



为什么加了索引查询还是慢
你有没有遇到过这样的情况:明明给字段加了索引,查询速度却没什么变化?甚至有时候,加了索引反而更慢了?别慌,这不是MySQL在跟你开玩笑,而是你可能没真正搞懂索引的工作原理。今天,我们就从索引的本质讲起,一步步揭开MySQL索引的神秘面纱,让你彻底明白为什么InnoDB偏偏选择了B+树,以及如何在实际业务中设计出高效的索引。
索引到底是什么
数据库的“新华字典”
如果把数据库表比作一本厚厚的《新华字典》,那么索引就相当于字典前面的部首目录。想象一下,如果你想查“数据库”这个词,没有目录的话,你可能需要从第一页翻到最后一页,这就是全表扫描。而有了目录,你可以先通过“数”字的部首找到对应的页码,直接翻到那一页,这就是索引的作用。
索引的本质,就是数据库为了提升查询效率而构建的有序数据结构。它就像图书馆的图书分类系统,让你能快速定位到想要的数据,而不用一本本(一行行)去查找。
没有索引有多可怕
我们来做个实验。假设有一个电商用户表user,里面存了10万条用户数据,结构如下:
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 主键 |
| user_name | varchar(50) | 用户名 |
| age | int | 年龄 |
| address | varchar(200) | 地址 |
| create_time | datetime | 注册时间 |
现在,我们要查询所有年龄为45岁的用户:
SELECT * FROM user WHERE age = 45;
没有索引的时候,MySQL会怎么做呢?它会从表的第一行开始,逐行检查age字段是不是45,直到扫描完所有10万行数据。即使表中只有1条符合条件的记录,它也得把整个表翻一遍。在普通服务器上,这个过程大约需要0.8秒。
有了索引效率提升多少
现在,我们给age字段创建一个普通索引:
CREATE INDEX idx_user_age ON user(age);
再执行同样的查询,猜猜需要多久?0.002秒!没错,效率提升了足足400倍!这就是索引的魔力。
为什么会这么快?因为索引会把age字段的值按顺序存储,就像给年龄建了一个排序表。MySQL可以通过这个排序表直接定位到age=45的位置,不需要再扫描全表。
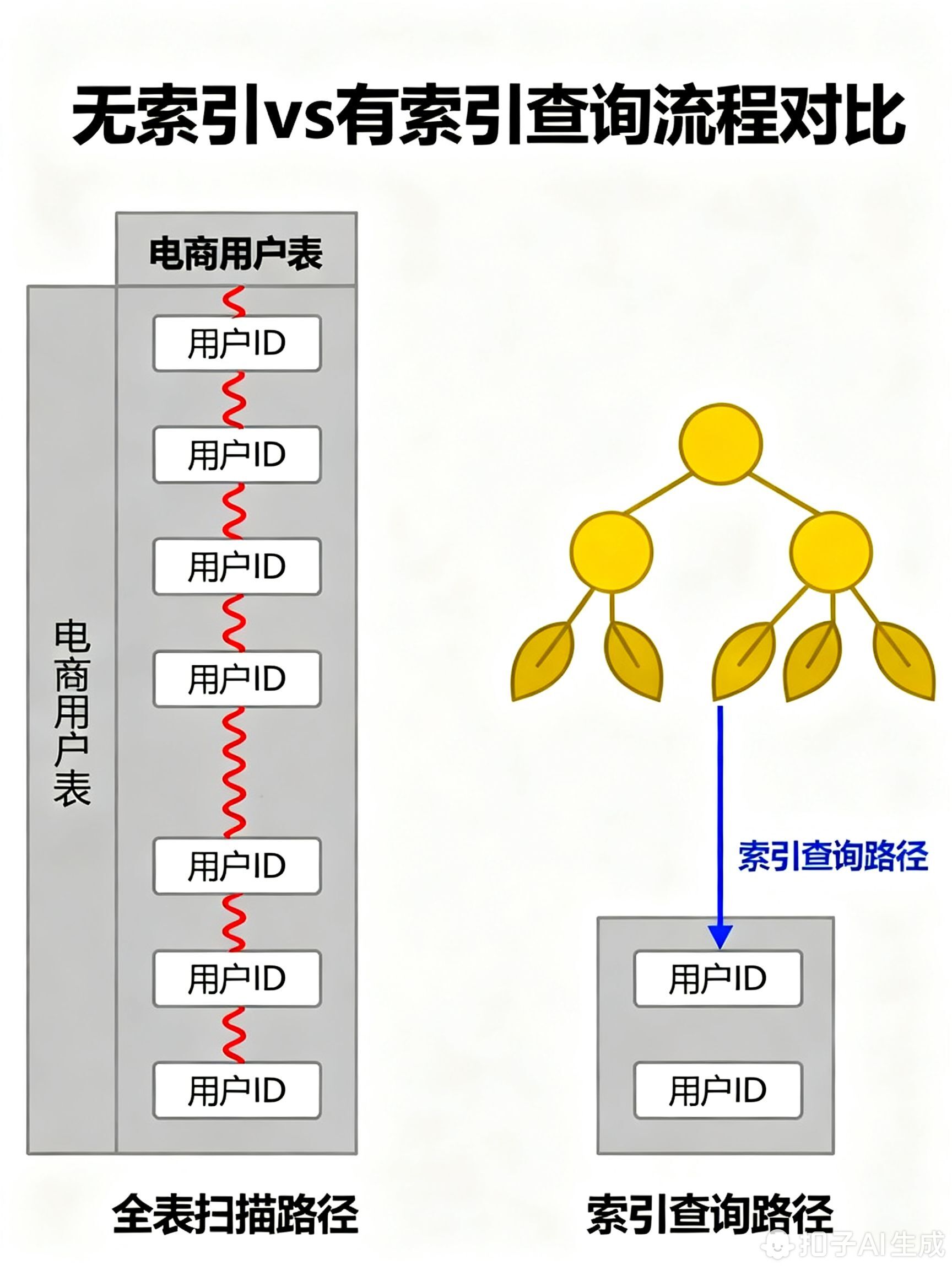
索引有哪些类型
MySQL支持多种索引类型,不同的索引适用于不同的场景。下面我们就来一一认识它们。
B+树索引:最常用的“万能钥匙”
B+树索引是MySQL中最常用的索引类型,InnoDB和MyISAM存储引擎都支持。它就像一棵多层目录树,最上面是根节点,中间是分支节点,最下面是叶子节点,所有数据都存在叶子节点上,并且叶子节点之间形成了一个双向链表。
举个例子:电商订单表order的主键是order_id(自增int)。InnoDB会自动为order_id创建一个聚簇索引(B+树结构):
-
非叶子节点:存储order_id的范围值,比如1-100、101-200,以及指向下一级节点的指针。
-
叶子节点:存储完整的订单数据行,包括order_id、user_id、amount、pay_time等所有字段。
当我们执行SELECT * FROM order WHERE order_id = 156;时,MySQL会通过B+树的二分查找,快速定位到order_id=156的叶子节点,直接返回数据。
哈希索引:等值查询的“闪电侠”
哈希索引就像一本电话簿,通过哈希函数把键值(key)转换成一个哈希值,然后直接通过哈希值找到对应的数据行指针。它的等值查询速度非常快,但有两个致命缺点:
-
不支持范围查询:比如WHERE key > 'user_100'这样的查询,哈希索引无能为力,只能退化为全表扫描。
-
存在哈希冲突:不同的键值可能会计算出相同的哈希值,这时候就需要通过链表来解决冲突,会影响查询效率。
哈希索引只有Memory存储引擎原生支持,适合存储临时缓存数据。比如我们可以创建一个临时缓存表temp_cache,给key字段建哈希索引:
CREATE INDEX idx_temp_key ON temp_cache USING HASH(key);
空间索引:地理位置查询的“导航仪”
空间索引(SPATIAL INDEX)就像地图上的坐标系统,专门用于地理位置数据的查询。它基于RTREE结构,可以快速检索出某个地理范围内的记录。
适用场景:外卖App查找附近的商家、打车软件定位附近的司机等。
比如外卖商家表merchant,存储了商家的经纬度(location字段为POINT类型)。我们可以创建空间索引:
CREATE SPATIAL INDEX idx_merchant_location ON merchant(location);
然后查询距离用户1公里内的商家:
SELECT * FROM merchant
WHERE ST_Distance_Sphere(location, POINT(116.40, 39.90)) < 1000;
这样就能快速找到附近的商家,而不用计算所有商家到用户的距离。
全文索引:文本搜索的“搜索引擎”
全文索引(FULLTEXT INDEX)就像百度搜索引擎,专门用于文本内容的快速检索。它通过倒排索引(关键词→文档ID的映射)来实现,比LIKE '%关键词%'这种模糊查询高效得多。
适用场景:商品详情搜索、文章内容检索等。
比如商品详情表product_desc,存储了商品描述(content字段)。我们可以创建全文索引:
CREATE FULLTEXT INDEX idx_product_content ON product_desc(content);
然后查询包含“无线充电”和“快充”的商品:
SELECT * FROM product_desc
WHERE MATCH(content) AGAINST('+无线充电 +快充' IN BOOLEAN MODE);
这里的+表示必须包含该关键词,IN BOOLEAN MODE表示使用布尔模式进行搜索。
各种索引类型大比拼
为了让你更直观地了解不同索引的特点,我做了一个对比表:
| 索引类型 | 支持引擎 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| B+树索引 | InnoDB, MyISAM | 全场景查询 | 支持范围查询、排序 | 插入删除有一定开销 |
| 哈希索引 | Memory | 等值查询 | 等值查询速度极快 | 不支持范围查询、有冲突 |
| 空间索引 | MyISAM, InnoDB | 地理位置范围查询 | 快速定位地理范围 | 适用场景有限 |
| 全文索引 | InnoDB, MyISAM | 文本内容搜索 | 高效文本匹配 | 不支持部分关键词匹配 |
为什么MySQL偏爱B+树
叉树:美丽的错误
一开始,你可能会想,为什么不用二叉树作为索引结构呢?二叉树的查找效率不是也挺高的吗?
确实,在理想情况下,二叉树的查找效率是O(log n)。比如下面这个二叉树:
36
/ \
22 50
/ \
19 25
/
17
查找17的过程是:36→22→19→17,需要4次I/O。看起来还不错。
但是,如果我们按顺序插入数据,比如36→34→33→23→22,二叉树就会退化成一条链表:
36
↓
34
↓
33
↓
23
↓
22
↓
17
这时候查找17,就需要遍历所有5个节点,跟全表扫描没什么区别!这就是二叉树的致命缺陷:容易失衡。
红黑树:平衡了但还不够
为了解决二叉树失衡的问题,人们发明了红黑树。红黑树通过一系列自平衡操作,保证树的高度始终是O(log n)。比如插入36→34→33→23→22后,红黑树会自动调整成这样:
34 (黑)
/ \
23 (红) 36 (红)
/ \
22 (黑) 33 (黑)
这时候查找22,只需要3次I/O,比失衡的二叉树好多了。
但是,红黑树在数据量很大的时候,问题就暴露出来了。比如存储100万条数据,红黑树的高度大约是20层,这意味着每次查询需要20次磁盘I/O。而磁盘I/O是非常慢的,20次I/O足以让查询变得卡顿。
B树:多路平衡但不完美
B树(B-tree)是一种多路平衡查找树,它允许一个节点存储多个键值。比如一个五阶B树,每个节点最多可以存储4个键值和5个指针(指针数=键值数+1)。
现在我来演示一下B-tree的结构和插入数据后是怎么变化的,我们先插入22,45,33,56这些数据。
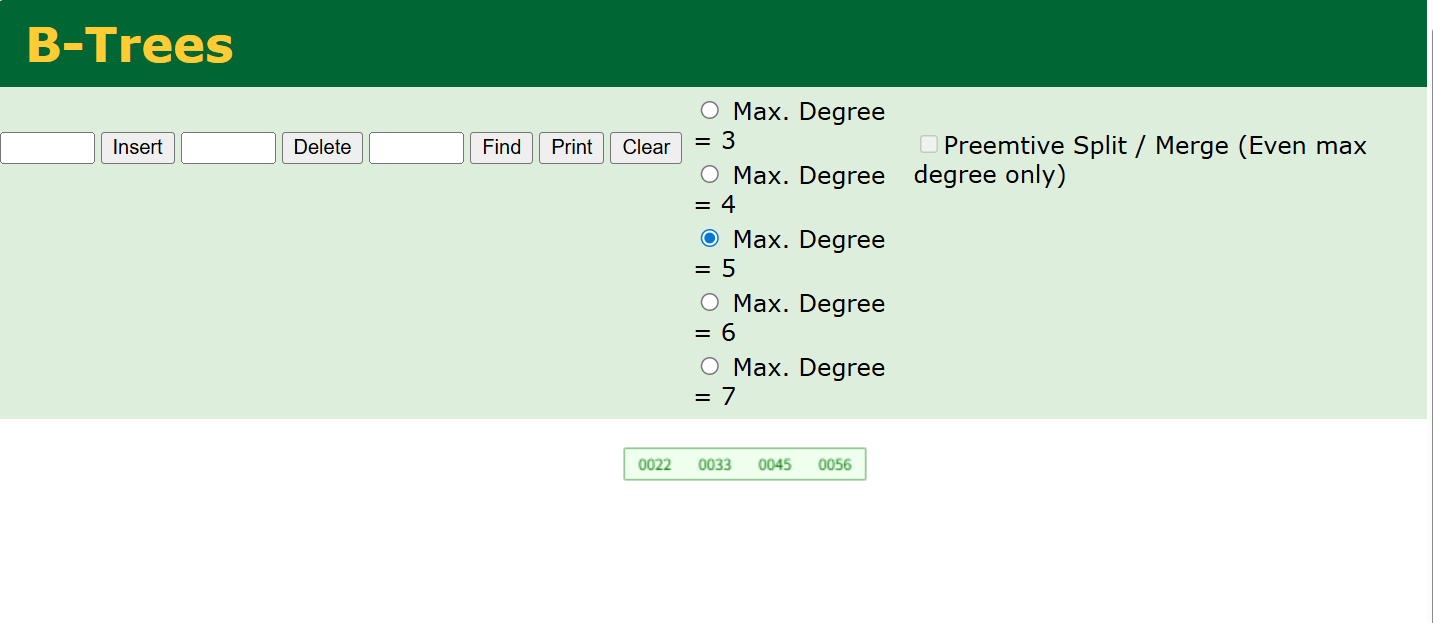
应为我们知道,这个五阶B树可以储存四个键值,那么当他储存到第五个会是怎么样的呢,我这时插入79,我们来看看
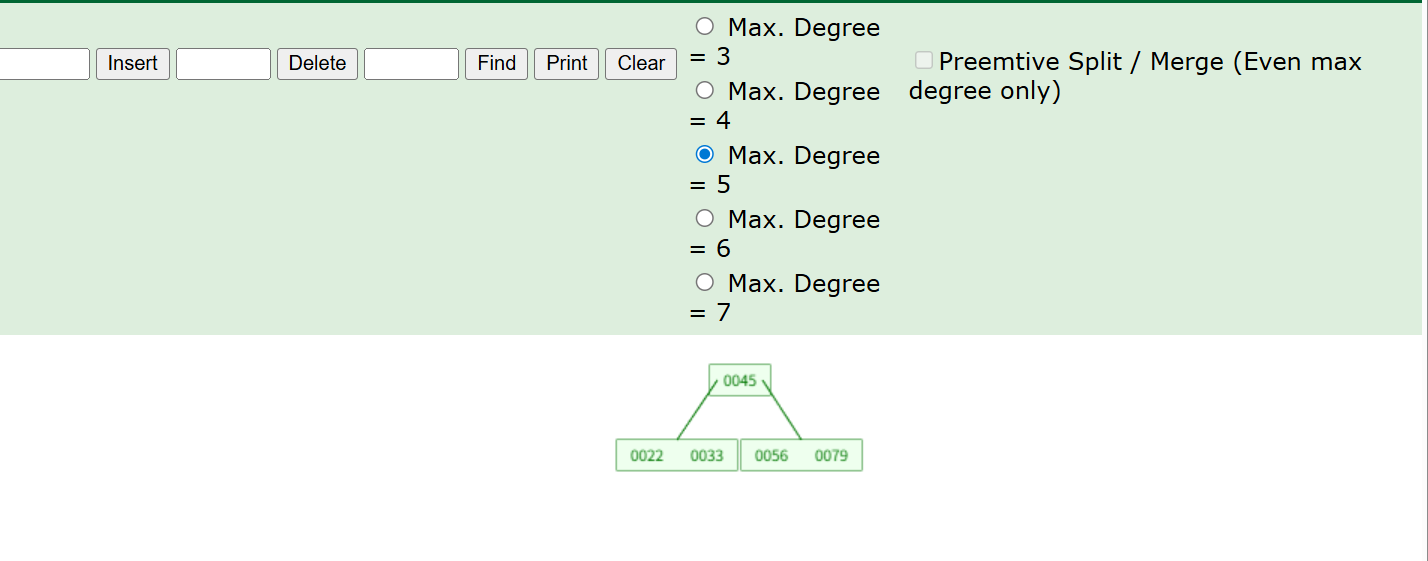
因为插入的顺序会按照大小排列,插入了79,79比所有的都大就放在最后,但是因为这只能放四个键,没地方了,这时中间数会变成父节点,其他的数据分别变成左节点右节点。
以此类推,大家可以去 B-Tree Visualization这个网站自己试试以便更加好的理解,但是,B树有个问题:非叶子节点也存储数据。这就导致每个节点能存储的键值数量减少,树的高度还是不够低。而且,B树的范围查询需要回溯父节点,效率不高。
B+树:集大成者
B+树是B树的升级版,它做了两个关键改进:
-
非叶子节点只存键值,不存数据:这样每个节点能存储更多的键值,树的高度更低。比如一个16KB的磁盘页,如果只存键值(假设每个键值8字节),大约可以存2000个键值。那么存储100万数据,只需要3层B+树(2000^3=8e10,远远超过100万)。
-
叶子节点形成双向链表:所有数据都存在叶子节点,并且叶子节点之间用指针连接起来。这样范围查询的时候,只需要找到起始叶子节点,然后沿着链表一直往后遍历,不需要回溯父节点。
我们来看一个五阶B+树的例子:
还是和刚刚一样的,B+tree也有一个网站B+ Tree Visualization,这里我们还是和刚刚一样的数据
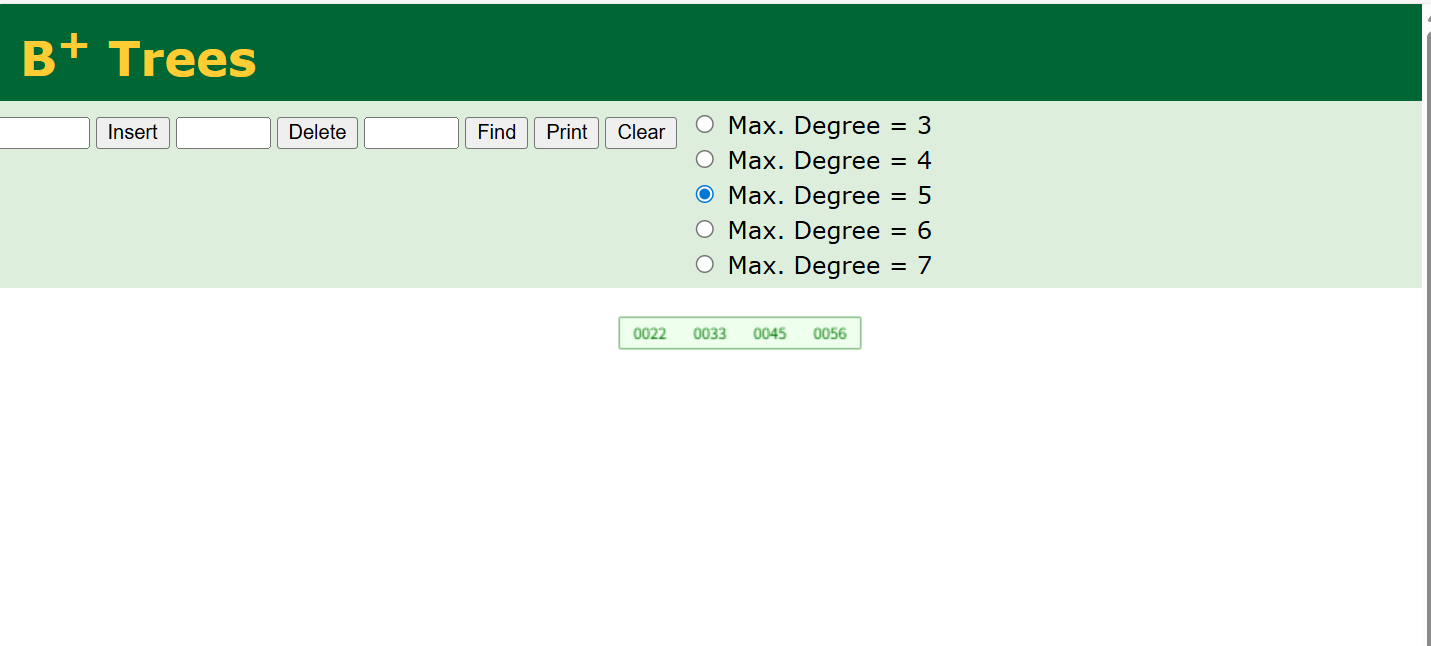
一样的插入79
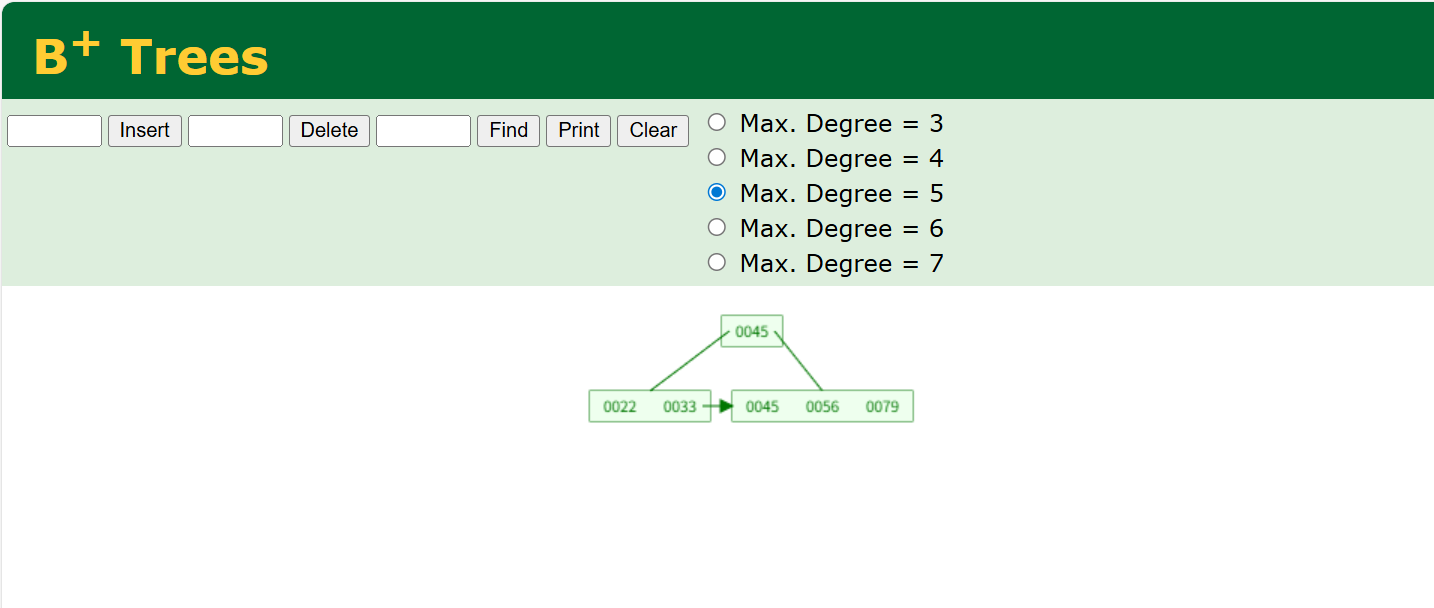
怎么样是不是很像,所以是B+tree嘛,但是又有点不同,我们发现45这个数据是不是也出现在了子节点,并且还有一个箭头,这个箭头是一个指针33是指向45的,它们是连接的。我们多加一些数据。
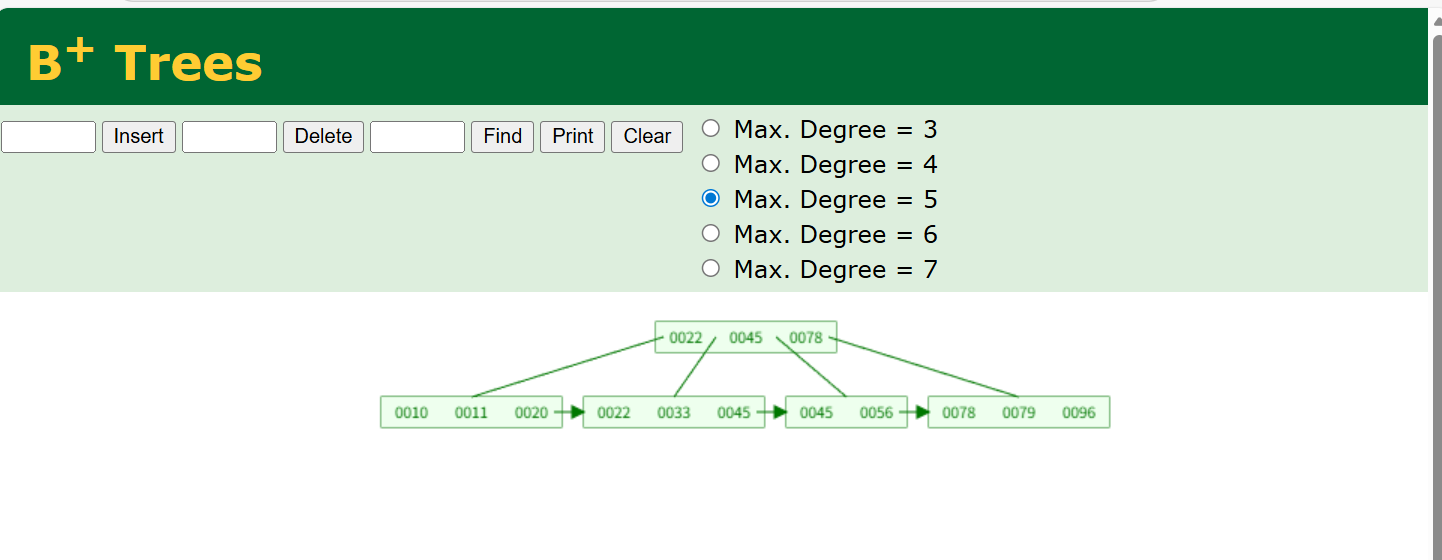
现在我加了很多的数据这时它的优势就完全体现出来了
B+树的三大优势:
-
查询效率稳定:不管查哪个数据,都需要从根节点到叶子节点,I/O次数固定(比如2次)。
-
范围查询高效:比如查询10-96的数据,只需要从第一个叶子节点开始,沿链表遍历到最后一个叶子节点,直接获取10-96的所有数据。
-
存储密度更高:非叶子节点只存键值,能存更多键,树的高度更低,I/O次数更少。
哈希索引冲突:快递柜的"碰撞"故事
哈希索引虽然说很快也很厉害但是有个弱点就是哈希索引冲突现在我举个生活中的例子我们来认识一下。
小区物业为了快速分配快递柜,制定了‘快递单号后两位取模 10’的规则 —— 这就相当于哈希索引中的哈希函数,专门用来将‘快递单号’这个‘key’,映射到‘0 - 9 号柜子’这些‘哈希槽位’上”:
-
快递Y789012(单号后两位12)→ 12 mod 10 = 2号柜(顺利放入)
-
快递B222222(单号后两位22)→ 22 mod 10 = 2号柜(发生冲突)
-
快递C333332(单号后两位32)→ 32 mod 10 = 2号柜(再次冲突)
-
系统自动将B222222和C333332依次挂在Y789012后面形成链表
-
当住户来取快递 B222222 时,系统先通过‘22 mod 10’算出对应 2 号柜,然后不会直接找到快递,而是要从 2 号柜的第一个快递 Y789012 开始,依次核对链表上的每一个快递单号(Y789012→B222222),找到匹配的才能取出;如果要取 C333332,就得遍历 3 个快递才能找到。”
-
要是某天有 10 个快递的单号后两位取模后都是 2(比如 D444442、E555552……),2 号柜的链表就会挂着 10 个快递。此时取最末尾的快递,得逐个核对 10 个单号,这时候 2 号柜的查询效率,甚至不如挨个检查所有柜子的‘全表扫描’—— 这和数据库中哈希索引冲突严重时性能大幅下降的情况完全一致。
更关键的是,这个快递柜系统没法‘批量找快递’。比如想找‘单号后两位在 15 - 25 之间的所有快递’,系统不能通过柜子编号直接筛选,因为快递是按取模分配的,15 mod10=5、22 mod10=2、25 mod10=5,这些快递分散在不同柜子里,只能逐个打开所有柜子查找 —— 这就对应了哈希索引不支持范围查询的核心短板。
InnoDB为什么选择B+树
更少的磁盘I/O
我们来算一笔账。存储100万条数据:
-
二叉树:层级约为20(log2(100万)≈20),需要20次I/O。
-
红黑树:层级也差不多20次I/O。
-
B+树:假设每个非叶子节点存100个键值,3层B+树就能存100^3=100万数据,只需要3次I/O。
磁盘I/O是数据库性能的瓶颈,I/O次数越少,查询速度就越快。B+树在这方面完胜。
更稳定的查询性能
B树的非叶子节点也存数据,所以查询不同的数据可能需要不同的I/O次数。比如查20可能在第2层找到,查90可能要到第3层。而B+树所有数据都在叶子节点,不管查什么数据,都需要固定的I/O次数,性能更稳定。
更好的范围查询支持
B+树的叶子节点是双向链表,范围查询就像我们读一本书,翻到第一页后,直接往后翻就行了。而B树要查范围,可能需要来回回溯父节点,效率低很多。
更适合磁盘存储
数据库的数据是存储在磁盘上的,而磁盘的读写是以页(通常是16KB)为单位的。B+树的节点大小刚好可以设置成一个磁盘页的大小,这样每次读取一个节点,就是一次磁盘I/O,非常高效。
企业级索引设计实战
电商用户表优化案例
假设你有一个电商用户表user,经常需要根据age和address查询用户。这时候,你可能会想建一个(age, address)的联合索引。但等等,联合索引的顺序很重要!
正确的顺序应该是(age, address),因为age的选择性(不同值的数量)可能比address高。比如,age可能有0-120岁,而address可能只有几个城市。把选择性高的字段放前面,能更快缩小查询范围。
商品搜索优化案例
对于商品详情表product_desc,如果用户经常搜索“无线充电 快充 智能手机”这样的关键词,你需要建一个全文索引。但要注意,全文索引有最小词长限制(默认InnoDB是4个字符),像“快充”这样的词可能需要调整配置。
避免这些索引坑
-
不要给所有字段都建索引:索引会占用空间,而且会拖慢插入、更新、删除的速度。
-
小心索引失效:比如使用OR、NOT IN、函数操作(WHERE SUBSTR(name,1,3)='abc')等,都可能导致索引失效。
-
定期维护索引:长时间的插入删除可能会导致索引碎片,可以通过OPTIMIZE TABLE命令来优化。
总结:索引设计的黄金法则
-
理解业务查询模式:先搞清楚你的应用最常用哪些查询,再针对性地设计索引。
-
遵循最左前缀原则:联合索引中,把最常用的字段放前面。
-
控制索引数量:不是越多越好,够用就行。
-
定期分析慢查询:通过慢查询日志和EXPLAIN命令,找出性能瓶颈。
记住,最好的索引,是那个能让你的查询语句跑得飞快,同时又不会给写入性能带来太大负担的索引。希望今天的内容能帮你真正理解MySQL索引,在实际工作中设计出更高效的数据库结构!
如果你有任何关于索引的问题,或者有自己的实战经验,欢迎在评论区留言讨论。让我们一起,把MySQL性能榨干到极致!

















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









