 Transformer进阶系列:Bi-BloSAN, Universal Transformers与Reformer
Transformer进阶系列:Bi-BloSAN, Universal Transformers与Reformer





 本文梳理了Transformer派的三项关键改进:双向分块自注意力(Bi-BloSAN)降低内存消耗,Universal Transformers增强归纳偏置和计算效率,Reformer采用可逆层和LSH Attention优化效率。这些创新推动了NLP模型在速度与性能上的提升。
本文梳理了Transformer派的三项关键改进:双向分块自注意力(Bi-BloSAN)降低内存消耗,Universal Transformers增强归纳偏置和计算效率,Reformer采用可逆层和LSH Attention优化效率。这些创新推动了NLP模型在速度与性能上的提升。

在开始学习之前推荐大家可以多在 FlyAI竞赛服务平台多参加训练和竞赛,以此来提升自己的能力。FlyAI是为AI开发者提供数据竞赛并支持GPU离线训练的一站式服务平台。每周免费提供项目开源算法样例,支持算法能力变现以及快速的迭代算法模型。
摘要: 经过之前一段时间的 NLP Big Bang,现在相对比较平静了,Transformer 派已经占据了绝对的主导地位,在各类应用中表现出色。看标题大家也可以猜个差不多,整理了一系列自《Attention is all you need》之后的对 Vanil ...
| 经过之前一段时间的 NLP Big Bang,现在相对比较平静了,Transformer 派已经占据了的主导地位,在各类应用中表现出色。看标题大家也可以猜个差不多,整理了一系列自《Attention is all you need》之后的对 Vanilla Transformer 的改进论文,和大家一起梳理整个发展过程。这篇是第一趴,都来自ICLR。
OK,来看看今天的 Transformers: 「 Bi-BloSAN from UTS,ICLR2018」 「 Universal Transformers from UVA&Google,ICLR2019」 「 Reformer from Google,ICLR2020」
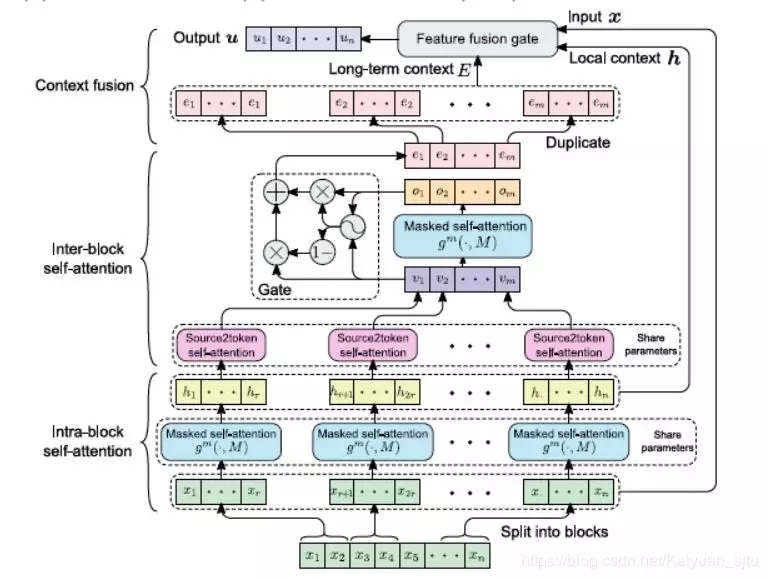
BI-DIRECTIONAL BLOCK SELF-ATTENTION FOR FASTAND MEMORY-EFFICIENT SEQUENCE MODELING[1] 这篇论文首先分析了目前几大类特征抽取器 CNN、RNN、Attention 的优缺点,针对其不足提出了一种对 self-attention 的改进,「双向分块自注意力机制(bidirectional block self-attention (Bi-BloSA))」。
1.1 Masked Block Self-Attention 其最主要的组件是「掩码分块自注意力机制(masked block self-attention (mBloSA))」,基本思想是将序列分成几个等长的 block(必要时进行 padding),对每个单独的 block 内应用 self-attention(「intra-block SAN」)捕获局部特征,然后对所有 block 输出再应用 self-attention(「inter-block SAN」)捕获全局特征。这样,每个 attention 只需要处理较短的序列,与传统的 attention 相比可以节省大量的内存。最后通过 Context fusion 模块将块内 SAN、块间 SAN 与原始输入结合生成最终上下文表示。整体框架如下图所示:
1.2 Masked Sel |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









