




 本文详细介绍了如何使用ARIMA模型预测空气质量指数(AQI)的变化。通过时间序列分析,单位根检验,确定了ARIMA(2,0,1)(0,1)模型为最优模型,并对2016年到2019年的数据进行了预测,验证了模型的有效性。"
51044448,3725625,吴恩达机器学习课程笔记:第一周概要,"['机器学习', '吴恩达', '深度学习', '监督学习', '线性代数']
本文详细介绍了如何使用ARIMA模型预测空气质量指数(AQI)的变化。通过时间序列分析,单位根检验,确定了ARIMA(2,0,1)(0,1)模型为最优模型,并对2016年到2019年的数据进行了预测,验证了模型的有效性。"
51044448,3725625,吴恩达机器学习课程笔记:第一周概要,"['机器学习', '吴恩达', '深度学习', '监督学习', '线性代数']
ARIMA模型是一种常用的时间序列分析方法,用于预测未来的数据趋势。ARIMA代表自回归积分移动平均模型,结合了自回归(AR)、差分(I)和移动平均(MA)三种组件。ARIMA模型适用于具有一定规律性和趋势性的数据集,通过分析数据的自相关性和趋势性,可以更准确地预测未来的走势。ARIMA模型的参数包括自回归阶数(p)、差分阶数(d)和移动平均阶数(q),需要通过对数据集的分析和调参来确定最佳的参数组合。总的来说,ARIMA模型是一种强大的工具,可以帮助我们更好地理解和预测时间序列数据的变化趋势。
本文介绍了如何利用ARIMA模型预测我国AQI(空气质量指数)的变化。具体过程如下:
1.ARIMA模型简介
具有如下结构的模型称之为求和自回归移动平均模型:
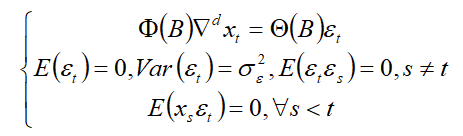
简记为ARIMA(p,d,q)ARIMA(p,d,q)ARIMA(p,d,q)模型,式中∇d=(1−B)d;Φ(B)=1−ϕ1B−⋯−ϕpBp\nabla^d=\left(1-B\right)^d;\quad\Phi(B)=1-\phi_1B-\cdots-\phi_pB^p∇d=(1−B)d;Φ(B)=1−ϕ1B−⋯−ϕp
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 974
974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











