




1 单选题(每题 2 分,共 30 分)
第1题 已知小写字母 b 的ASCII码为98,下列C++代码的输出结果是( )。
- #include <iostream>
- using namespace std;
- int main() {
- char a = 'b' ^ 4;
- cout << a;
- return 0;
- }
A. b B. bbbb C. f D. 102
解析:答案C。'b'为字符型,等人价整型98,'b' ^ 4等价98 ^ 4 = 0b01100010 ^ 0b00000100 = 0b01100110 = 102。char a表示a为字符型,102将转换为字符'f'。所以C.正确。故选C。
第2题 已知 a 为 int 类型变量, p 为 int * 类型变量,下列赋值语句不符合语法的是( )。
A. *(p + a) = *p; B. *(p - a) = a; C. p + a = p; D. p = p + a;
解析:答案C。本题考察的是指针运算的合法性,关键点在于指针变量是否可以用于赋值表达式的左侧。A. *(p + a) = *p; 合法:*(p + a) 是对指针 p 偏移 a 后的地址解引用,并赋值 *p 的值,这是合法的指针运算和赋值操作。B. *(p - a) = a; 合法:*(p - a) 是对指针 p 偏移 -a 后的地址解引用,并赋值为 a,这也是合法的指针运算和赋值操作。C. p + a = p; 非法:p + a 是一个临时计算的指针值(地址值),不能出现在赋值语句的左侧(即不能作为左值),编译器会报错,因为表达式 p + a 的结果是不可修改的临时对象。D. p = p + a; 合法:对指针变量 p 进行偏移运算(p + a),并将结果赋值给 p,这是合法的指针运算和赋值操作。故选C。
第3题 下列关于C++类的说法,错误的是( )。
A. 如需要使用基类的指针释放派生类对象,基类的析构函数应声明为虚析构函数。
B. 构造派生类对象时,只调用派生类的构造函数,不会调用基类的构造函数。
C. 基类和派生类分别实现了同一个虚函数,派生类对象仍能够调用基类的该方法。
D. 如果函数形参为基类指针,调用时可以传入派生类指针作为实参。
解析:答案B。若基类析构函数未声明为虚析构函数,通过基类指针释放派生类对象时会导致内存泄漏(仅调用基类析构函数,派生类部分未被释放),虚析构函数确保多态性析构的正确调用,所以A.正确。构造派生类对象时,会先调用基类构造函数,再调用派生类构造函数,若基类未定义默认构造函数,派生类构造时必须显式初始化基类,所以B.错误。派生类通过 base:: 显式调用基类虚函数(如 base::Method()),或通过基类指针/引用调用(覆盖后仍可访问基类实现),基类指针可以指向派生类对象(多态性),因此传入派生类指针作为基类指针的实参是合法的,所以D.正确。故选B。
第4题 下列C++代码的输出是( )。
- #include <iostream>
- using namespace std;
- int main() {
- int arr[5] = {2, 4, 6, 8, 10};
- int * p = arr + 2;
- cout << p[3] << endl;
- return 0;
- }
A. 6 B. 8
C. 编译出错,无法运行。 D. 不确定,可能发生运行时异常。
解析:答案D。arr是数组arr的首地址,即地址指向下标0,也就是元素2这个位置,int *p = arr + 2,指针p指向arr+2,即指向下标2,也就是元素6这个位置,这个位置相当于p[0],所以p[3]已超arr的范围,结果不确定,所以D.正确。故选D。
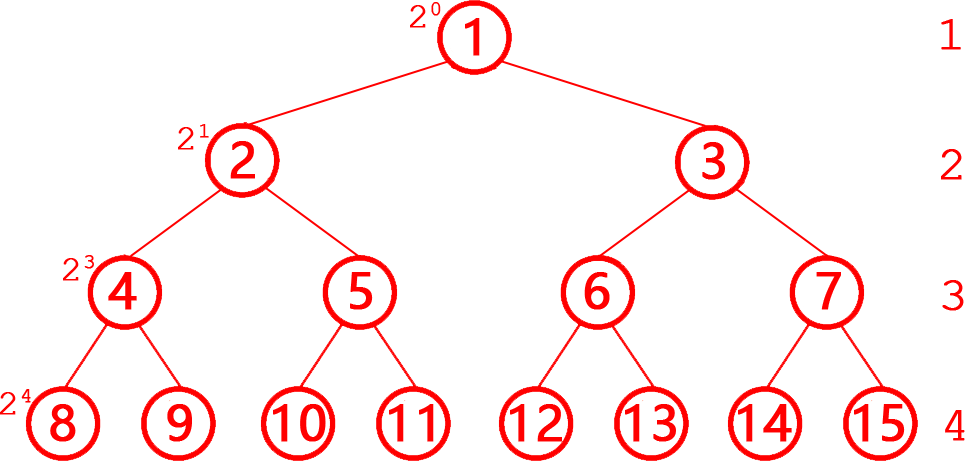
第5题 假定只有一个根节点的树的深度为1,则一棵有N个节点的完全二叉树,则树的深度为( )。
A. ⌊log₂(N)⌋+1 B. ⌊log₂(N)⌋ C. ⌈log₂(N)⌉ D. 不能确定
解析:答案A。完全二叉树每行的第1个节点的编号=为2层号-1,层号=log₂编号+1,对整层的其他节点:层号=⌊log₂编号⌋+1,对最后一层就是深度(参考下图),所以对一棵有N个节点的完全二叉树,如根节点的树的深度为1,则树的深度=⌊log₂N⌋+1。故选A。
第6题 对于如下图的二叉树,说法正确的是( )。
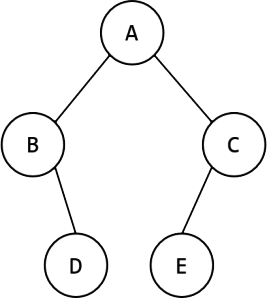
A. 先序遍历是 ABDEC 。 B. 中序遍历是 BDACE 。
C. 后序遍历是 DBCEA 。 D. 广度优先遍历是 ABCDE 。
解析:答案D。先序遍历是根-左树-右树,中序遍历是左树-根-右树,后序遍历是左树-右树-根,广度优先遍历是按层从上到下,每层从左到右。对本题图中二叉树:先序遍历是ABDCE,A.错误;中序遍历是BDAEC,B.错误;后序遍历是DBECA,C.错误,广度优先遍历是ABCDE,D.正确。故选D。
第7题 图的存储和遍历算法,下面说法错误的是( )。
A. 图的深度优先遍历须要借助队列来完成。
B. 图的深度优先遍历和广度优先遍历对有向图和无向图都适用。
C. 使用邻接矩阵存储一个包含𝑣个顶点的有向图,统计其边数的时间复杂度为𝑂(𝑣²)。
D. 同一个图分别使用出边邻接表和入边邻接表存储,其边结点个数相同。
解析:答案A。深度优先遍历(DFS)通常使用栈(递归或显式栈)实现,而广度优先遍历(BFS)才需要队列,所以A.错误。两种遍历算法均适用于有向图和无向图,仅访问顺序和实现细节可能不同,所以正确。包含𝑣个顶点的有向图的邻接矩阵需要遍历整个𝑣×𝑣矩阵才能统计边数,时间复杂度为 𝑂(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









