







 超级会员免费看
超级会员免费看
 Zebra项目是一个电信运营商用户上网数据分析应用程序。它涉及日志数据处理、Maven管理、Avro序列化、Zookeeper协调服务等多个技术层面。项目分为ZebraProject、zebra_jobtracker、zebra_engine1_01、zebra_engine1_02和zebra_engine2等模块,实现了数据收集、逻辑切片、RPC通信和数据库落地等功能。项目测试包括启动各引擎和检查数据库中统计结果的完整性。
Zebra项目是一个电信运营商用户上网数据分析应用程序。它涉及日志数据处理、Maven管理、Avro序列化、Zookeeper协调服务等多个技术层面。项目分为ZebraProject、zebra_jobtracker、zebra_engine1_01、zebra_engine1_02和zebra_engine2等模块,实现了数据收集、逻辑切片、RPC通信和数据库落地等功能。项目测试包括启动各引擎和检查数据库中统计结果的完整性。
目录
2、修改ZebraProject的pom.xml文件,添加依赖和插件
3、在main目录创建源目录avro,添加协议文件和模式文件
4、利用avro插件基于模式文件和协议文件生成相应的类和接口
6、创建GlobalEnv类定义全局变量,读取env.properties属性文件
1、修改pom.xml文件,添加对ZebraProject的依赖
4、编写StartJobTrakcer类——利用线程池启动线程
1、修改pom.xml文件,添加对父工程ZebraProject的依赖
3、编写ownenv类,定义变量并且读取ownenv.properties属性文件
4、编写ZkConnectRunner,负责一级引擎节点创建
5、创建StartEngine1_01类,利用线程池启动ZkConnectRunner线程
6、创建rpc服务器端接收jobtracker客户端传递过来的任务
1、创建ZkConnectRunner类,获取两个一级引擎的节点数据(ip和port)
2、创建RpcCilentRunner线程类,负责向一级引擎发送文件切片
3、修改StartJobTracker类,添加发送切片的线程
1、修改pom.xml文件,添加对项目ZebraProject的依赖
3、编写OwnEven类,读取ownenv.properties属性文件
4、编写ZkConnectRunner,负责一级引擎节点创建
5、创建RpcFileSplitImpl类,实现RpcFileSplit接口
7、创建StartEngine1_02类,利用线程池启动ZkConnectRunner线程和RpcServerRunner线程
8、测试一级引擎两个节点能否收到jobtracker发送的文件切片
9、修改zebra_jobtracker模块的RpcClientRunner
10、测试一级引擎两个节点能否收到jobtracker发送的全部文件切片
1、创建MapperRunner类,负责读取文件切片,按|分割、封装成zebra业务对象
4、创建RpcClientRunner,负责向二级引擎发送处理后的map
5、修改StartEngine1_01类,将RpcClientRunner线程添加到线程池
5、测试一级引擎能否收到jobtracker发送的全部文件切片
1、修改pom.xml文件,添加对父工程ZebraProject的依赖
2、创建ZkConnectRunner,负责创建二级引擎节点
2、启动两个一级引擎StartEngine1_01和StartEngine1_02
5、切换到StartEngine1_02的控制台查看输出信息
第一部分 Zebra项目概述
一、Zebra项目介绍
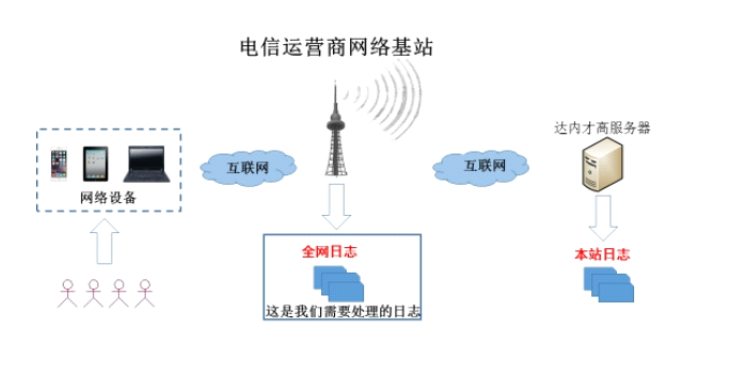
如图所示,电信运营商的用户通过连接到互联网中的各种网络设备访问一个网站时,其访问信息会通过基站在网络中传递,基站可以收集所有用户的访问日志数据。
Zebra项目是对电信运营商收集的用户上网数据进行分析的一个应用程序。通过分析得到的结果可以展现不同小区的上网详情。
二、日志数据结构分析
日志数据文件下载链接:https://pan.baidu.com/s/1fyGCeYvc9MFUPXZmeOwnHw 提取码:tz41
日志里的某一条数据(以下为一整行数据,以| 为分割符

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











