括插值法和删除法, 其中插值法用一个替代值弥补缺失值,而删除法则直接忽略缺失值。
# 为了处理缺失的数据,典型的方法包括插值和删除, 这里考虑插值
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
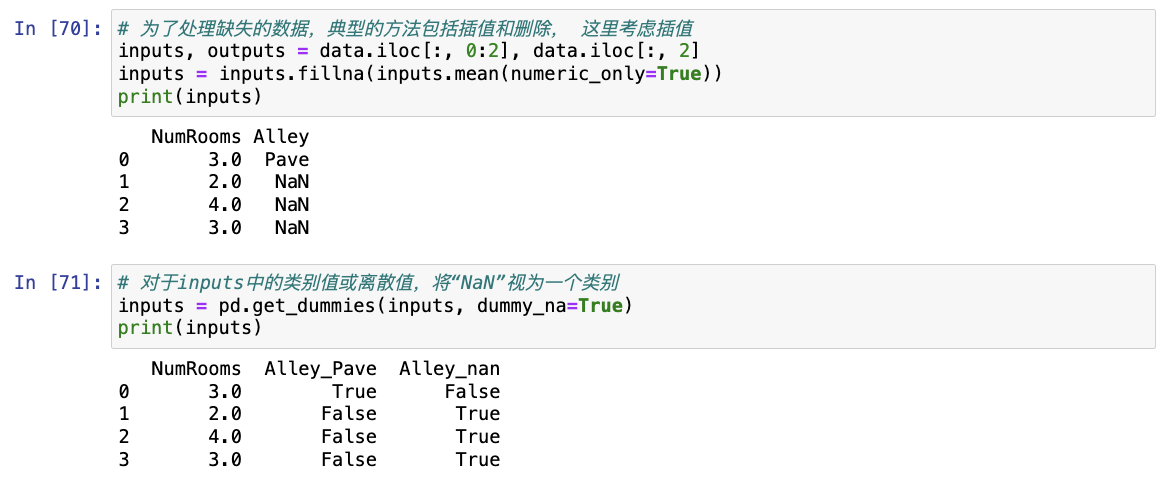
inputs = inputs.fillna(inputs.mean(numeric_only=True))
print(inputs)
# 对于inputs中的类别值或离散值,将“NaN”视为一个类别
# 由于“巷子类型”(“Alley”)列只接受两种类型的类别值“Pave”和“NaN”, pandas可以自动将此列转换为两列“Alley_Pave”和“Alley_nan”
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)
(3)转换为张量格式
import torch
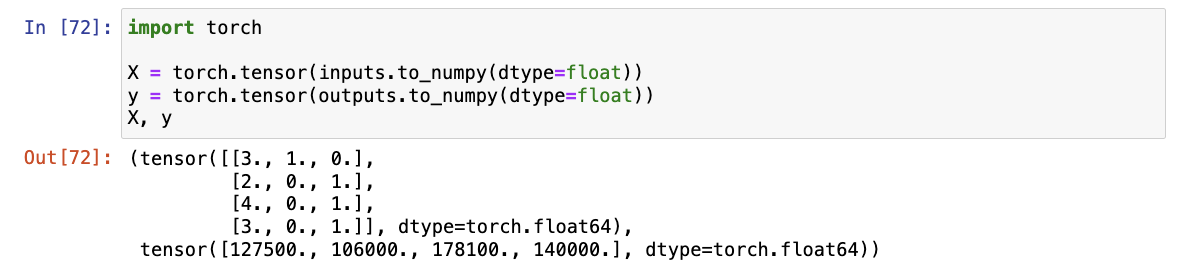
X = torch.tensor(inputs.to_numpy(dtype=float))
y = torch.tensor(outputs.to_numpy(dtype=float))
X, y
注意:对于深度学习来说,float64计算较慢,所以通常使用float32。
2. 练习
创建包含更多行和列的原始数据集。
- 删除缺失值最多的列。
- 将预处理后的数据集转换为张量格式。
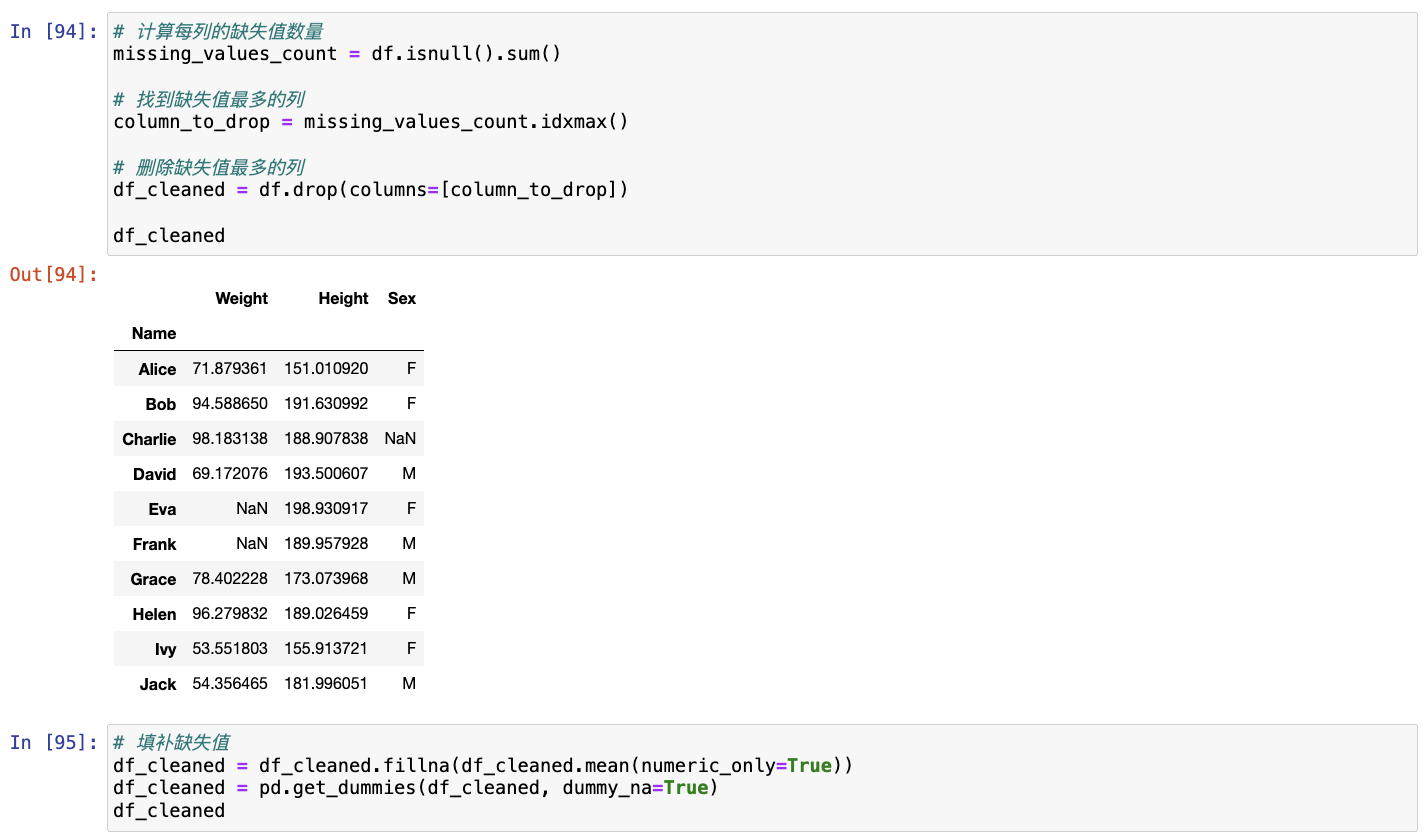
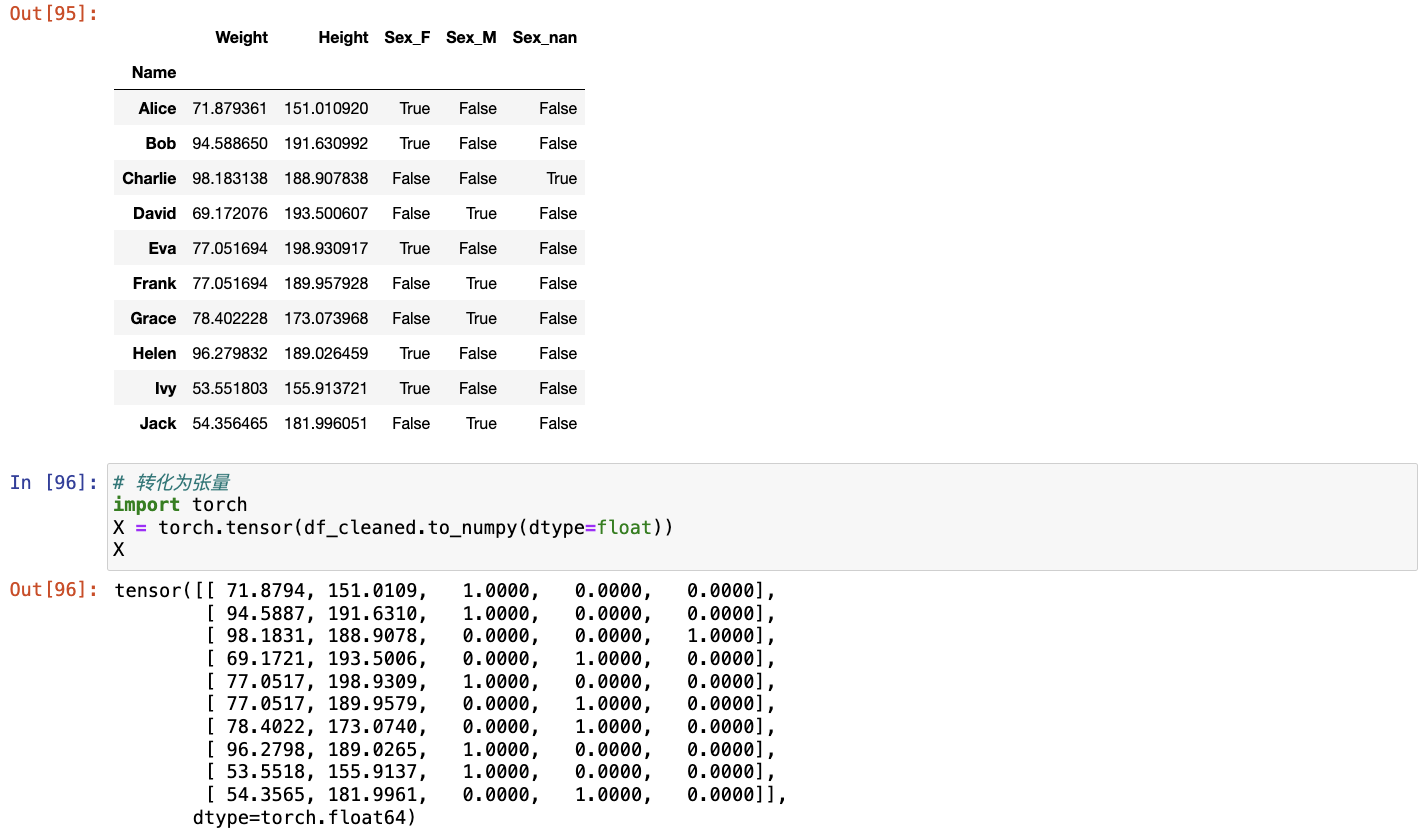
参考
- jupyter notebook中rise插件的安装_pip install rise-优快云博客:https://blog.youkuaiyun.com/maodajitui/article/details/132191589
- 【jupyter notebook】中插件 nbextensions 安装失败分析与解决方法_modulenotfounderror: no module named 'notebook.nbe-优快云博客:https://blog.youkuaiyun.com/weixin_54383080/article/details/134655727


















 1763
1763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









