




1 单选题(每题 2 分,共 30 分)
第1题 下列哪一项不是面向对象编程(OOP)的基本特征?( )
A. 继承 (Inheritance) B. 封装 (Encapsulation)
C. 多态 (Polymorphism) D. 链接 (Linking)
解析:答案D。面向对象编程的基本特征包含封装、继承、多态和抽象四大核心要素,这四大特征共同构成了代码组织的核心范式,有效提升了程序的可维护性、扩展性和复用性。所以D.不是。故选D。
第2题 为了让 Dog 类的构造函数能正确地调用其父类 Animal 的构造方法,横线线处应填入( )。
- class Animal:
- def __init__(self, name: str):
- self.name = name
- print("Animal created")
- def speak(self) -> None:
- print("Animal speaks")
- class Dog(Animal):
- ______________________________
- print("Dog created")
- def speak(self) -> None:
- print("Dog barks")
- if __name__ == "__main__":
- animal: Animal = Dog("Rex", "Labrador")
- animal.speak()
| A. |
|
| B. |
|
| C. |
|
| D. |
|
解析:答案A。继承父类构造函数:子类 Dog 需要通过 super().__init__(name) 显式调用父类 Animal 的构造函数,以确保执行父类构造函数(如 self.name = name 和打印 "Animal created")被执行。扩展子类属性:Dog 类新增了 breed 属性,需要在子类构造函数中初始化 self.breed = breed。所以A.的代码完全符合上述逻辑,而其他选项(B.、C.、D.)要么遗漏了 super().__init__(),要么语法不完整。故选A。
第3题 代码同上一题,代码animal.speak()执行后输出结果是( )。
A. 输出 Animal speaks B. 输出 Dog barks C. 编译错误 D. 程序崩溃
解析:答案B。Dog 实例化时,通过 super().__init__("Rex") 调用父类 Animal 的构造函数,执行 print("Animal created") 并初始化 name 属性。Dog 的构造函数继续执行 print("Dog created")。最后调用 animal.speak(),由于 Dog 重写了 speak 方法,输出 "Dog barks",所以输出 Dog barks。故选B。
第4题 以下Python代码执行后其输出是( )。
- from collections import deque
- stack = []
- queue = deque()
- # 元素入栈/入队(1, 2, 3)
- for i in range(1, 4):
- stack.append(i)
- queue.append(i)
- print(f"{stack[-1]} {queue[0]}")
A. 1 3 B. 3 1 C. 3 3 D. 1 1
解析:答案B。栈和队列的操作:栈(stack)是先进后出(FILO)结构,本题用列表模拟,append(i) 依次添加 1, 2, 3,因此 stack[-1](栈顶元素,列表最后的元素)为 3。队列(deque)是先进先出(FIFO)结构, append(i) 依次添加 1, 2, 3,因此 queue[0](队首元素)为 1。所以输出结果为f"{stack[-1]} {queue[0]}"的结果为 "3 1"。故选B。
第5题 在一个使用列表实现的循环队列中,front 表示队头元素的位置(索引),rear 表示队尾元素的下一个插入位置(索引),队列的最大容量为 maxSize。那么判断队列已满的条件是( )
A. rear == front B. (rear + 1) % maxSize == front
C. (rear - 1 + maxSize) % maxSize == front D. (rear - 1) == front
解析:答案B。在循环队列中,判断队列已满的条件需要满足以下两点:队尾指针(rear)的下一个位置是队头指针(front),即 rear 即将追上 front。为了避免rear == front时出现歧义(此时队列可能为空也可能为满),通常使用 (rear + 1) % maxSize == front 来判断是否已满。rear == front用于判断空队列,所以A.错误。(rear - 1 + maxSize) % maxSize == front:
等价于 rear - 1 == front,C.、D.相同,所以两者都错。故选B。
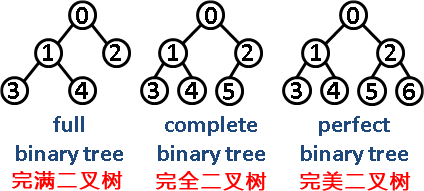
第6题 在二叉树中,只有最底层的节点未被填满,且最底层节点尽量靠左填充的是( )。
A. 完美二叉树 B. 完全二叉树 C. 完满二叉树 D. 平衡二叉树
解析:答案B。完美二叉树(Perfect Binary Tree):一个深度为k(>=1)且有2^(k-1) - 1个结点的二叉树称为完美二叉树。(注:国内的数据结构教材大多翻译为"满二叉树")。完全二叉树(Complete Binary Tree):完全二叉树从根结点到倒数第二层满足完美二叉树,最后一层可以不完全填充,其叶子结点都靠左对齐。完满二叉树(Full Binary Tree):所有非叶子结点的度都是2。(只要你有孩子,你就必然是有两个孩子。)所以B.正确。故选B。
第7题 在使用数组(列表)表示完全二叉树时,如果一个节点的索引为𝑖(从0开始计数),那么其左子节点的索引通常是( )。
A.(i-1)/2 B.i+1 C.i+2 D.2*i+1
解析:答案D。在使用数组表示完全二叉树时,节点的索引从0开始,其子节点的索引计算规则为:左子节点的索引为2*i + 1,右子节点的索引为2*i + 2。例如:根节点 i = 2:左子节点 i = 2*2 + 1 = 5,右子节点 i = 2*2 + 2 = 6,D.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2244
2244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









