



为什么你的SQL查询变慢了
当用户抱怨系统越来越卡,当数据库服务器CPU占用率飙升到100%,当一条简单的查询需要等待10秒以上——这些问题的背后,往往指向同一个核心:SQL性能优化。作为数据库爱好者和优快云博主,我见过太多开发者因为忽视索引优化,导致系统在数据量增长后陷入性能泥潭。今天这篇文章,我们将从索引基础到性能分析工具,手把手带你掌握MySQL性能调优的核心技能,让你的SQL查询从"龟速"变"火箭"。
SQL优化核心前提
优化逻辑
进行SQL优化的首要步骤是定位优需化的SQL语句,而定位的关键在于掌握每条SQL的执行性能。想象一下,你不可能在不知道哪辆车出故障的情况下进行维修——SQL优化也是如此。只有明确了SQL的执行情况,才能精准开展优化工作。
优化重点
SQL语句包含insert、update、delete、select四类,其中查询语句(select)是
优化的核心对象。根据MySQL官方统计,在大多数业务系统中,查询操作占比超过70%,而索引对查询性能的提升可达10倍甚至100倍。因此在学习完索引基础内容后,需重点掌握SQL性能分析工具的使用。
索引核心操作(以TB_user表为例)
索引操作是SQL优化的基础,包括查看、创建、删除三种核心操作,实操均基于MySQL的InnoDB引擎(默认索引结构为B+树)。
什么是索引
索引就像图书馆的藏书目录,没有索引时,查找数据需要逐行扫描(全表扫描),就像在图书馆里一本本翻书找内容;而有了索引,数据库可以快速定位数据位置,大大提高查询效率。
MySQL InnoDB引擎默认使用B+树索引,这种结构能让数据查询像查字典一样高效。下面这张图展示了B+树的层级结构,顶层是根节点,中间是枝节点,最底层是存储数据的叶子节点,所有叶子节点通过指针连接,形成有序链表:
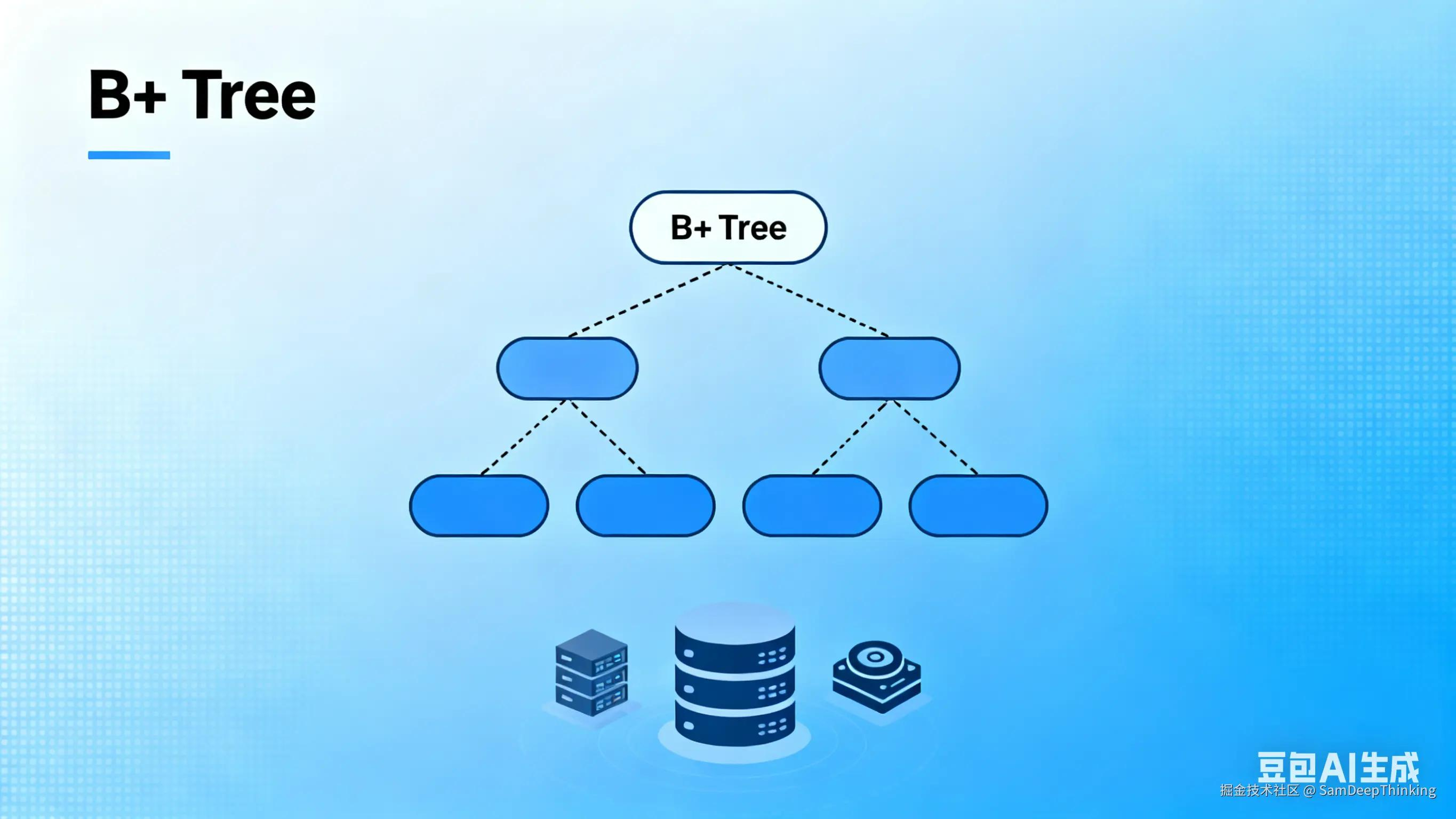
查看索引
语法:show index from 表名 [\G],其中\G参数可将查询结果由列展示转为行展示,更便于查看复杂表结构的索引信息。
案例:查看TB_user表的索引
-- 标准列展示格式
show index from TB_user;
-- 行展示格式(适合复杂表结构)
show index from TB_user \G
初始结果显示该表仅存在主键索引(基于ID字段),因为ID字段是表的主键,MySQL会自动创建主键索引。
创建索引
根据字段特性和业务需求,可创建常规索引、唯一索引、联合索引三类,索引命名规范为“idx_表名_字段名”(idx为index的简写)。
常规索引
适用于字段值可重复的场景,例如用户表的name字段。
语法:create index 索引名 on 表名(字段名)
案例:为name字段创建常规索引
-- 创建索引
create index idx_user_name on TB_user(name);
-- 验证结果(此时应能看到新创建的name字段索引)
show index from TB_user;
唯一索引
适用于字段值非空且唯一的场景,例如手机号、邮箱等字段,需添加unique关键字。
语法:create unique index 索引名 on 表名(字段名)
案例:为phone(手机号,非空且唯一)创建唯一索引
-- 创建唯一索引
create unique index idx_user_phone on TB_user(phone);
-- 注意:如果表中已有重复的phone值,创建会失败
-- 错误提示:Duplicate entry '13800138000' for key 'idx_user_phone'
联合索引
适用于需通过多个字段联合查询的场景,例如"查询职业为程序员且年龄在25-30岁的用户"。字段顺序对查询性能有重大影响,这就是常说的"最左前缀原则"。
语法:create index 索引名 on 表名(字段1, 字段2, 字段3)
案例:为profession、age、status创建联合索引
-- 创建联合索引(注意字段顺序)
create index idx_user_profession_age_status on TB_user(profession, age, status);
-- 查看索引字段顺序
show index from TB_user where Key_name = 'idx_user_profession_age_status';
执行结果中的SEQ_IN_INDEX列会显示字段顺序:profession为1,age为2,status为3。
联合索引顺序的奥秘
联合索引的B+树结构中,字段顺序决定了索引的使用效率。以下面的联合索引(profession, age, status)为例,其结构类似下图:
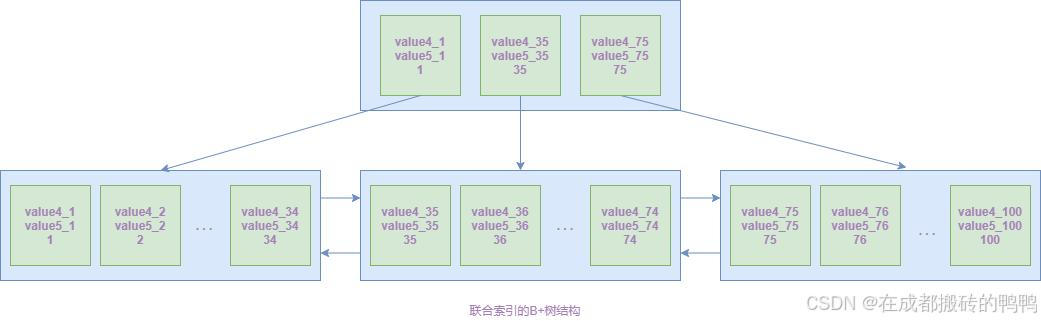
最左前缀原则:索引只能从最左侧开始连续使用。例如:
-
where profession = '程序员' → 可用索引
-
where profession = '程序员' and age = 28 → 可用索引
-
where age = 28 and status = 1 → 无法使用索引(跳过了左侧的profession字段)
删除索引
当索引不再被使用或影响写入性能时,需要删除冗余索引。
语法:drop index 索引名 on 表名
案例:删除email字段的索引
-- 删除索引
drop index idx_user_email on TB_user;
-- 验证结果(idx_user_email应已消失)
show index from TB_user;
注意事项:
-
删除主键索引需使用alter table 表名 drop primary key
-
删除索引前,建议先通过show index确认索引名称
-
频繁更新的字段不宜创建过多索引,因为索引会增加写入开销
索引操作流程图解
下面这张图展示了索引在数据库中的工作流程,包括高层节点如何通过键范围路由到叶子页,以及叶子页之间如何通过指针形成链表:
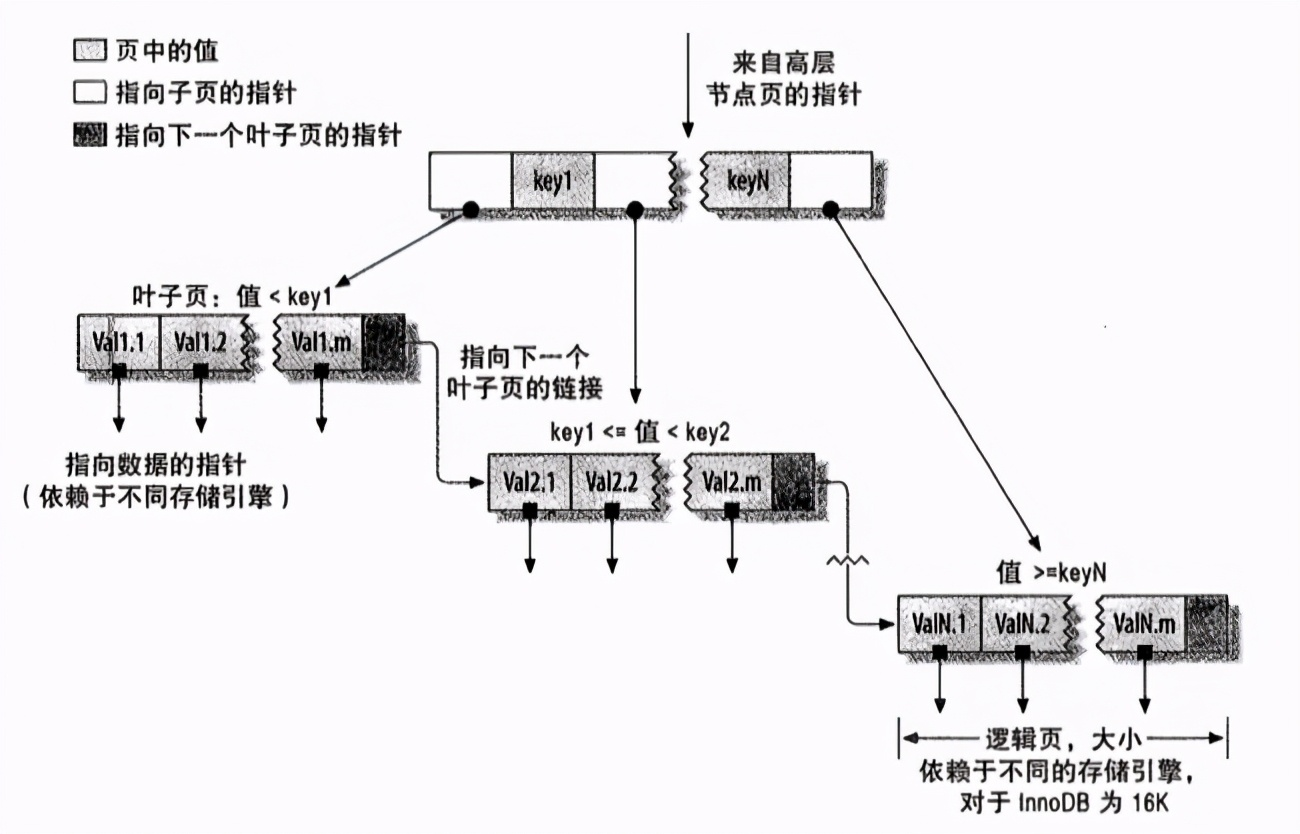
SQL性能分析工具
找到了问题SQL,就像医生找到了病灶;而性能分析工具,则是我们的"听诊器"和"CT扫描仪"。MySQL提供了四类核心工具,从不同维度诊断SQL性能问题。
工具一:查看SQL执行频率
通过统计增删改查的访问频次,判断数据库的核心操作类型,进而确定优化侧重点。
核心指令:
-
查看全局状态:show global status like 'Com_%'
-
查看当前会话状态:show session status like 'Com_%'
案例:分析查询操作占比
-- 查看查询次数
show global status like 'Com_select';
-- +---------------+-------+
-- | Variable_name | Value |
-- +---------------+-------+
-- | Com_select | 1653 |
-- +---------------+-------+
-- 执行一次查询后再次查看
select * from TB_user where id = 1;
show global status like 'Com_select';
-- +---------------+-------+
-- | Variable_name | Value |
-- +---------------+-------+
-- | Com_select | 1654 |
-- +---------------+-------+
解读:如果Com_select占比超过70%,说明系统以查询为主,应重点优化索引;如果Com_insert占比高,则需考虑写入性能优化。
工具二:慢查询日志
慢查询日志用于记录执行时间超过预设阈值的SQL语句,是定位低效查询的"黑匣子"。
开启步骤:
-
修改MySQL配置文件/etc/my.cnf:
slow_query_log = 1 # 开启慢查询日志
slow_query_log_file = /var/lib/mysql/slow.log # 日志文件路径
long_query_time = 2 # 慢查询阈值(秒),超过此值才记录
log_queries_not_using_indexes = 1 # 记录未使用索引的查询
-
重启MySQL服务:systemctl restart mysqld
-
验证配置:show variables like 'slow_query_log';
日志内容分析:
执行一条慢查询后,查看日志文件:
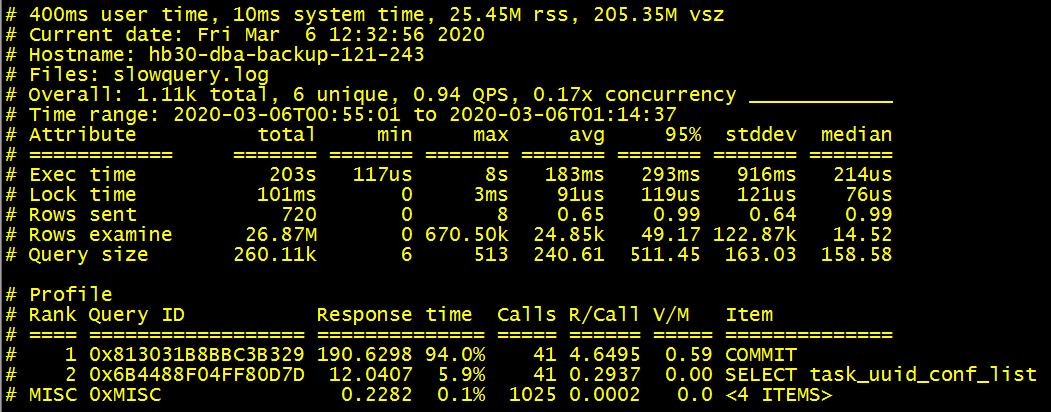
日志中会包含以下关键信息:
-
Query_time:查询执行时间(秒)
-
Lock_time:锁定时间(秒)
-
Rows_sent:返回行数
-
Rows_examined:扫描行数
-
SQL语句:完整的SQL文本
优化建议:当Rows_examined远大于Rows_sent时(例如扫描1000行只返回1行),说明查询效率低,可能缺少合适的索引。
工具三:Profile详情
慢查询日志只能捕捉超过阈值的SQL,而Profile可以精准查看每条SQL的执行耗时及各阶段耗时分布,适合分析"临界慢查询"(如耗时1.8秒,接近2秒阈值)。
使用步骤:
-
查看是否支持:select @@profiling(结果为1表示开启,0表示关闭)
-
开启Profile:set profiling = 1;(session级别生效)
-
执行SQL操作:例如执行几条不同的查询
-
查看所有SQL的耗时概况:show profiles;
-
查看某条SQL的阶段耗时:show profile for query QueryID;
案例:分析不同查询的耗时差异
-- 执行一系列操作
select * from TB_user;
select * from TB_user where id = 1;
select count(*) from TB_SKU;
-- 查看概况
show profiles;
-- +----------+------------+----------------------------------+
-- | Query_ID | Duration | Query |
-- +----------+------------+----------------------------------+
-- | 1 | 0.00052175 | select * from TB_user |
-- | 2 | 0.00012350 | select * from TB_user where id=1 |
-- | 3 | 13.2578900 | select count(*) from TB_SKU |
-- +----------+------------+----------------------------------+
-- 查看最耗时的查询(Query_ID=3)的详细阶段
show profile for query 3;
-- +----------------------+----------+
-- | Status | Duration |
-- +----------------------+----------+
-- | starting | 0.000053 |
-- | checking permissions | 0.000008 |
-- | Opening tables | 0.000017 |
-- | init | 0.000024 |
-- | System lock | 0.000008 |
-- | optimizing | 0.000005 |
-- | executing | 0.000003 |
-- | Sending data | 13.257721| # 主要耗时在数据传输阶段
-- | end | 0.000015 |
-- | query end | 0.000007 |
-- | closing tables | 0.000008 |
-- | freeing items | 0.000011 |
-- +----------------------+----------+
工具四:Explain查看执行计划
Explain是SQL优化中最重要的工具,它能展示MySQL执行SQL的详细计划,包括索引使用情况、表连接顺序、数据读取方式等。
语法:在select语句前添加explain或desc
案例:分析一条多表查询的执行计划
explain
select t2.*
from t2
where id = (
select id from t1
where id = (
select t3.id from t3
where t3.other_column = ''
)
);
执行结果如下:
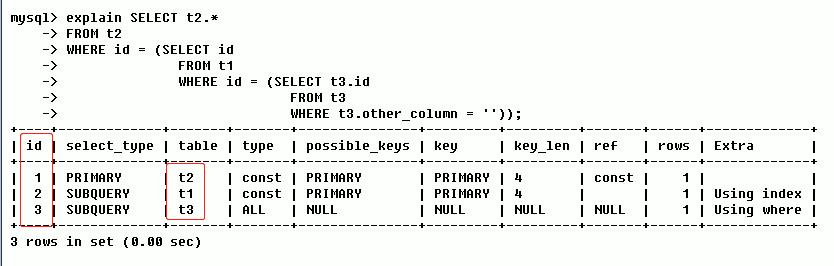
核心字段解读
|
字段 |
含义 |
重要性 |
|---|---|---|
|
type |
访问类型,从优到劣:null > system > const > eq_ref > range > index > all |
⭐⭐⭐⭐⭐ |
|
key |
实际使用的索引,为null表示未使用索引 |
⭐⭐⭐⭐⭐ |
|
rows |
预估扫描行数,值越小越好 |
⭐⭐⭐⭐ |
|
Extra |
额外信息(如Using index、Using filesort、Using temporary) |
⭐⭐⭐⭐ |
type字段详解:
-
const:通过主键或唯一索引查询,最多返回一行(如where id=1)
-
ref:通过非唯一索引查询(如where name='张三')
-
range:范围查询(如where age between 20 and 30)
-
all:全表扫描(未使用索引,需优化)
Extra字段常见值:
-
Using index:使用了覆盖索引(仅需从索引获取数据,无需回表)
-
Using filesort:需要额外排序(通常因order by字段无索引)
-
Using temporary:使用临时表(性能差,通常因group by字段无索引)
实战优化案例
案例1:从全表扫描到索引优化
问题SQL:select * from TB_user where name = '张三';
分析:执行explain后发现type=all(全表扫描),key=null(未使用索引)。
优化步骤:
-
创建name字段索引:create index idx_user_name on TB_user(name);
-
再次执行explain,发现type=ref,key=idx_user_name,rows从10000+降为10左右。
案例2:联合索引顺序优化
问题SQL:select * from TB_user where age=25 and profession='程序员';(已创建联合索引(profession, age, status))
分析:执行explain发现key=idx_user_profession_age_status,但type=range,效率不高。
原因:违反最左前缀原则,联合索引以profession开头,查询时却先使用age字段。
优化方案:调整查询条件顺序为where profession='程序员' and age=25(与索引字段顺序一致),此时type=ref,性能提升。
总结:SQL优化的核心原则
-
索引不是越多越好:每个索引都会增加写入开销(insert/update/delete变慢),建议单表索引不超过5个。
-
优先优化高频SQL:通过慢查询日志找出Top 10慢查询,优先优化这些"大头"。
-
避免索引失效:如使用like '%xxx'(模糊查询前缀带%)、函数操作索引字段(如where substr(name,1,3)='张三')。
-
定期维护索引:使用analyze table 表名更新索引统计信息,使用show index检查冗余索引。
记住:最好的索引是基于业务需求设计的索引。没有放之四海而皆准的优化方案,只有深入理解业务场景,才能写出高效的SQL。
希望这篇文章能帮你打开MySQL性能优化的大门。如果你有更多优化案例或疑问,欢迎在评论区交流讨论!让我们一起,写出"飞一般"的SQL。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









