




Transformer 作为一种创新的神经网络结构,深受欢迎。Transformer分类模型是现代自然语言处理领域中的一个关键架构,由Vaswani等人在2017年的论文《Attention is All You Need》中提出。这个模型摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),转而采用自注意力机制,实现了并行计算,大大提高了处理速度。近两三年,编码器-解码器模型开始流行,而 Transformer 架构则是该模型的一个具体实例。在此之前,注意力(Attention)仅是这些模型使用的机制之一,大部分是基于 LSTM 和其他 RNN 变体的。Transformer 论文的核心要点在于,注意力被用作推导输入和输出之间依赖关系的唯一机制。
Transformer模型是一种基于自注意力机制的深度学习模型,其核心思想是通过自注意力机制来学习时间序列数据中的长程依赖关系。与循环神经网络 (RNN) 相比,Transformer 模型能够并行计算,训练速度更快,并且可以捕获更长的时间依赖关系。
Transformer 是一种基于注意力机制的深度学习模型,最初用于自然语言处理领域。它能够有效地提取序列数据中的全局信息,并进行并行计算,提升模型训练效率。在 Transformer 中,多头注意力机制可以捕获不同方面的特征信息,并进行加权组合,从而提高模型的表达能力。
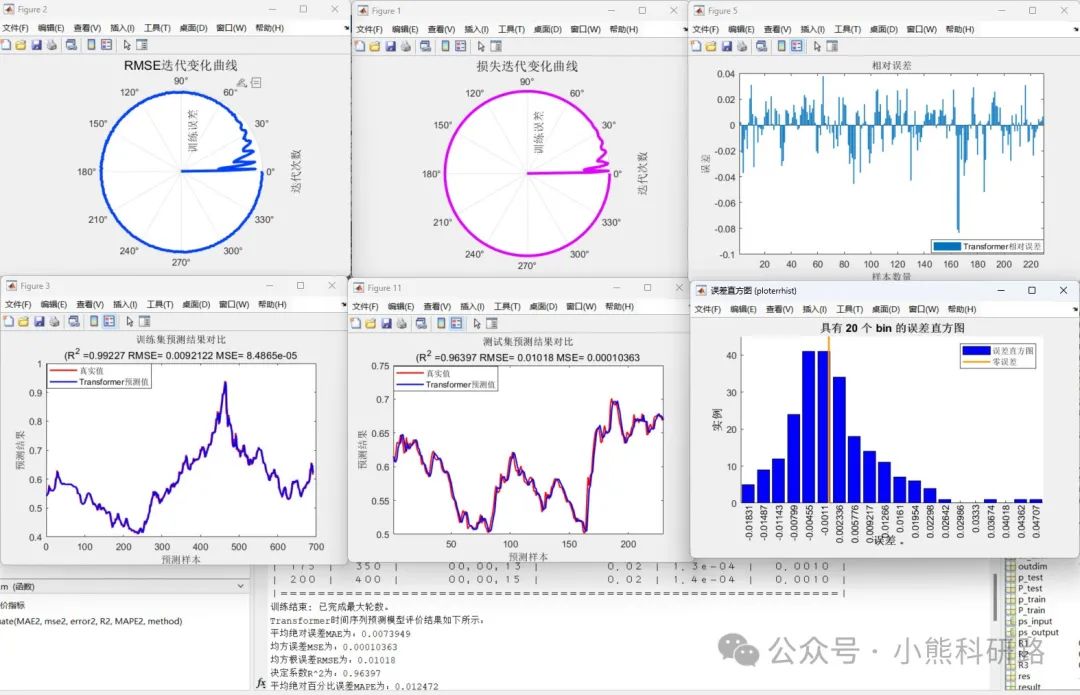
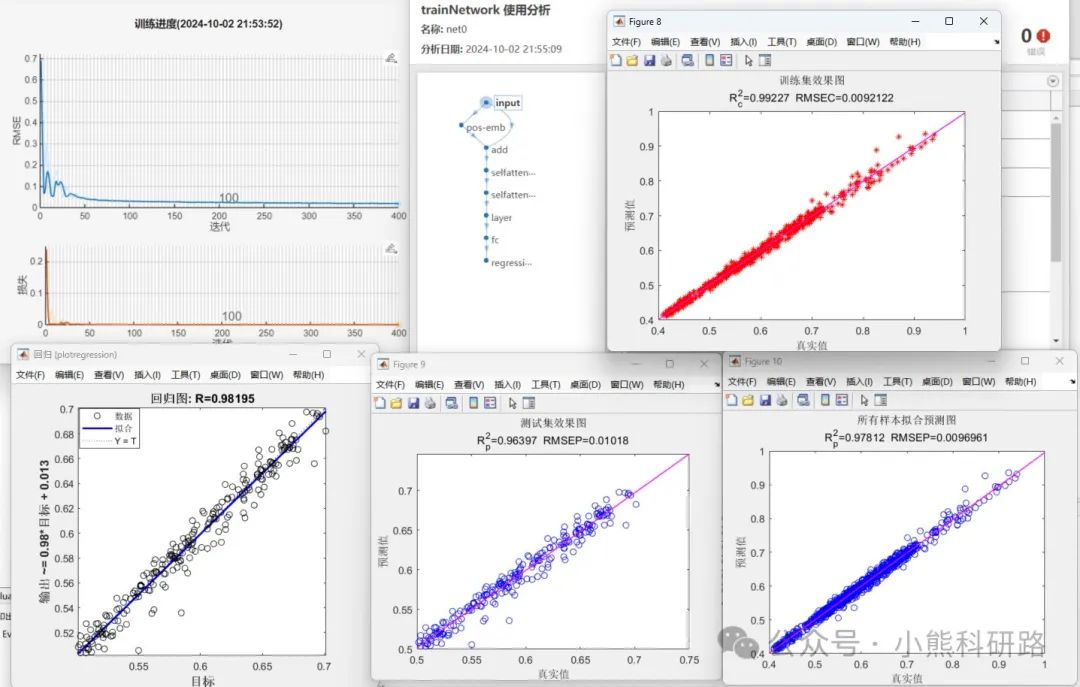
效果展示:
本文采用Matlab(2023b及其以上版本)编写代码,代码注释详细,逻辑清晰易懂,数据采用excel表格形式便于替换数据集,可main函数一键运行。

















 36
36

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









