



起初我是在B站上跟着尚硅谷老师进行学习,我的习惯是一开始先进行需要使用的方法进行倒入
import urllib.request
from lxml import etree
这分别倒入了爬虫最基础的两个库,一个是request用于进行数据的访问与获取,lxml就是配合浏览器上的xpath使用,进行数据提取。
开始先写一个main函数
if __name__ == '__main__':
start_page = int(input('请输入起始页码:'))
end_page = int(input('请输入结束页码:'))
for page in range(start_page, end_page + 1):
request = create_request(page)
content = get_content(request)
down_load(content)
这个函数是让人选择所爬取的数据页数,我这次的任务是爬取站长素材的图片,我选择的是站长素材里面大海的图片
让后让我们开启F12进入开发者工具进行数据查询,获取我们所需的信息,我先进入的是网络这个部分,找到了这个网页的主目标,就是这个get
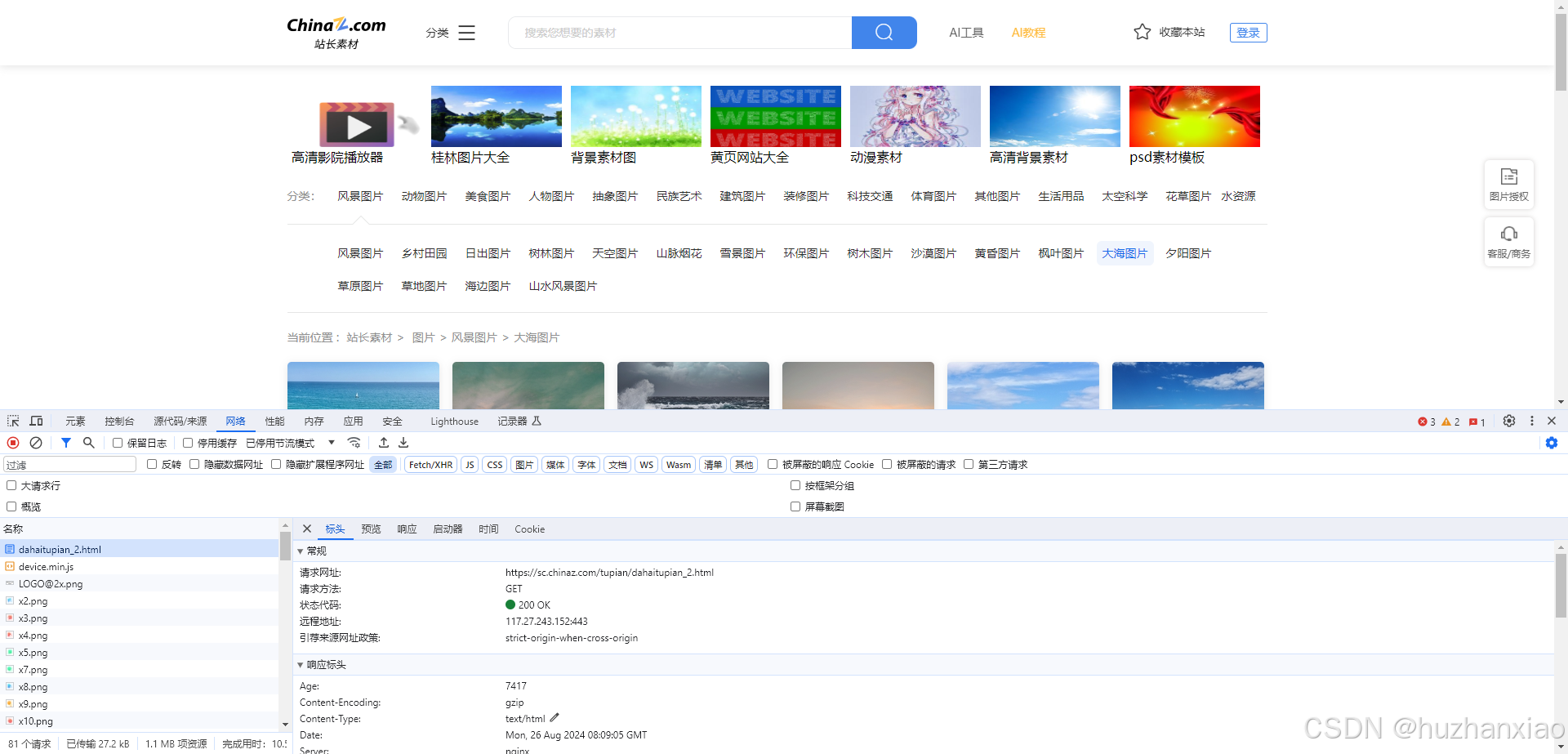
然后我们进入代码敲下create_request()函数,这个函数主要是用于让我们以访客的身份进行爬取数据,这个cookie和accept可加可不加,我为了保险就加了,这个request主要是为了封装内容,这其中涉及到了一个反爬手段就是一些网站的开头是https的他们就需要我们加入user-agent给他进行识别,就像进小区要刷卡这样。
def create_request(page):
if page == 1:
url = 'https://sc.chinaz.com/tupian/dahaitupian.html'
else:
url = 'https://sc.chinaz.com/tupian/dahaitupian_' + str(page) + '.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36',
# 'Cookie': '3551364119;cz_statistics_visitor=d006f113-f57e-3a1a-17da-71e29f11c8f4;Hm_lvt_398913ed58c9e7dfe9695953fb7b6799=1724651622;HMACCOUNT=25D6C8CAC39BB6DD;Hm_lpvt_398913ed58c9e7dfe9695953fb7b6799=1724652222',
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7'
}
request = urllib.request.Request(url=url, headers=headers)
return request
接下来我们就要进行访问了,创建get_content(request)函数,这个返回值是环环相扣的所以必须写
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
接下来就是重头戏了,我在这发现了许多的问题,我们需要创建一个下载函数down_load(content)
他需要get_content()函数的返回值,我们先进入到浏览器去到元素环节,
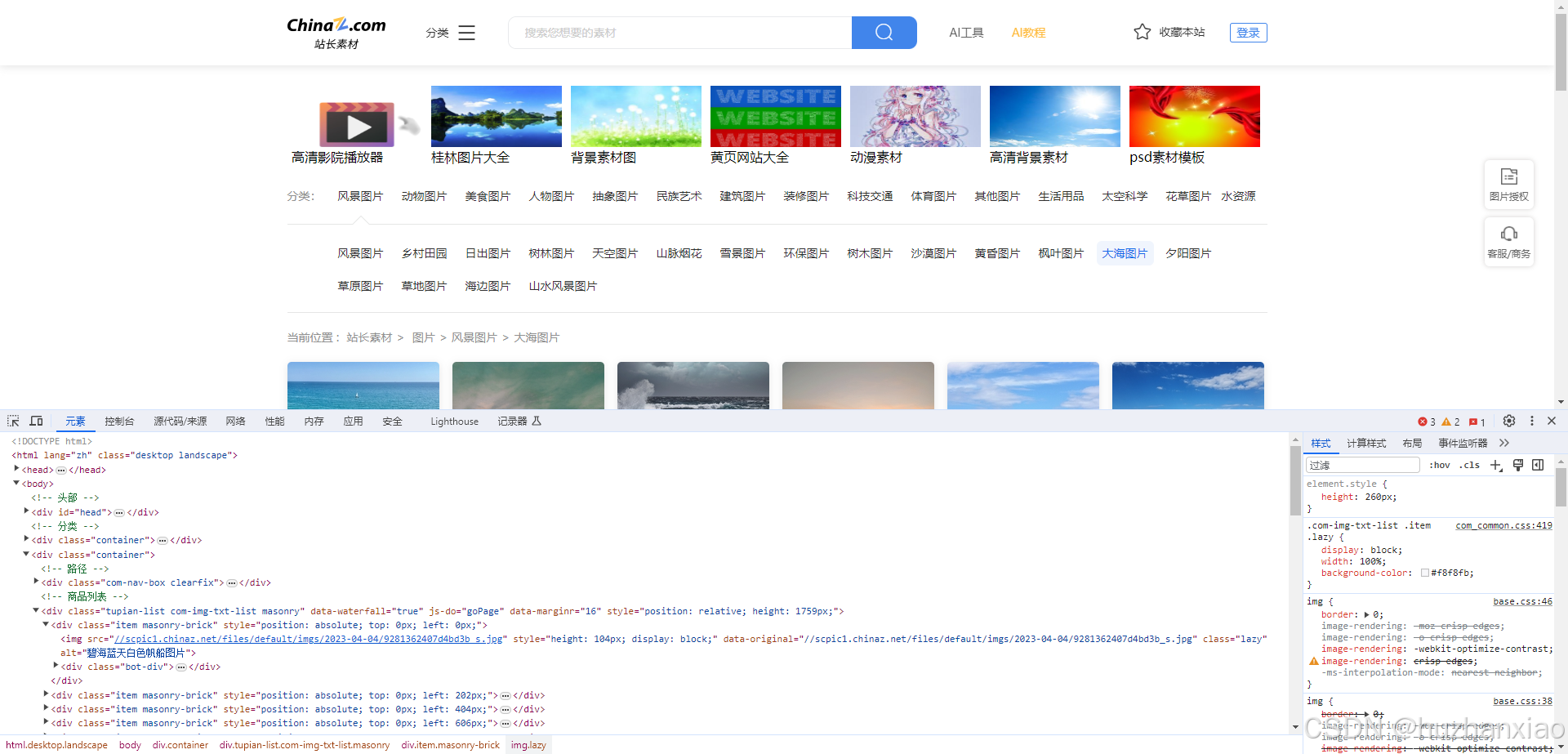
我们想要的数据是图片与它的标题,我们可以通过图片找到它的src和alt,这两个是我们需要的,这时打开xpath,明确我们的目标
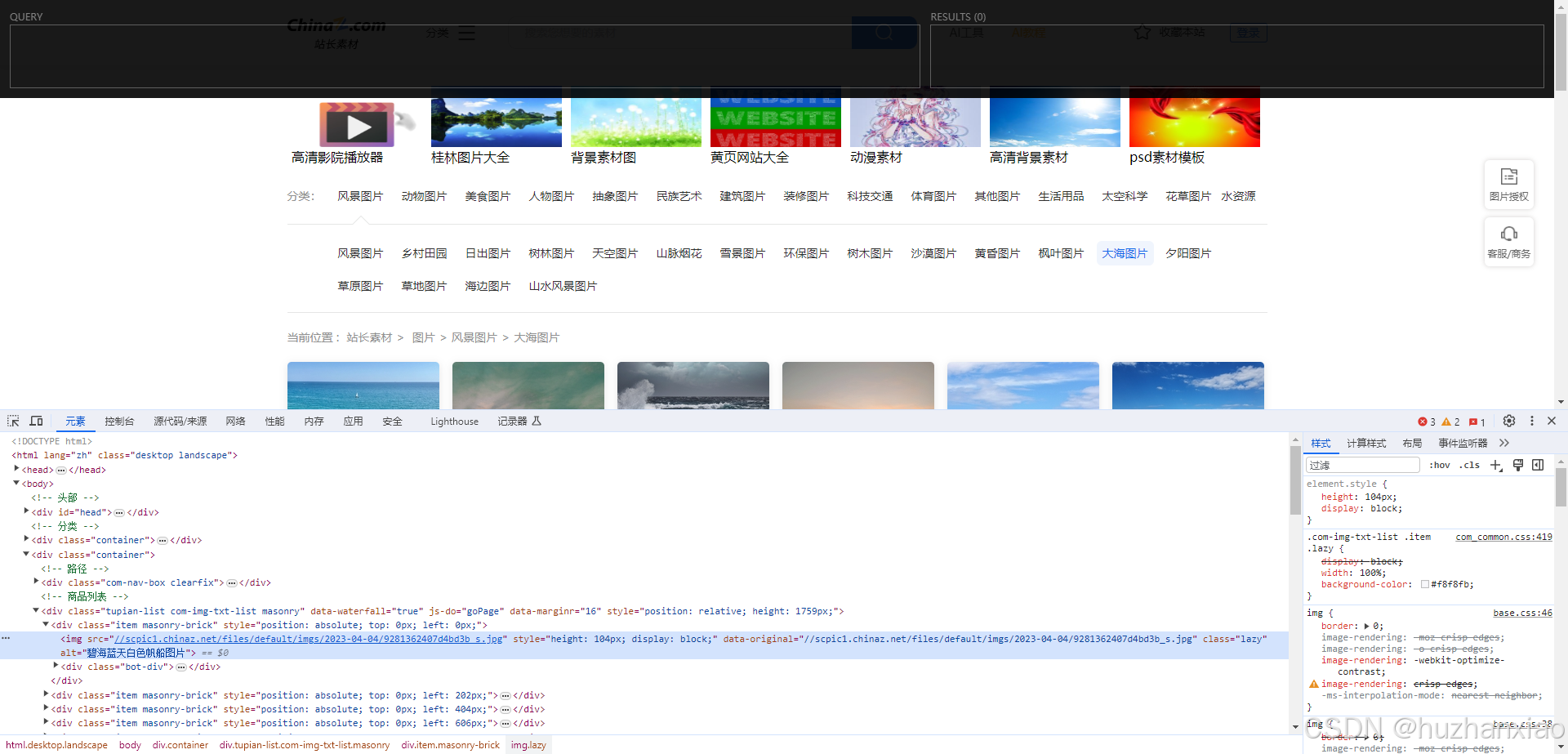
这里面一开始我是跟尚硅谷敲的代码是一样的,但是我发现没有id,我就选择了img上面的class,xpath里面显示的也是对的内容
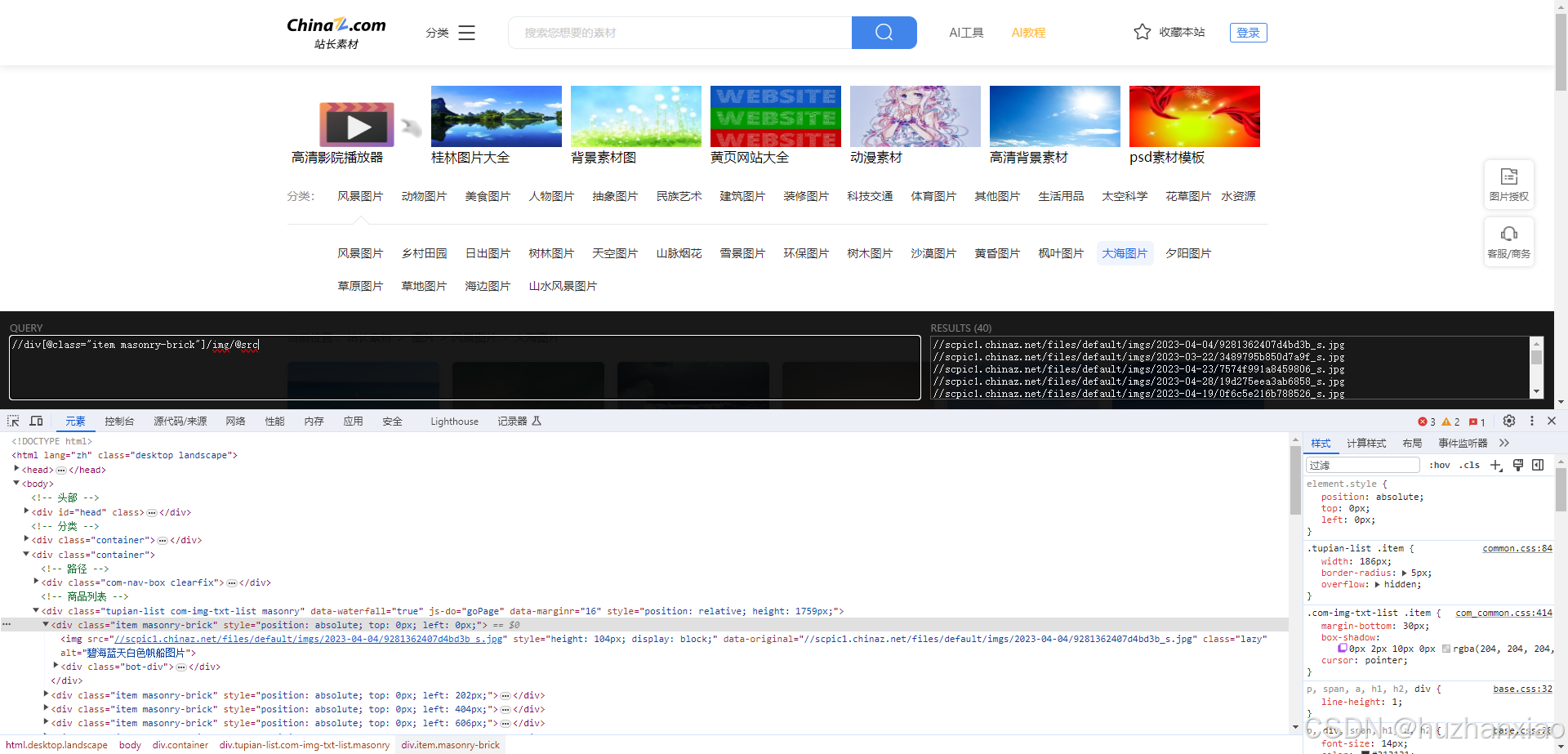
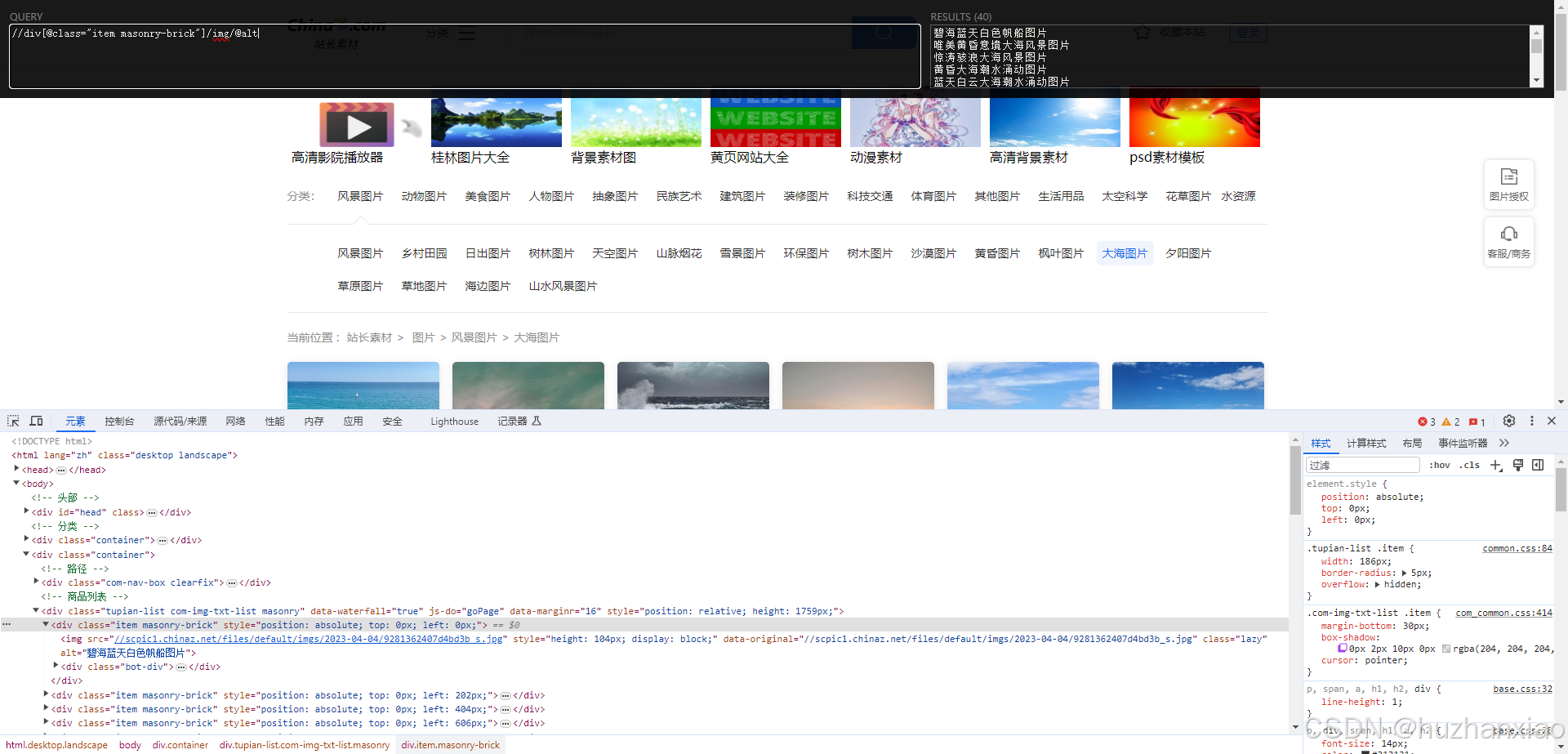
让后我就敲入pycharm了(但是因为是图片不明显,我换成了文字@alt),这段代码会输出我所拿到的内容,内容应该跟xpath一样
def down_load(content):
tree = etree.HTML(content)
name_list = tree.xpath('//div[@class="item masonry-brick"]/img/@alt')
for i in range(len(name_list)):
name = name_list[i]
print(name)
问题出现了,我发现我的python拿不到内容
这应该是python与xpath内容冲突导致,xpath可以提取的python不一定能拿到,之后我就换了一个
name_list = tree.xpath('//div[@data-marginr=16]//@alt')
这个就没问题了,后面我发现了一个非常有趣的事,下载图片时,现如今的懒加载和之前src2的时候不一样,它是直接在src里面进行懒加载,你在里面不能获得完整的网址,所以我们要更改,我这里选用的依然是data-original,你在我之前的图片发现src可能是完整的但是刷新后它就变了,我们往下滑,那些未加载出的图片
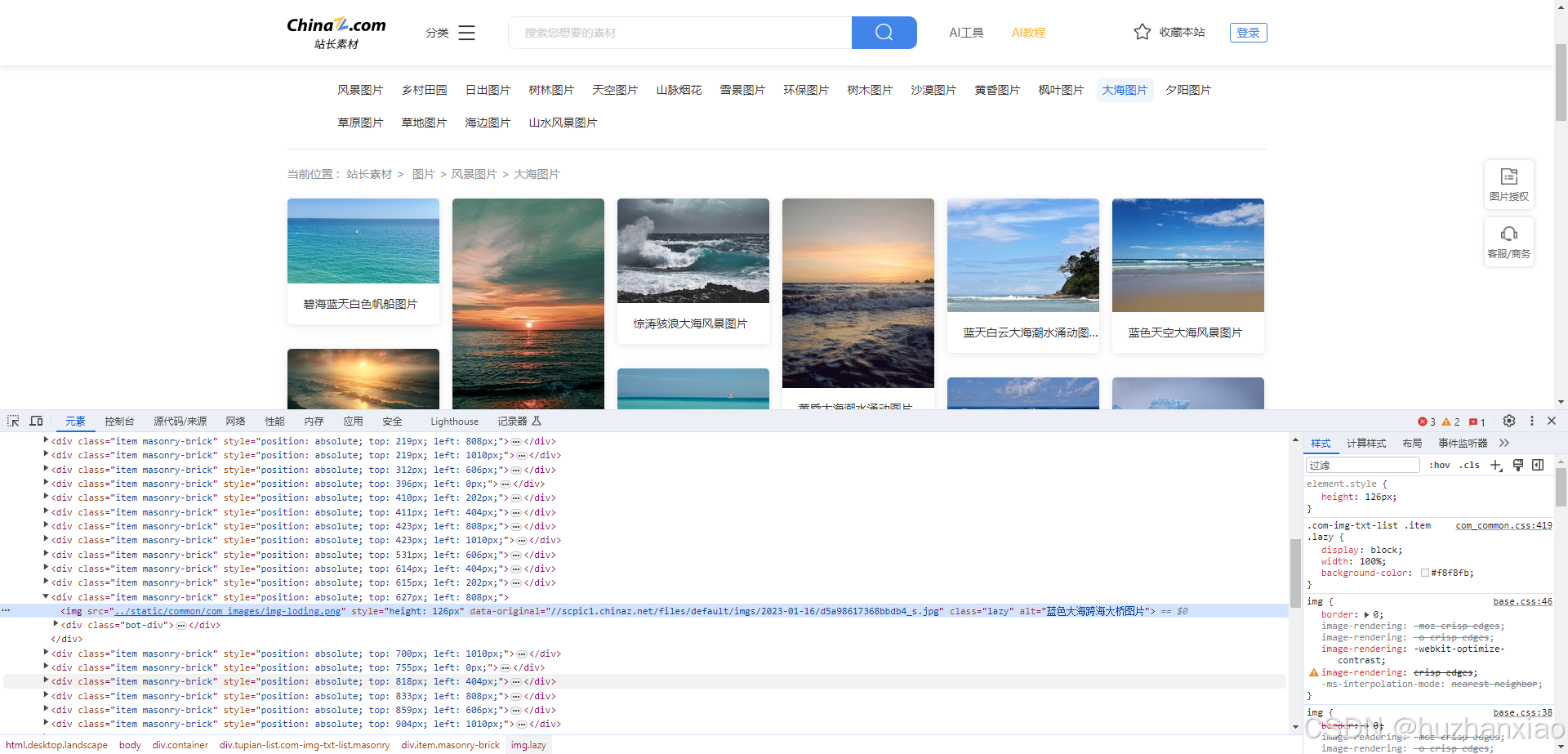
很明显它不是完整的,但是我们爬虫现在没办法去滑动刷新,我们只能去其他地方进行提取。
总结
我发现学习路上不是所有东西都是和教的一样,有些事有些东西可能只有你自己能碰到,所以需要随机应变,可能我比较笨,不过无所谓了,我一个小菜鸟,只是给学习路上的人一点小小的提示,万一一样呢。后面附上源码和运行结果
import urllib.request
from lxml import etree
def create_request(page):
if page == 1:
url = 'https://sc.chinaz.com/tupian/dahaitupian.html'
else:
url = 'https://sc.chinaz.com/tupian/dahaitupian_' + str(page) + '.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36',
# 'Cookie': '3551364119;cz_statistics_visitor=d006f113-f57e-3a1a-17da-71e29f11c8f4;Hm_lvt_398913ed58c9e7dfe9695953fb7b6799=1724651622;HMACCOUNT=25D6C8CAC39BB6DD;Hm_lpvt_398913ed58c9e7dfe9695953fb7b6799=1724652222',
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7'
}
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(content):
tree = etree.HTML(content)
name_list = tree.xpath('//div[@data-marginr=16]//@alt')
src_list = tree.xpath('//img[@class="lazy"]/@data-original')
for i in range(len(name_list)):
name = name_list[i]
print(name)
src = src_list[i]
url='https:'+ src
urllib.request.urlretrieve(url=url, filename=name+'.jpg')
if __name__ == '__main__':
start_page = int(input('请输入起始页码:'))
end_page = int(input('请输入结束页码:'))
for page in range(start_page, end_page + 1):
request = create_request(page)
content = get_content(request)
down_load(content)

















 3423
3423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









