



MySQL体系结构技术解析
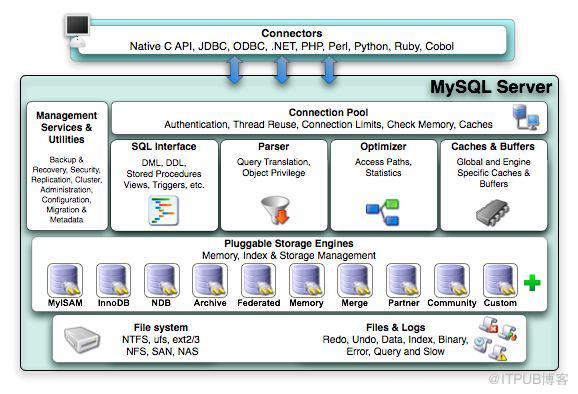
MySQL 服务端采用分层设计架构,各层级具有独立职责且通过标准化接口协同工作,形成高效的数据处理流水线。这种分层架构不仅确保了组件的解耦与可扩展性,还为不同场景下的性能优化提供了明确的技术路径。以下将从层级职责与协同流程两个维度展开分析。
层级职责解析
连接层作为 MySQL 与客户端交互的入口,负责建立和管理网络连接,支持多种编程语言接口(如 C、Java、Python 等)的通信协议转换。该层通过 TCP/IP 协议接收客户端请求,执行身份验证(包括用户名密码校验、SSL 加密配置验证)和连接权限检查,并为通过验证的连接分配线程资源。在高并发场景下,连接层可通过线程池机制复用线程资源,避免频繁创建销毁线程带来的性能开销。
服务层是 MySQL 的核心处理中枢,包含 SQL 解析器、查询优化器、查询缓存等关键组件。SQL 解析器通过词法分析将 SQL 语句分解为语法树,再经语法规则校验确保合法性;查询优化器基于成本模型生成最优执行计划,例如选择合适的索引、调整表连接顺序;查询缓存则存储常用查询结果集,在收到相同 SQL 时直接返回缓存数据(需注意 MySQL 8.0 已移除该功能,实际应用中需通过应用层缓存替代)。此外,服务层还实现了事务管理(ACID 特性保障)、存储过程、触发器等高级功能。
存储引擎层负责数据的物理存储与检索,采用插件式架构支持多种存储引擎(如 InnoDB、MyISAM、Memory 等)。InnoDB 作为 MySQL 5.5 后的默认存储引擎,通过多版本并发控制(MVCC)实现高并发读写,并利用 redo log(重做日志)和 undo log(回滚日志)保障事务的持久性与原子性;MyISAM 则以表级锁和全文索引为特点,适用于读密集型场景。存储引擎层通过统一的接口与服务层交互,屏蔽了底层文件系统的实现差异。
存储层作为最底层组件,负责将数据以文件形式存储在操作系统中,包括数据文件(如 .ibd、.MYD)、索引文件(如 .MYI)及日志文件(如 binlog、error log)。其中二进制日志(binlog)记录所有数据变更操作,是数据备份与主从复制的核心依据;错误日志则记录服务器启动、运行及关闭过程中的关键事件,为故障排查提供重要线索。
以 SELECT * FROM users WHERE id = 1; 为例,解析 MySQL 各层协同工作流程:
-
连接建立:客户端通过连接层与 MySQL 服务器建立 TCP 连接,完成用户身份验证与权限检查;
-
SQL 解析:服务层将 SQL 语句解析为语法树,验证语法正确性后交由查询优化器;
-
执行计划生成:优化器分析表结构与索引信息(如 users 表的 id 主键索引),生成通过索引查找的执行计划;
-
数据检索:存储引擎层(InnoDB)根据执行计划,通过 B+ 树索引定位 id=1 的数据行,并返回给服务层;
-
结果返回:服务层将检索结果封装为协议格式,经连接层传输至客户端,同时释放线程资源。111111231231313
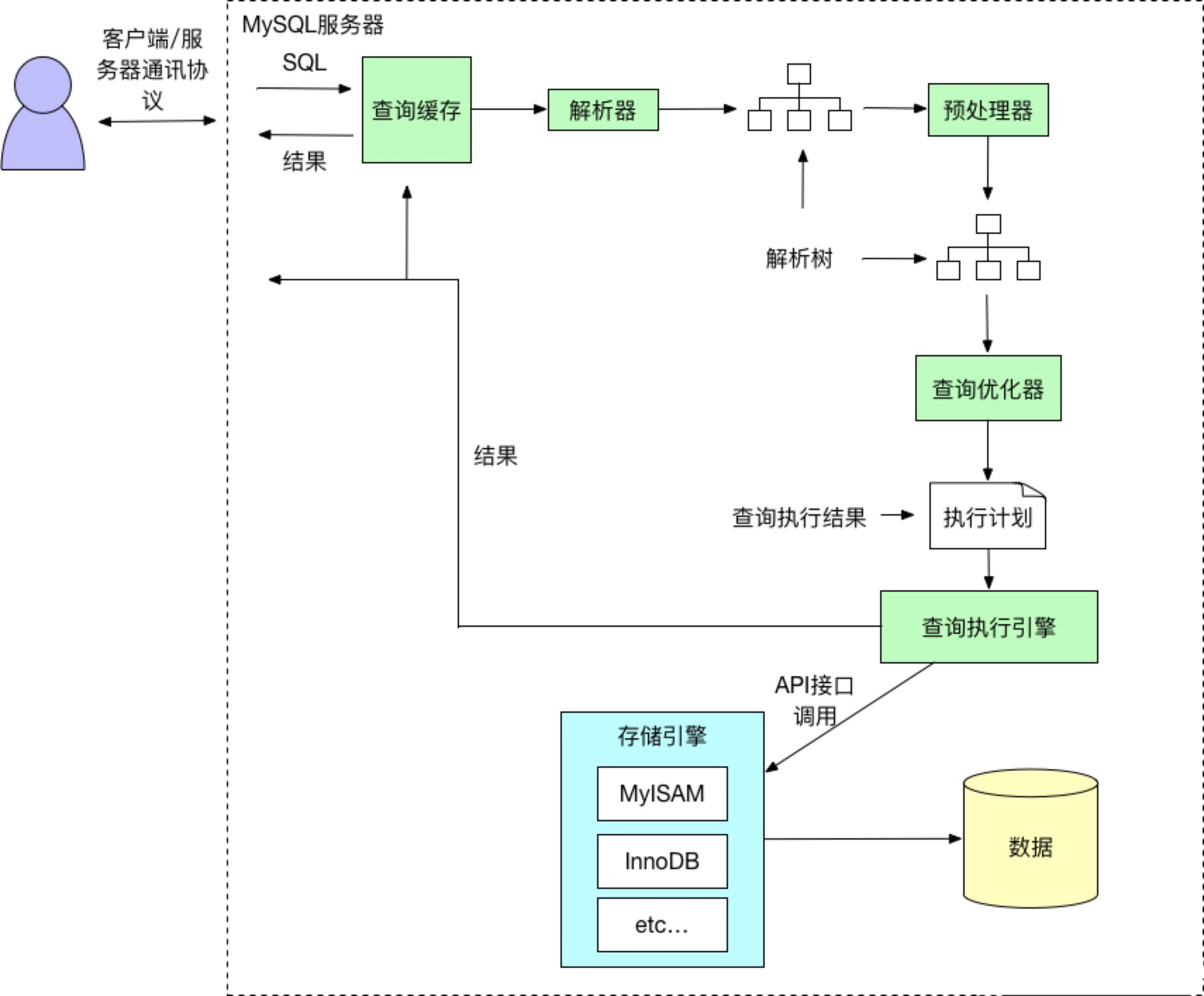
关键技术节点:在执行过程中,InnoDB 存储引擎会先检查缓冲池(Buffer Pool)是否存在目标数据,命中时直接返回以减少磁盘 I/O;未命中则从磁盘读取并缓存。此机制使热点数据访问性能提升 10-100 倍,是 MySQL 性能优化的核心抓手。
这种分层架构的优势在于各组件职责明确,可针对不同层级进行独立优化。例如通过优化连接层的线程池配置提升并发处理能力,调整服务层的查询语句结构减少全表扫描,或选择合适的存储引擎匹配业务场景需求。理解各层级的技术细节与协作机制,是进行 MySQL 性能调优与架构设计的基础。
存储引擎核心技术原理
MySQL 存储引擎是数据库架构中的核心组件,负责数据的存储、检索和管理操作。其最显著的特性在于表级选择机制,即同一数据库中不同表可根据业务需求选择不同存储引擎,实现存储策略的精细化配置。这种设计使 MySQL 能够同时满足事务处理、高并发读取、空间数据存储等多样化场景需求,例如订单表采用 InnoDB 保证事务一致性,而日志表可选用 MyISAM 优化写入性能。
存储引擎的 SQL 操作体系
1. 存储引擎查看指令
系统级引擎查询
通过查询 information_schema 系统数据库可获取 MySQL 服务器支持的所有存储引擎及其状态信息:
SELECT ENGINE, SUPPORT, COMMENT
FROM information_schema.ENGINES
ORDER BY SUPPORT DESC;
-
ENGINE:存储引擎名称(如 InnoDB、MyISAM、MEMORY)
-
SUPPORT:支持级别(DEFAULT 表示默认引擎,YES 表示支持,NO 表示不支持)
-
COMMENT:引擎功能描述(如"InnoDB supports transactions, row-level locking, and foreign keys")
该查询读取 MySQL 系统元数据,通过解析服务器启动时加载的引擎模块信息,聚合生成支持列表。系统表 information_schema.ENGINES 本质是内存中的动态视图,其数据来源于存储引擎接口注册的元数据信息。
表级引擎查询
查看特定表使用的存储引擎:
SELECT TABLE_NAME, ENGINE
FROM information_schema.TABLES
WHERE TABLE_SCHEMA = 'your_database' AND TABLE_NAME = 'your_table';
快捷指令:使用 SHOW TABLE STATUS 命令获取更详细的表存储信息:
SHOW TABLE STATUS LIKE 'your_table'\G
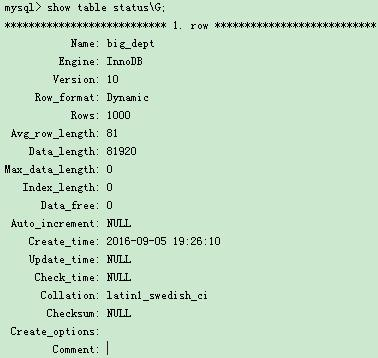
关键参数说明:执行结果中的 Engine 字段显示当前表使用的存储引擎,Row_format 和 Data_length 等字段提供存储格式与空间占用信息,可辅助评估存储引擎选择合理性。
2. 存储引擎指定与修改
创建表时指定引擎
通过 ENGINE 参数在 CREATE TABLE 语句中显式指定存储引擎
CREATE TABLE orders (
order_id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT NOT NULL,
order_time DATETIME DEFAULT CURRENT_TIMESTAMP,
total_amount DECIMAL(10,2) NOT NULL,
INDEX idx_user (user_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
ENGINE=InnoDB 明确指定表使用 InnoDB 引擎,若省略该参数,系统将使用 default-storage-engine 配置项指定的默认引擎(MySQL 5.5.5 起默认值为 InnoDB)。
修改表存储引擎
使用 ALTER TABLE 语句可动态变更表的存储引擎:
ALTER TABLE legacy_logs ENGINE=MyISAM;
注意事项:修改存储引擎会导致表结构重建,可能引发数据类型转换、索引重构等操作,生产环境执行前需评估:
-
表锁定期间的业务影响
-
不同引擎间不兼容特性(如外键、事务)的处理方案
-
数据迁移前后的一致性验证
存储引擎选择的技术考量
存储引擎的选择需基于业务特性进行多维度评估,核心考量因素包括:
-
事务需求:需 ACID 特性支持时必须选择 InnoDB
-
读写模式:读密集场景可考虑 MyISAM 或 Memory 引擎
-
数据生命周期:临时数据适合 Memory 引擎,历史归档数据可选用 Archive 引擎
-
索引特性:空间数据需使用 MyISAM 或 InnoDB 的空间索引支持
MySQL 的模块化存储引擎架构,通过统一的接口规范实现了不同存储引擎的即插即用。这种设计使数据库管理员能够针对特定业务场景定制存储策略,在性能、功能与可靠性之间取得最优平衡,这也是 MySQL 能够在各类应用场景中保持广泛适用性的关键技术基础。
主流存储引擎技术详解
InnoDB 存储引擎
引擎定位:MySQL 默认存储引擎,专为事务处理和高并发场景设计,提供 ACID 事务支持和行级锁定机制,适用于读写并重的业务系统。
核心特性:
-
事务 ACID 特性:通过多版本并发控制(MVCC)和 redo/undo 日志实现事务的原子性、一致性、隔离性和持久性。以转账案例为例,当执行账户 A 向账户 B 转账 100 元的事务时:
-
原子性:通过 undo 日志确保转账过程中若发生故障,所有操作可回滚至初始状态;
-
一致性:事务提交前,A 账户余额减少 100 元与 B 账户余额增加 100 元的操作要么全部完成,要么全部失败;
-
隔离性:通过行级锁和 MVCC 机制,保证多个并发事务间的操作相互隔离,避免脏读、不可重复读和幻读;
-
持久性:事务提交后,通过 redo 日志将数据变更持久化到磁盘,即使系统崩溃也可恢复。
-
-
行锁并发优势:支持行级锁定,允许多个事务同时更新不同行数据。例如,事务 T1 更新 ID=1 的行,事务 T2 可同时更新 ID=2 的行,无需等待 T1 释放锁,显著提升并发处理能力。
存储结构:
-
物理存储:数据与索引存储在 .ibd 文件中,包含表结构、用户数据和所有索引(聚簇索引与二级索引)。
-
逻辑存储结构:采用层次化设计,从高到低依次为:表空间(Tablespace)→ 段(Segment)→ 区(Extent)→ 页(Page)→ 行(Row)。其中,页是最小存储单元,默认大小为 16KB,包含数据页、索引页、undo 页等多种类型。
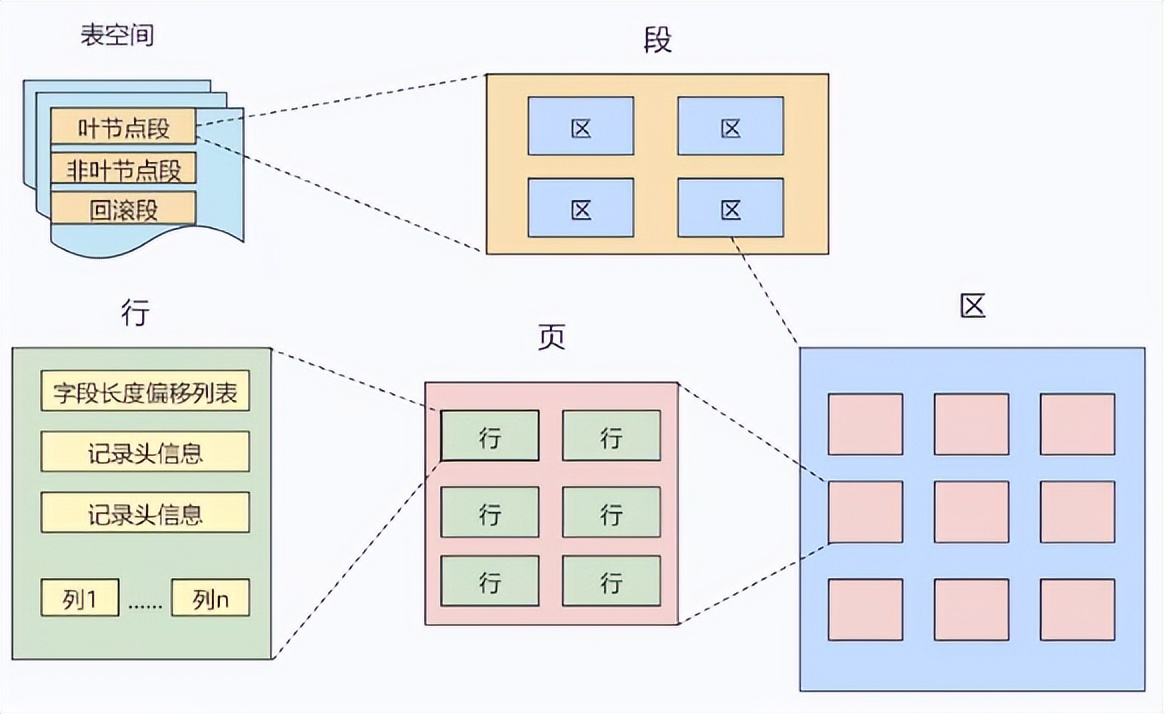
在 MySQL 数据目录下,InnoDB 表对应 account.frm(表结构,MySQL 8.0 后合并至 .ibd)和 account.ibd(数据与索引)两个文件。
ibd文件需要使用 ibd2sdi 工具解析
ibd2sdi /var/lib/mysql/test/account.ibd
输出结果包含表空间 ID、表结构定义、索引信息等关键元数据。
MyISAM 存储引擎
引擎定位:MySQL 早期默认存储引擎,不支持事务和行级锁,适用于读密集型、数据一致性要求不高的场景(如日志存储、静态数据查询)。
核心特性:
-
表锁机制:采用全表锁定,当执行写操作(INSERT/UPDATE/DELETE)时会锁定整个表,导致其他读写操作阻塞。例如,事务 T1 更新表中某行时,事务 T2 读取该表需等待 T1 释放锁,并发性能较差。
-
文件分离存储:数据存储在 .MYD(MyData)文件,索引存储在 .MYI(MyIndex)文件,表结构存储在 .frm 文件。
存储结构优缺点:
-
优点:文件分离设计便于单独备份数据或索引,且索引文件可被不同数据库实例共享;
-
缺点:缺乏事务支持,数据崩溃后恢复困难;表锁机制导致写操作并发能力弱。
MyISAM 表对应 account.frm(表结构)、account.MYD(数据)和 account.MYI(索引)三个文件。
Memory 存储引擎
引擎定位:数据存储在内存中的临时存储引擎,适用于临时数据缓存、高频访问的小表查询(如会话状态、临时计算结果)。
核心特性:
-
数据易失性:数据仅存在于内存中,数据库重启或崩溃后数据丢失,需通过持久化机制(如定时dump到磁盘)保障数据安全。
-
存储限制:支持 Hash 和 B+Tree 索引,默认使用 Hash 索引,查找速度快但不支持范围查询;表大小受 max_heap_table_size 和 tmp_table_size 参数限制。
适用场景限制:
-
仅适用于临时数据存储,不适合持久化业务数据;
-
不支持 TEXT/BLOB 类型字段,且每行数据长度不能超过行大小限制。
创建 Memory 表示例:
CREATE TABLE session_data (
id INT PRIMARY KEY,
data VARCHAR(255)
) ENGINE=MEMORY;
数据持久性测试:重启 MySQL 服务后,查询 session_data 表,结果为空表,验证数据易失性。
对比总结:InnoDB 凭借事务支持和行锁机制成为主流选择,MyISAM 因兼容性仍用于特定读密集场景,Memory 适合临时数据缓存。实际应用中需根据事务需求、并发量和数据持久性要求选择存储引擎。
存储引擎技术对比与选型策略
MySQL 存储引擎的技术特性差异直接决定其在不同业务场景下的适用性,需从核心功能支持、性能表现及架构特性三个维度进行系统性评估。以下通过结构化分析框架,结合典型业务场景需求,构建存储引擎选型决策体系,并针对高频技术对比考点进行深度解析。
核心技术特性对比分析
存储引擎的底层实现机制差异主要体现在事务支持、锁策略、索引结构及存储架构四个关键维度,这些特性共同决定了其数据处理能力与适用场景:
事务与ACID属性支持
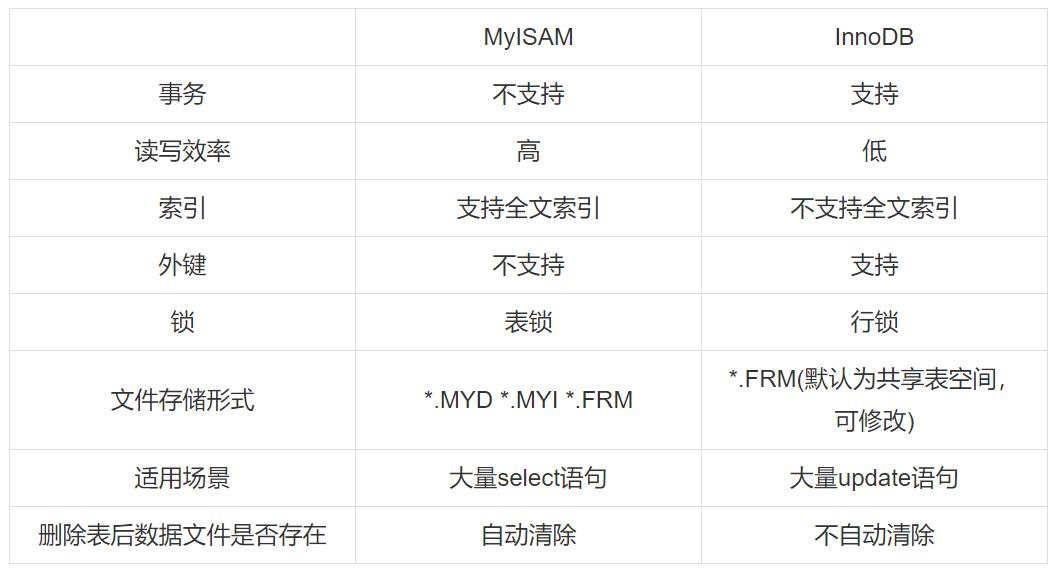
InnoDB 作为 MySQL 默认存储引擎,通过多版本并发控制(MVCC)机制实现完整的 ACID 事务支持,其事务隔离级别可通过 SET TRANSACTION ISOLATION LEVEL 命令配置,默认采用可重复读(Repeatable Read)级别,并通过间隙锁(Gap Lock)防止幻读现象。相比之下,MyISAM 引擎完全不支持事务,无法保障数据操作的原子性与一致性,在涉及多表更新的业务场景中存在数据不一致风险。
锁机制与并发性能
InnoDB 实现了行级锁与表级锁的混合锁策略,对于索引条件匹配的单行操作仅施加行锁,大幅提升高并发写入场景下的吞吐量;而 MyISAM 仅支持表级锁,任何写操作都会阻塞整张表的读写请求,在写密集型业务中性能显著劣化。实际测试数据显示,当并发写入线程数达到 20 时,InnoDB 的吞吐量约为 MyISAM 的 8-10 倍,锁等待时间降低 90% 以上。
索引与存储结构
InnoDB 采用聚簇索引(Clustered Index)结构,将主键索引与数据行物理存储紧密结合,二级索引仅存储主键指针,这种设计在主键查询场景下可避免二次查找,查询效率提升 30%-50%;MyISAM 则使用非聚簇索引,索引与数据文件分离存储,所有索引均指向数据文件的物理偏移量。此外,InnoDB 支持自适应哈希索引(Adaptive Hash Index),可将热点数据的索引查询转化为哈希查找,平均响应时间缩短至 1μs 级别。
崩溃恢复与数据安全
InnoDB 通过 redo log(重做日志)和 undo log(回滚日志)实现崩溃安全(Crash-Safe)能力,确保数据库异常重启后的数据一致性。其双写缓冲(Double Write Buffer)机制可有效避免部分写失效(Partial Write)问题,而 MyISAM 缺乏完善的崩溃恢复机制,在意外宕机时可能导致索引损坏或数据丢失,需通过 myisamchk 工具进行修复。
典型业务场景适配策略
不同业务场景的核心诉求差异要求针对性选择存储引擎,以下结合电商、日志系统、缓存服务三类典型场景,分析引擎选型逻辑及替代技术方案:
电商订单系统
订单系统作为核心交易链路,对事务一致性、数据完整性及并发处理能力有极高要求。InnoDB 的事务支持与行级锁特性使其成为首选方案,具体实施中需注意:
-
采用自增主键优化聚簇索引存储效率
-
通过合理的索引设计(如联合索引 (user_id, order_time))减少锁冲突
-
配置适当的 innodb_buffer_pool_size(建议为服务器物理内存的 50%-70%)提升缓存命中率
当订单数据量达到千万级以上时,可引入分库分表中间件(如 Sharding-JDBC)实现水平扩展,同时结合 Redis 缓存热点商品订单信息,将查询请求响应时间控制在 10ms 以内。
系统日志存储
日志数据具有写入密集、查询模式简单(多为按时间范围查询)的特点,MyISAM 的高插入性能在此场景下具备优势,但其不支持事务的缺陷可通过业务层保证数据完整性。更优方案是采用 Archive 引擎,该引擎通过行级压缩将存储占用降低 70%-80%,适合保存历史归档日志。对于需要实时日志分析的场景,可考虑 ELK 栈(Elasticsearch + Logstash + Kibana)替代方案,利用 Elasticsearch 的分布式架构和倒排索引,实现日志数据的实时检索与聚合分析。
商品缓存服务
传统关系型数据库在高频读场景下存在性能瓶颈,此时应采用 Redis 作为替代方案。Redis 基于内存的存储架构使其读操作响应时间可达亚毫秒级,支持多种数据结构(如 Hash、Sorted Set)满足商品库存、价格等信息的缓存需求。实际应用中需设计合理的缓存更新策略:
-
采用 "Cache-Aside" 模式,更新数据库后主动失效缓存
-
设置合理的过期时间(TTL),通过惰性删除与定期删除结合的方式释放内存
-
对热点商品实施缓存预热,避免缓存穿透与雪崩问题
高频面试考点解析:InnoDB 与 MyISAM 核心区别
-
事务支持:InnoDB 支持 ACID 事务,MyISAM 完全不支持
-
锁机制:InnoDB 实现行级锁与表级锁,MyISAM 仅支持表级锁
-
索引结构:InnoDB 使用聚簇索引,MyISAM 采用非聚簇索引
-
崩溃恢复:InnoDB 通过 redo/undo log 实现崩溃安全,MyISAM 需手动修复
-
存储占用:InnoDB 存储空间更大(约为 MyISAM 的 2-3 倍),但支持数据压缩
-
并发性能:InnoDB 在写并发场景下性能优势显著,MyISAM 适合读密集非事务场景
选型决策框架
存储引擎选型需综合评估业务特性、数据量、访问模式三大核心要素,建立四步决策流程:
-
需求分析:明确是否需要事务支持、并发控制级别及数据安全要求
-
性能测试:在模拟生产环境下对比不同引擎的 TPS/QPS 指标
-
成本评估:考虑存储占用、内存消耗及运维复杂度
-
扩展性规划:预留未来 1-3 年的数据增长空间,评估水平扩展可行性
在实际架构设计中,单一存储引擎往往难以满足所有场景需求,应构建多引擎协同架构:核心交易数据使用 InnoDB 保证一致性,非核心业务数据采用 MyISAM/Archive 优化存储成本,高频访问数据通过 Redis 缓存加速,形成多层次的数据存储体系。
选型注意事项
-
避免在同一数据库实例中混用多种存储引擎,可能导致性能不稳定
-
MyISAM 已在 MySQL 8.0 版本中被标记为 deprecated,新项目应优先选择 InnoDB
-
对于只读数据,可通过创建 MyISAM 从表实现查询分流,降低主库压力
-
定期监控引擎状态指标(如 InnoDB 的 innodb_row_lock_waits、MyISAM 的 Key_read_hit),及时优化调整
通过上述分析可见,存储引擎选型本质是对业务需求与技术特性的匹配过程,需在功能、性能与成本之间寻找最佳平衡点。随着分布式数据库技术的发展,NewSQL 数据库(如 TiDB、CockroachDB)结合了传统关系型数据库的事务支持与 NoSQL 的横向扩展能力,正在成为大规模数据场景下的新兴选择,值得持续关注其技术演进与实践案例。

















 3278
3278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









