



基于语音的边缘计算机器人接口用于自动老年人心理健康护理
摘要
我们需要由专家驱动的开放平台,能够在较长时间内创建和收集查询,并基于严格的临床随访进行诊断。在本研究中,我们开发了一种多语言机器人界面,通过提问互动来帮助评估老年人心理健康。通过语音接口,专家可以提出问题,并以文本形式接收用户的回答。机器人能够使用适当的语言自动与用户互动。它可处理回答,并在专家指导下,使问题与答案朝向期望的治疗方向发展。该原型实现于用于边缘计算的嵌入式设备上,因此能够过滤环境噪声,并可放置在家庭中的任意位置。所提出的平台支持集成知名的开源和商业数据流处理框架。目前,专家可通过基于Web的界面创建查询和回答。
Keywords : 边缘计算;心理健康护理;语音使能技术;嵌入式系统
1. 引言
心理健康护理与诊断如今正逐渐转向移动解决方案[1,2]。事实上,移动应用程序提供了更便捷的支持[3]。这一点显得尤为有意义,因为面对情绪、压力或焦虑问题的人并不总是寻求专业帮助,或在真正需要时获得护理[4]。另一方面,由于地理位置、经济水平或社会原因,所需护理或帮助并不总能及时获得[5]。
大量用于医疗保健的移动应用程序已投入使用。在我们工作的背景下,可以提及MIMOSYS [6]和CHADmon [7]。MIMOSYS [6]是一款通过分析人声来检测由情绪变化引起的疾病或障碍的智能手机应用。文献[7]中的作者提出了CHADMon,这是一款专用于语音分析、心理状态监测以及相变检测的移动应用程序。他们的研究兴趣及相关技术早已在研究中,涵盖了从可接受性到临床疗效,再到靶向治疗和临床益处等多个方面[2]。关于应用程序,在诊断方面必须格外谨慎,因为缺乏专业干预的诊断可能造成伤害并带来污名化[1]。此外,评估和实验测试机制对于临床和适当的验证至关重要[8]。事实上,我们需要由专家主导的开放平台,能够在其中创建和收集查询,并基于严格的临床随访进行诊断。
如今,智能手机普及并可用于私人使用。一些应用程序因其同样的原因而受到用户青睐,特别是年轻人和寻求自我帮助的用户。然而,对于不太熟悉技术但仍然对机器人或语音等免提交互感兴趣的老年人来说,情况并非总是如此。
支持语音的技术正在引领多个领域,从汽车到家庭自动化[9]。据预测,到2020年,[10], 50%的搜索将基于语音,智能音箱的比例也将达到2022[11]。语音搜索往往更具移动性和本地化特征,因为它与许多移动应用和设备集成。许多数字助理已集成到我们日常生活中使用的产品中[10];微软将Cortana集成到Windows 10中,用于文本和语音搜索。亚马逊Echo能够随时回答问题,并控制其他家用设备。诸如亚马逊、谷歌Home或Sonos One等语音助手是免费的;其中许多请求为产品搜索,同时也为广告商提供广告位。尽管这些商业产品并不总是开放定制,但它们得到了开发平台的支持,例如亚马逊AWS [12], 谷歌 [13]和IBM Watson [14], 。

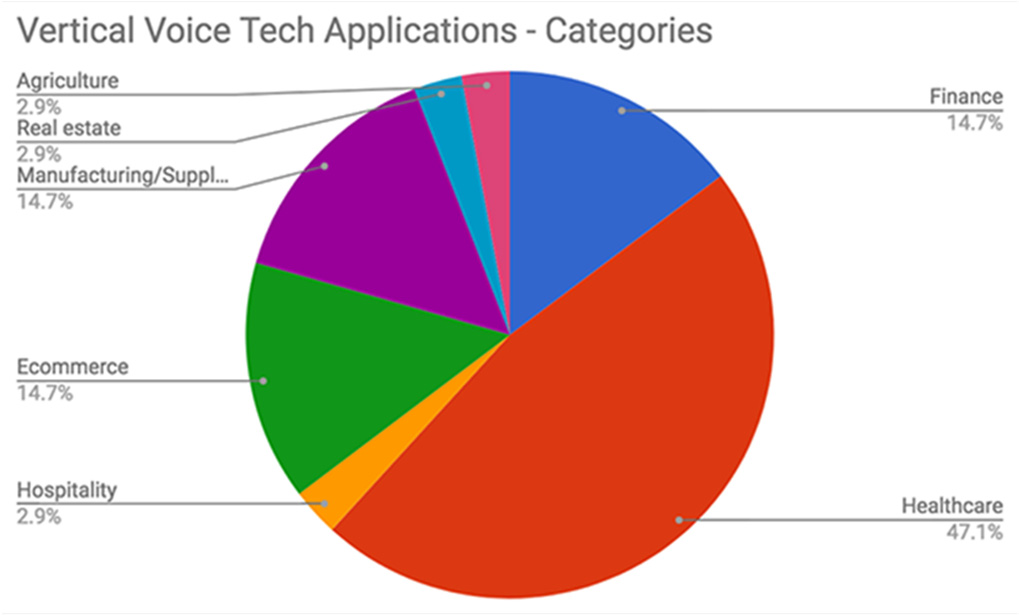
根据[15], ,医疗保健领域是垂直语音应用中最受欢迎的类别(47.1%)(图1)。远程医疗推动了健康领域的对话应用发展,尤其是在医院有强烈动机提供高质量随访护理的情况下。然而,由于涉及数据的保密性以及低错误容忍度等限制,该领域难以快速扩展。因此,医生和护理人员高昂的成本大量消耗在电子健康记录的数据收集工作中。语音健康领域还延伸到希望居家养老的老年人,特别是那些拒绝需要灵巧性或良好视力的移动或智能技术的老年人[9]。居家养老意味着社交、基于人工智能的活动导向界面以及日常监控服务。基于机器人的患者‐护理人员沟通节省了时间,从而提高了诸如提醒和预约等已规划任务的效率。医生笔记,例如电子健康记录(EHR)和患者反馈,现在在多个平台(个人计算机、智能手机)上使用语音技术和基于人工智能的自然语言文员[16] ,包括新型麦克风和可穿戴语音接口[17]。
本工作遵循多个目标:提供一个多语言语音交互平台,通过创建协议和文本查询,以及用于建议和收集结果的文本表单,以促进专家的干预;整合并试验现有技术,以实现情绪自动评估,并提供结果演变的图形视图;关注无响应情况;并将该平台集成到机器人或语音接口中。
本文的结构如下:第2节介绍了基于语音的家庭医疗保健领域最先进的产品。我们特别关注嵌入式语音接口和设备,以及可用的开发工具。第3节描述了实施的系统。第4节展示了结果。第5节对本文进行总结。
2. 技术现状
家用医疗产品正在借助基于人工智能的平台和在线技术不断发展(图2)。基于人工智能的自然语言系统能够捕捉医患互动,在检查室中实时生成患者记录,并生成文本格式电子健康记录[16,17]。
一些医疗平台正与亚马逊Alexa和谷歌助手智能音箱合作,例如Cuida Health LISA[18], ——一位友好的语音助手和伴侣,可记住药物、预约并每日监测健康状况,RemindMeCare[19], 、 Memory Lane[20]或Senter[21]。其中一些是基于人工智能的社交机器人,例如ElliQ[22]和 Senter[21], ,鼓励用户进行个性化的日常活动。在线技术如LifePod[23],可提供日程安排和语音服务,向专业人员和护理人员提供有价值的数据。许多设备实际上是免提语音设备,例如Rosie Reminder[24]和ElliQ[22], ,或可穿戴设备,例如Notable[17]。

有多种工具和选项可用于流数据的处理、存储、索引和管理,这使得从业者难以选择合适的工具和平台组合来构建用于数据流分析的应用程序[25]。此外,医疗分析与推荐系统必须在极短时间框架内处理连续数据流[26]。在[27], 中,作者对分布式数据流处理与分析框架进行了比较研究。该研究考察了开源和商业框架在实现实时分布式数据流处理方面的能力。在[26], 中,作者调研了当前利用边缘计算、流处理引擎以及数据流处理机制的先进架构。他们的研究成果帮助我们明确了专家/用户、数据基础设施以及语音界面功能的需求。事实上,我们的内部数据是基于文本的,用于报告与分析。
由人工智能驱动的对话系统是交互式虚拟对话代理,广泛应用于包括医疗保健在内的各种场景。交互式多语言语音系统能够识别个性化需求,以有效响应用户的情绪、语调和语言。诸如亚马逊、谷歌或IBM Watson等语音助手提供了一些库和API(应用程序编程接口)。这些商业产品并不总是开放定制,但得到了开发平台的支持。事实上,由于其普及性和易用性,我们选择谷歌和IBM的API作为集成到我们开放平台的首批候选方案。IBM Watson [14] 提供了用于语音(文本与语音转换,并具备定制模型的能力)、语言(分析文本并从非结构化内容中提取元数据)以及共情(理解语调、个性和情绪状态)的工具。与谷歌类似,它们还提供文档语言翻译器,可通过自然语言分类器进行增强,该分类器是一种机器学习组件,可将数据组织成自定义类别以分析文本和标签;同时提供语调分析器,用于理解文本中的情绪和沟通方式;以及个性洞察功能,通过
然而,其中一些应用程序编程接口仅适用于英语,因此在多语言语音界面的背景下,语气分析等工具可能会失去其价值。
在[28],中,作者调查了这些流行的API,特别评估了IBM Watson和谷歌。他们的评估用例旨在满足用户关于考试压力的需求,基于使用谷歌表格生成的大学生调查数据。他们对分析与考试相关压力的回答的有效性进行测量的结果表明,这些API对于用户关于考试看法的查询,有76.5%能够做出适当响应。我们关注的是由专家管理的平台,因此自动分析的结果只能被视为有价值的补充信息。
3. 实现架构
本研究旨在开发一种适用于边缘计算的免提语音设备。因此,该系统由一种可编程嵌入式设备组成,可放置于家庭中任意位置,并配备用于音频处理和环境噪声滤波的专用硬件(图3)。

该平台支持集成知名的开源和商业数据流处理框架[27]。可编程部分在ARM A9 CPU上运行 Python。专家(护理者)可通过WEB界面访问请求与响应数据库。该原型基于Xilinx PYNQ‐Z1 开发板[29],实现,旨在用作开源框架,使嵌入式程序员能够利用APSoC(全可编程片上系统)Zynq 系列中的可重构硬件功能。
APSoC的软件部分(图3中的可编程软件PS)使用来自谷歌云 13 和IBM Watson 14 ,全部在Jupyter Notebook [30]开发环境中进行。硬件部分(图3中的可编程逻辑PL )是一个实时音频处理的可编程逻辑电路,作为硬件库导入,并通过API进行编程,方式与软件相同。该平台可通过Web服务器访问,Web服务器托管了包含IPython内核和在Linux操作系统上运行的软件包的Jupyter Notebook设计环境。
3.1. 记录完整的用户响应
硬件API Pynq.Record用于将麦克风输入记录为音频文件。音频驱动(图3中的HwDriver)持续生成音频,但该API只能记录特定时间间隔的音频。因此,Python程序每次连续记录4秒,直到没有更多输入数据为止(图3中的记录循环)。通过这种方式,我们可以记录完整的答案,并将其发送至语音转文本转换模块Google.SpeechToText。最后这一操作可以交错进行,从而在录音过程中以文本格式构建响应。我们还可以通过音频输出和已记录的文件提供答案的回放。
3.2. 查询与回答:音频和文本格式
用户的问题或回答由专家(护理者)以文本形式输入。这对专业人士来说是一种快捷方式,他可以使用自己的语言书写,然后根据用户需求进行翻译。他也可以使用Word文档,每个问题以问号结尾。在这种情况下,问题将被添加到一个文本格式文件的列表中。我们使用 Google.TextToSpeech为每个问题生成对应的mp3音频文件。或者,专业人员可以使用麦克风来录制内容。生成的音频必须通过Subprocess转换为wav文件,并调整为驱动参数(24位,48千赫,双声道)(音频格式见图3)。一种选择是使用Audacity [24], ,但随后需要将其集成到Python程序中,并执行两个转换步骤:先从单声道转立体声,再转为24位。同样可以通过使用 PyPI.PyDub.AudioSegment [31]实现单声道转立体声,以及使用PyPI.SoundFile [32]实现从16位 44千赫到24位48千赫的转换。
3.3. 以适当语言呈现的用户响应文本:语言检测
基于查询,我们可以通过音频接口收集用户回答。这些回答可以被记录为音频文件。除了简单地创建多语言多媒体电子健康记录外,另一种解决方案是将用户响应以文本形式并以适当语言获取。这种格式有助于关键词和特征的搜索。通过使用Google.SpeechToText.recognize_google,并将音频文件和语言作为输入参数,我们可以获得文本形式的内容。然后,可以使用 Google.Translator.translate将该文件翻译成专家所需的语言,以便进一步处理文本格式的记录。以类似方式,我们也可以恢复生成一个音频文件。当使用仅支持英语输入的工具时,这一点尤为重要,我们将在后面进行说明。Google.TextToSpeech.gTTs库将以期望的语速生成wav格式的音频文件。
3.4. 人工智能与实时情绪
IBM Watson [14]提供的用于语音、语言和共情的库基于人工智能和机器学习引擎。部分库可在Python中使用;然而,大多数需要付费访问。因此,我们将体验限制在仅使用语言翻译( LanguageTranslator)和语气分析(ToneAnalyzer)。ToneAnalyzer 库旨在理解情绪和沟通风格。分析库根据情绪和感知参数处理文本文件,以集中关注并提供包含置信度评分的 json(开放标准文件格式)回答,该评分基于6种可选结果:喜悦、愤怒、厌恶、恐惧、悲伤以及积极/消极。在此情况下,实验包括检测所使用的语言,将任何信息转换为该语言,启动专家(问题和建议)与用户 (回答)之间的音频交换,并最终提供情感得分。
4. 实现结果
整个系统已在个人计算机和Xilinx PYNQ‐Z1 开发板 [29],上实现,用于评估目的。该原型使用 Jupyter Notebook 网页界面来完成整个流程——这样我们可以在开发过程中进行修改。然而,最终版本仅提供专家输入查询和建议、接收用户响应以及图形化结果所需的工具。
语言检测(图3中的Language Detection)包括一句欢迎文本,该文本通过 Google.TextToSpeech转换为音频,然后我们使用IBM Watson SpeechToText检测用户回答的语言,返回一个包含多种评估语言的json文件,并选择得分最高的语言用于后续流程。回答收集过程(图3中的Iterator)将一系列问题(每个问题被转换并发送到音频输出)与用户的响应(设备音频输入接收到的每个回答被转换为文本格式)相关联。该过程还会检测用户是否未回答问题,若未回答,则重复该问题;否则继续下一个问题,直至问题列表结束。
考虑到在PYNQ卡上实现的平台性能不如个人计算机,我们在此方向上进行了一些评估测试。我们使用SpeechRecognition(pip3 install speech‐ recognition)[33], 、Google Text to Speech gTTs(pip3 install gTTs)[33], 、json以及IBM Watson 自然语言理解(pip3 install NaturalLanguageUnderstandingV1)[34]库进行信息处理。在个人计算机上,我们还使用 TempFile(pip3 install tempfile)[35]和PyGame(pip3 install pygame)来处理音频文件。在 Pynq上,我们使用SoundFile(pip3 install soundfile)[32]和PyDub(pip3 install pydub) [31]来操作音频文件。此外,我们使用Time创建执行过程中的暂停,并使用Numpy进行图形处理。
我们首先将处理速度与I5处理器进行了比较。结果表明,在最坏情况下,开发板每个问题耗时21秒,而个人计算机为37秒。
本工作的目的是提供一个由专家管理的平台,因为自动共情分析的结果精度不够。此外,用于识别情绪和沟通方式的分析器仅应用于文本回复,而未应用于可能包含用户特定语境语调和所用语言的音频输入。然而,这些额外信息最初可用于帮助专家选择一组后续问题,以更好地识别情绪。为此,我们将用户的回答翻译成英语(IBM Watson 唯一接受的语言),并发送给分析器(图3中的 Watson 分析 ),该分析器返回一个包含基于5种备选结果的置信度评分的json。图4显示了三个输入音频文件的结果(最初以法语录制,然后由平台内部翻译为英语):heureux.wav “I’m so happy to live here”, malheureuse.wav “I hate this world”和 colère.wav “I can’t tolerate this. I don’t understand why people do that”。如示例所示,句子是使用与预期情绪相关的特定词汇构造的。图4顶部的表格显示了输入文件及其对应的输出json、工具生成的情绪得分(喜悦、愤怒、悲伤、恐惧、厌恶)以及预期的情绪。需要注意的是,即使对于非常明确的回答,最高得分也从未超过87%。当预期得分对应于最高得分时,识别率为100%。我们还使用法语进行了附加测试,测试材料为短句录音(wav 音频格式)。结果显示最大估计准确率为87%,这与[28]中提供的结果一致。
除了使用翻译文本外,分析器对于简短回答或缺乏定向问题集的情况,其结果尚不够理想。因此, WEB界面(图4. 底部)已扩展以提供每组问题的结果。需要强调的是,该界面会根据用户选择的语言自动个性化(示例展示了法语使用者专家所看到页面的截图)。我们将每个回答对应的分数附加到图表中(图4.左下),并以饼图形式显示该组问题的计算平均分(图4.右下)。由于本工作未来可结合监督学习模块进行扩展,我们提供了一个包含音频和文本响应的多媒体HER,以及分析器所得结果的图形视图。
5. 结论
在本研究中,我们开发了一种多语言机器人界面,通过提问互动帮助评估老年人的心理健康状况。该原型基于嵌入式设备实现,适用于边缘计算。该平台能够处理来自护理者的文本格式查询,并收集用户回答。该设备还可过滤环境噪声,并可放置于家庭中的任意位置。目前,专家可通过基于 Web的界面创建查询和回答。查询可长期创建和收集,并基于严格的临床随访进行诊断。专家可以提出问题,同时以文本形式接收用户的回答。机器人能够使用适当语言自动与用户交互。系统可处理回答内容,并在专家指导下,将问题与答案引导至期望的治疗方向。为了充分挖掘该原型的优势,必须由专家根据用户(患者)及其病理情况创建并组织一套用于用户随访的问题。因此,诸如语气分析等通用工具,加上语言障碍的存在,仅可作为补充信息使用。由于本研究未来可扩展监督学习模块,我们提供包含音频和文本响应的多媒体电子健康记录,以及IBM Watson获得结果的图形视图。目前该平台已可供专家为每位患者建立电子健康记录数据库。我们期望,在专家与患者的共同协助下,通过该平台创建临床测试,从而进一步改进平台,发展基于语音的自动护理及病理协议。

















 953
953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









