







介绍
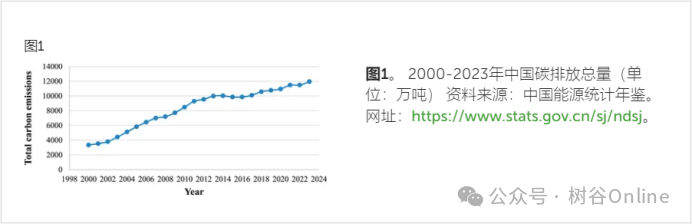
中国在减少碳排放方面发挥着至关重要的作用。中国政府表示,“中国将积极稳妥推进二氧化碳排放达峰碳中和”。从图1可以看出,中国碳排放总量自2000年以来一直快速上升,2023年碳排放总量将达到126亿吨,占全球碳排放量374亿吨的三分之一,成为全球碳排放量最大的国家。世界上最大的碳排放国。
湖南财政经济学院SCI:利用ARIMA-BP预测中国2000年至2035年各省碳排放量,附预测数据
其次,碳排放存在显着的地区差异。2023年,碳排放最高的省份是山西,最低的是青海。华东地区是碳排放量最大的地区,约占全国比例的30%。2各省碳排放量存在显着差异,是实现碳排放市场均衡协调的重要途径。
控制碳排放总量、优化碳排放结构是实现“碳达峰和碳中和目标”的必要手段。因此,基于这些问题,本文结合ARIMA时间序列分析和BP神经网络算法对全国和省份的碳排放进行测算和预测,分析我国碳排放的空间演化特征,同时分解驱动因素。LMDI(对数平均Divisia指数)因素。研究结论为我国不同地区因地制宜制定科学合理的减排政策提供决策参考。
1、ARIMA-BP神经网络模型构建
首先利用ARIMA模型对数据进行预测,得到预测误差序列。其次,建立了一个神经元和三个神经元的两层隐含层BP神经网络。将误差数据按时间顺序输入到神经网络中,输入节点设置为4,输出节点设置为1。通过滚动窗口,上一周期的误差会继续传入神经网络,如下部分输入,模型将不断修正和预测。最后利用组合模型预测碳排放强度变化(图2、图3)。具体步骤如下:
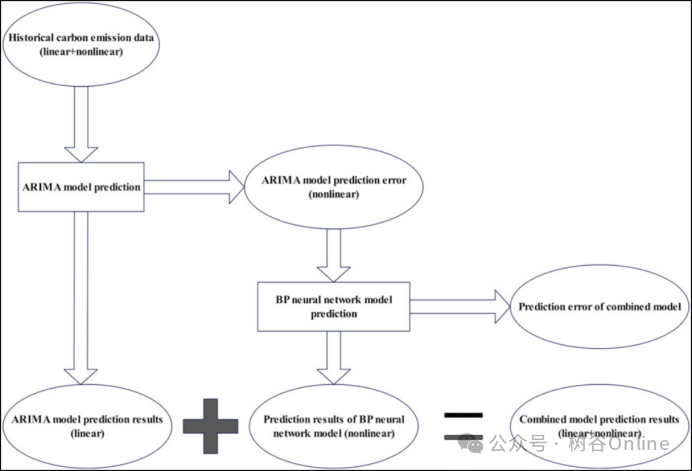
图2.组合预测模型示意图。
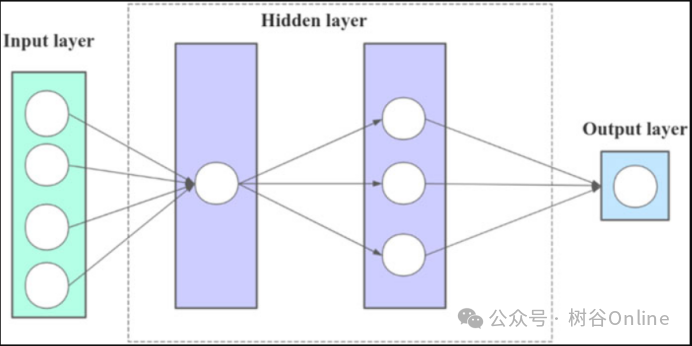
图3.BP神经网络结构图。
2、碳排放预测与分析
图4.2000-2021年各省平均碳排放量(万吨)。
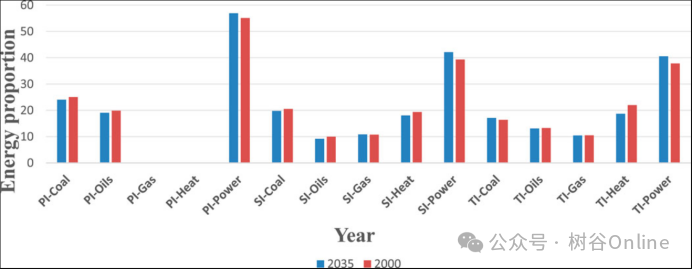
图5.2000年至2035年能源消费强度预测图。
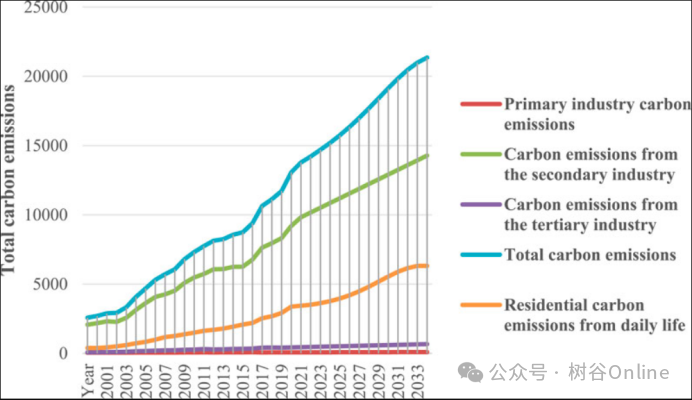
图6.2000-2021年各省平均碳排放量(万吨)。
3、中国碳排放空间分布特征
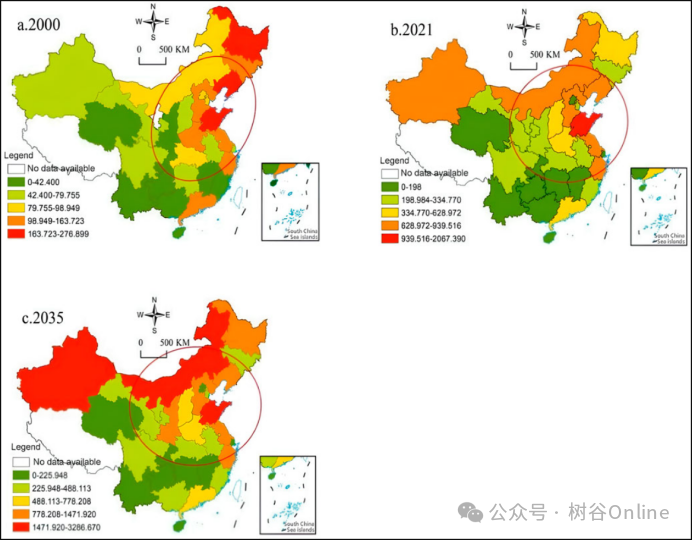
图7.2000年至2035年能源消费强度预测图。
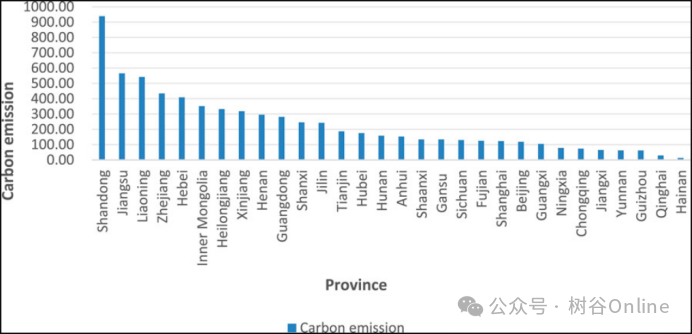
图8.2000-2035年能源比重预测图。
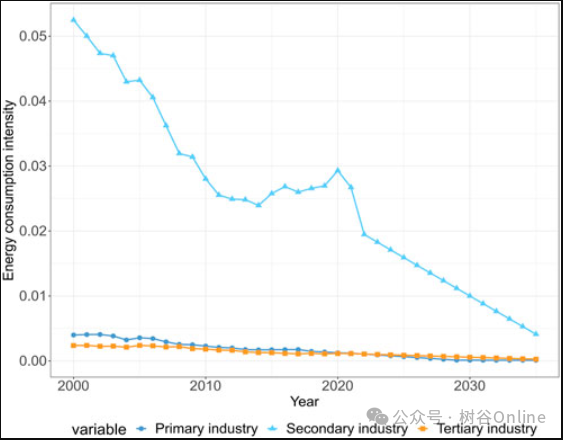
图9.2000-2035年中国碳排放总量变化趋势预测
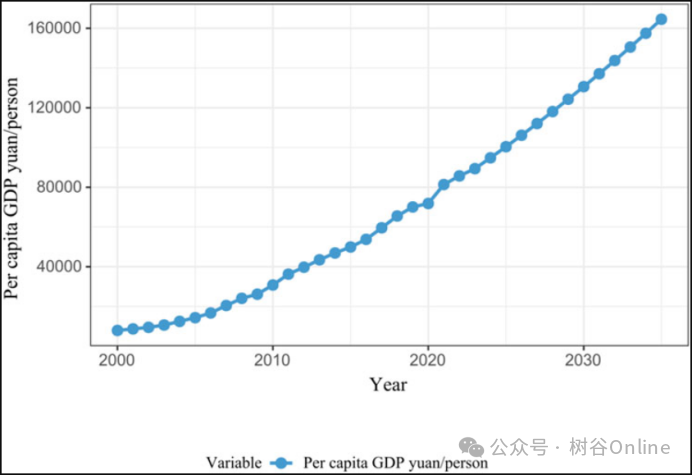
图10.2000-2035年人均GDP预测(单位:元/人)。
4、研究结论
(1)采用ARIMA-BP神经网络模型预测2000—2035年各省碳排放总量。总体来看,我国碳排放总量逐年增加,但随着产业结构的不断优化,增速碳排放量逐渐减少。从碳排放的具体结构变化来看,碳排放总量为“第二产业>居民生活>第三产业>第一产业”,其中第二产业和居民生活的碳增长速度较快,而第一产业和第三产业变化幅度较小。
(2)利用ArcGIS描述中国各省份碳排放的空间分布特征。各省份碳排放空间分布呈现出典型的“东部>中部>西部”和“北部>南部”的不平衡分布格局,反映了不同经济发展阶段碳排放的特征。根据标准椭圆差分析,2000年至2035年碳排放中心将向西北方向移动。
(3)基于新发展理念,将各省份碳排放划分为不同群体,分析群体效应的异质性。数字经济水平高、产业结构先进、新型优质生产力地区碳排放量相对较小,群体差异效应显着,说明产业结构和新业态在减排中的重要性。
(4)基于LMDI分解方法,分析了2000-2035年能源碳排放的驱动因素。我国能源消费强度为“第二产业>第三产业>第一产业”,碳排放强度的降低主要集中在第二产业,能源结构逐渐由煤炭为主向多元化能源结构转变;能源消费强度效应是推动碳排放持续增长的主要因素,人均碳排放量持续增长GDP和能源消费结构效应是抑制碳排放的主要因素。人口规模效应在第一年对碳排放增长有促进作用,但后期大多具有抑制作用,产业结构效应影响相对较小。
数据信息
中国2000年至2035年各省碳排放量数据
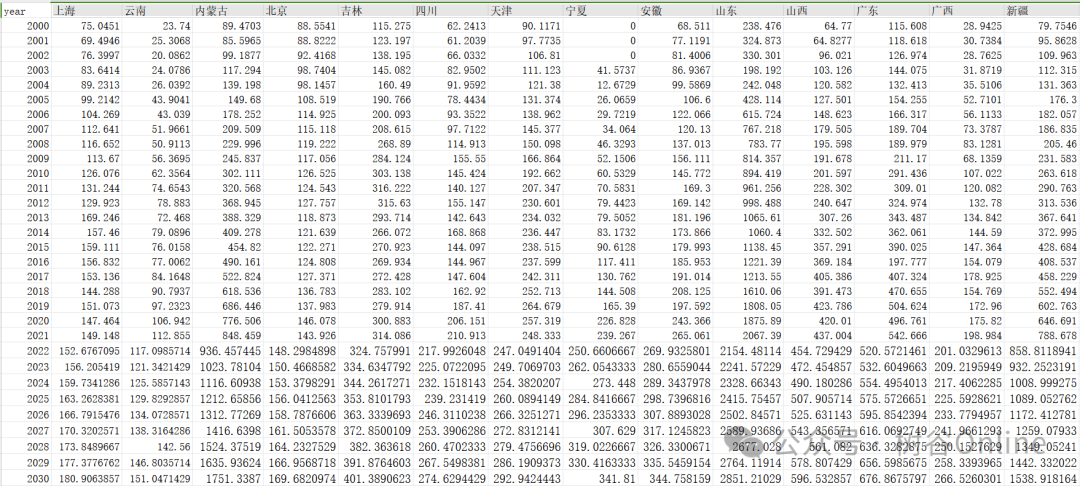
数据格式:xlsx
数据容量:22.05KB
数据时间范围:2000-2035

















 4054
4054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









