




1. 实战概述
- 本次实战利用 PySpark RDD 实现分组 TopN 排行榜功能。通过读取学生成绩数据,构建(姓名, 成绩)二元组,使用
groupByKey按学生分组,对每组成绩降序排序并取前3名,最终按指定格式输出每位学生的最高三门成绩,完整展示了分组排序与 TopN 分析的典型流程。
2. 实战步骤
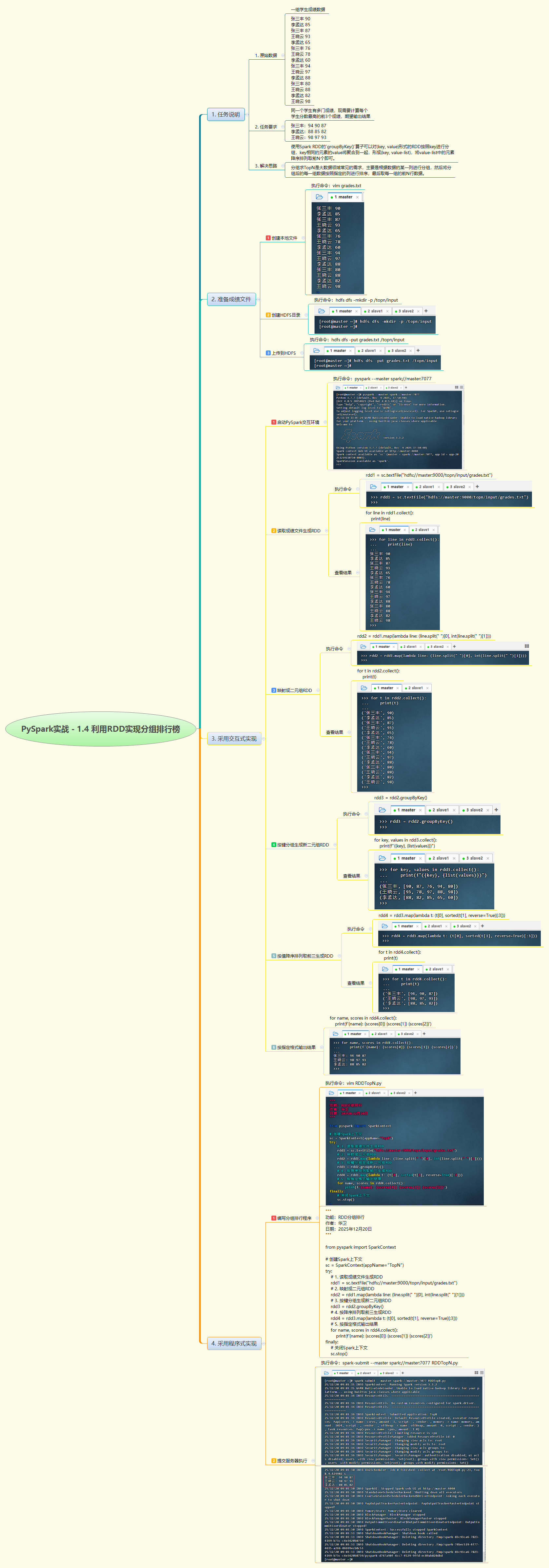
3. 实战总结
- 本次实战成功实现了基于 RDD 的分组 TopN 统计任务,体现了 Spark 在处理“分组内排序”类问题中的灵活性。程序通过
textFile读取 HDFS 数据,经map转换为键值对,再用groupByKey聚合同一学生的全部成绩,最后通过sorted(..., reverse=True)[:3]高效获取前三高分。虽然groupByKey在大数据量下可能引发数据倾斜,但对于中小规模数据或教学场景完全适用。更优方案可采用aggregateByKey或combineByKey减少 shuffle 开销,但本实现逻辑清晰、易于理解。脚本在集群上运行稳定,输出结果符合预期,为后续实现课程排名、用户行为 TopN 等业务场景提供了可靠模板。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











