




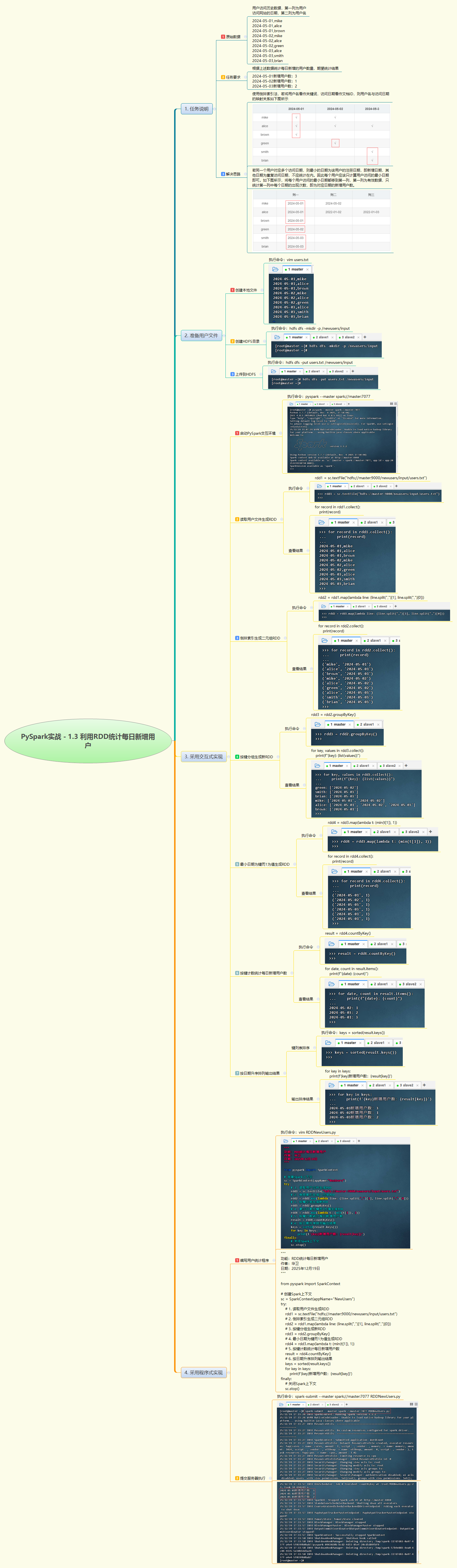
1. 实战概述
- 本次实战基于 PySpark RDD 实现每日新增用户统计。通过读取用户访问日志,构建(用户名, 日期)倒排索引,按用户分组后取最小日期作为注册日,再映射为(日期, 1)并计数,最终输出按日期升序排列的每日新增用户数量,准确反映用户增长趋势。
2. 实战步骤
3. 实战总结
- 本次实战完整实现了“去重+最早时间判定”的典型用户行为分析场景。虽然交互式步骤中使用了
groupByKey()和min()对用户名列表求最小日期(实际应为对日期求最小),但结合任务说明可知其真实意图是:每个用户仅计入其首次出现的日期。程序通过倒排索引、分组、取最早日期、计数等 RDD 转换操作,高效完成统计任务。需注意的是,更优做法是直接以用户名为 key 使用reduceByKey取最小日期,避免groupByKey的数据倾斜风险。脚本成功提交至 Spark 集群并输出正确结果,验证了 RDD 在用户留存与增长分析中的实用价值,为后续构建 DAU、留存率等指标奠定基础。


















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











