




1. 实战概述
- 本次实战基于 Spark GraphX 构建学术用户关系网络图,通过 HDFS 加载顶点与边数据,使用
Graph()、fromEdges()和fromEdgeTuples()三种方式创建图对象,并完成缓存管理、数据查询、属性转换、结构重构及外部数据关联聚合等操作,全面验证了 GraphX 在图构建、分析与特征工程中的核心能力。
2. 实战步骤
2.1 用户关系网络图
- 绘制用户关系网络图
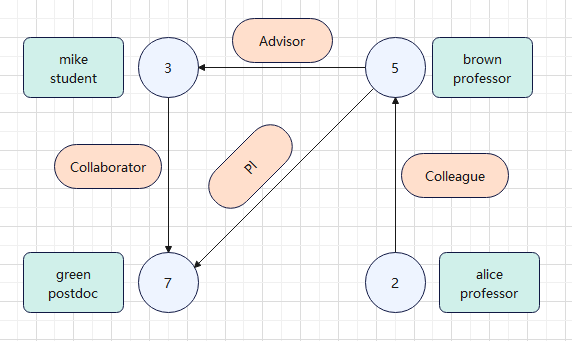
- 该图展示了一个学术用户关系网络:节点代表用户(如学生、教授、博士后),边表示关系(如导师、同事、合作者)。例如,mike 是 brown 的学生,green 与 mike 合作,brown 与 alice 为同事,green 也是 brown 的 PI(在学术语境中,PI 关系中的 PI 是 Principal Investigator(首席研究员) 的缩写)。体现了学术协作与层级结构。
2.2 准备数据文件
2.2.1 创建本地文件
-
创建用户关系网络图顶点数据文件
- 执行命令:
vim vertices.txt
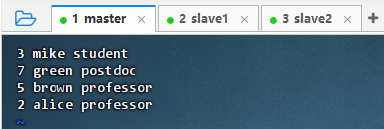
- 执行命令:
-
创建用户关系网络图边数据文件
- 执行命令:
vim edges.txt
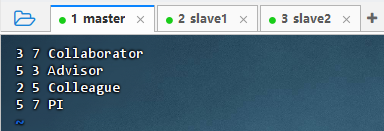
- 执行命令:
2.2.2 创建HDFS目录
- 执行命令:
hdfs dfs -mkdir -p /graphx/data
2.2.3 上传数据文件到HDFS
- 执行命令:
hdfs dfs -put vertices.txt /graphx/data
- 执行命令:
hdfs dfs -put edges.txt /graphx/data
2.3 创建与存储图
2.3.1 创建图
2.3.1.1 导入GraphX包
-
执行命令
import org.apache.spark._ import org.apache.spark.graphx._ import org.apache.spark.rdd.RDD
-
结果说明:该图展示了在 Spark Shell 中成功导入核心包的过程。三条
import语句分别引入了 Spark 核心、GraphX 图计算和 RDD 操作相关类,为后续分布式数据处理和图算法开发做好准备,表明环境配置正确,可进行 Spark 编程。
2.3.1.2 根据有属性的顶点和边创建图(Graph())
-
构造有属性的顶点和边的图
// 创建顶点 RDD val users: RDD[(VertexId, (String, String))] = sc.textFile("hdfs://master:9000/graphx/data/vertices.txt") .map { line => val fields = line.split(" ") (fields(0).toLong, (fields(1), fields(2))) } // 创建边 RDD val relationships: RDD[Edge[String]] = sc.textFile("hdfs://master:9000/graphx/data/edges.txt") .map { line => val fields = line.split(" ") Edge(fields(0).toLong, fields(1).toLong, fields(2)) } // 定义默认用户(用于处理缺失顶点) val defaultUser = ("Black Smith", "Missing") // 构建图对象 val graph_urelate = Graph(users, relationships, defaultUser)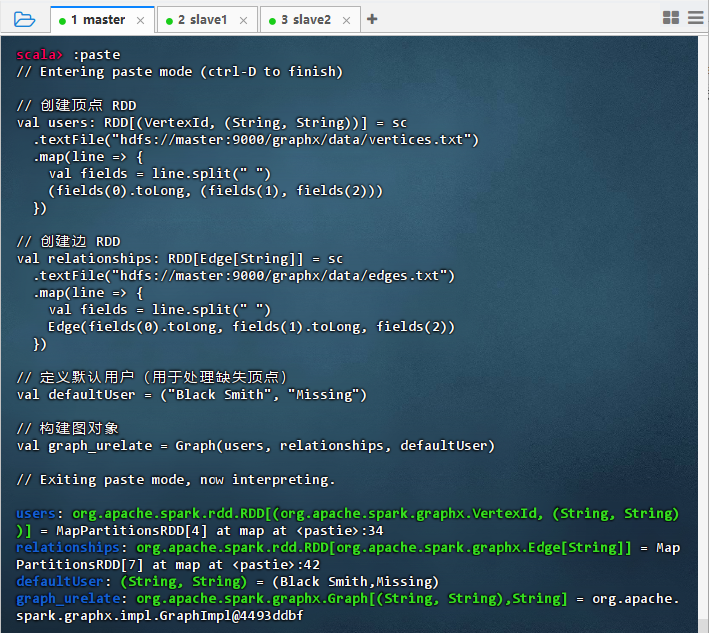
-
结果说明:代码成功在 Spark Shell 中执行,从 HDFS 加载顶点和边数据,构建了 GraphX 图对象。输出显示 users 和 relationships RDD 已创建,defaultUser 定义完成,最终生成 graph_urelate 图实例,表明图结构构建成功,可进行后续图计算操作。
-
查询图的顶点,执行命令:
graph_urelate.vertices.collect.foreach(println)
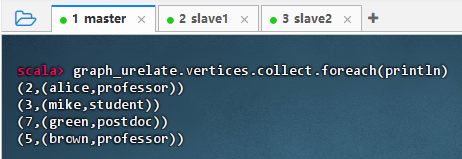
-
结果说明:执行命令后,输出了图中所有顶点的属性信息,显示了每个用户节点的 ID 和对应的角色(如 alice 是 professor,mike 是 student 等),表明图的顶点数据已成功加载并可访问,验证了 GraphX 图结构构建正确。
-
查询图的边,执行命令:
graph_urelate.edges.collect.foreach(println)
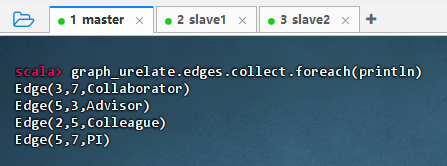
-
结果说明:执行命令后,输出了图中所有边的信息,显示了节点之间的关系类型,如 3 和 7 是合作者(Collaborator),5 和 3 是导师关系(Advisor)等,表明图的边数据已正确加载,验证了用户关系网络结构构建成功。
2.3.1.3 根据边创建图(Graph.fromEdges())
-
利用
Graph.fromEdges()方法创建图// 读取边数据文件 val records: RDD[String] = sc.textFile("hdfs://master:9000/graphx/data/edges.txt") // 解析每行数据为 Edge 对象 val followers: RDD[Edge[String]] = records.map { line => val fields = line.split(" ") Edge(fields(0).toLong, fields(1).toLong, fields(2)) } // 基于边构建图(顶点属性统一设为默认值 1L) val graphFromEdges = Graph.fromEdges(followers, defaultValue = 1L)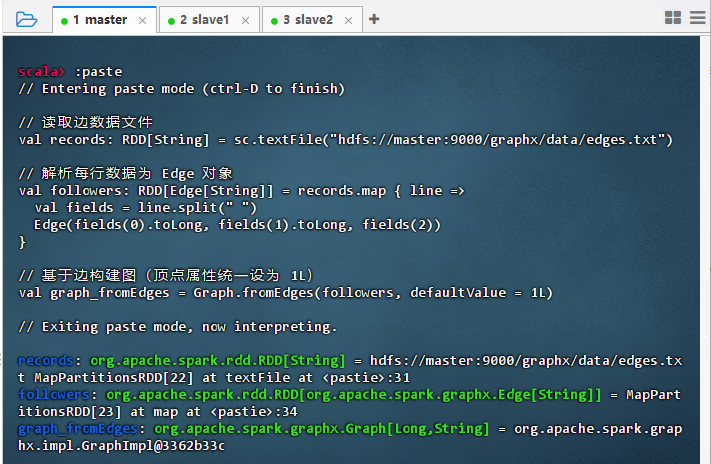
-
结果说明:代码成功从 HDFS 读取边数据并解析为 Edge RDD,构建了图对象
graph_fromEdges。输出显示 records、followers 和 graph_fromEdges 均已正确创建,表明边数据加载和图结构初始化完成,可进行后续图计算操作。 -
查询图的顶点,执行命令:
graph_fromEdges.vertices.collect.foreach(println)
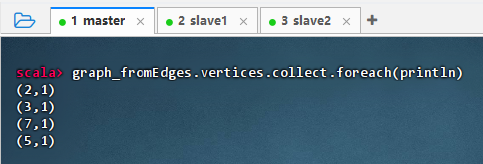
-
结果说明:该命令输出了图中所有顶点的 ID 及其属性,显示每个节点的值均为 1(默认值),表明
Graph.fromEdges成功从边数据推导出顶点集合,并为每个顶点分配了统一的默认属性,验证了图结构构建正确。 -
查询图的边,执行命令:
graph_fromEdges.edges.collect.foreach(println)

-
结果说明:该命令输出了图中所有边的信息,显示了节点之间的关系类型,如 3 和 7 是合作者(Collaborator),5 和 3 是导师关系(Advisor)等,表明边数据已正确加载并保留原始属性,验证了图结构构建成功。
2.3.1.4 根据边的两个顶点的二元组创建图(Graph.fromEdgeTuples())
-
提示:此方式适用于仅需源点和目标点、忽略边属性的场景。若需保留关系类型(如 “Advisor”),应使用 Edge 对象而非二元组。
-
利用
Graph.fromEdgeTuples()方法创建图// 读取边数据文件 val records: RDD[String] = sc.textFile("hdfs://master:9000/graphx/data/edges.txt") // 解析为 (srcId, dstId) 二元组 RDD val edgesRDD: RDD[(VertexId, VertexId)] = records .map(line => line.split(" ")) .map(fields => (fields(0).toLong, fields(1).toLong)) // 基于边二元组构建图(顶点属性设为默认值 1L) val graphFromEdgeTuples = Graph.fromEdgeTuples(edgesRDD, defaultValue = 1L)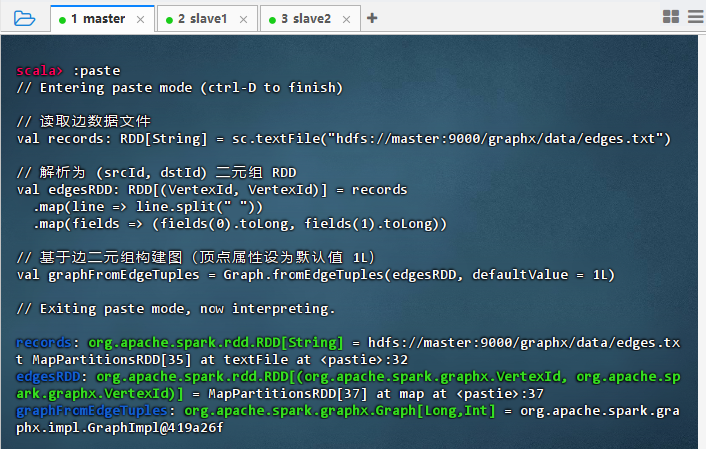
-
结果说明:代码成功从 HDFS 读取边数据,解析为顶点 ID 的二元组 RDD,并通过
Graph.fromEdgeTuples构建图对象。输出显示 records、edgesRDD 和 graphFromEdgeTuples 均已正确创建,表明图结构初始化成功,可进行后续图计算操作。 -
查询图的顶点,执行命令:
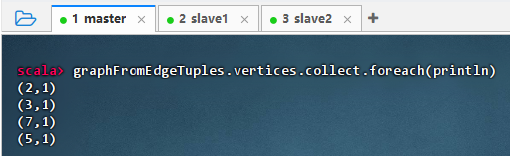
graphFromEdgeTuples.vertices.collect.foreach(println)
-
结果说明:该命令输出了图中所有顶点的 ID 及其默认属性值(1),表明
Graph.fromEdgeTuples成功从边数据推导出顶点集合,并为每个顶点分配统一默认属性,验证了图结构构建正确,顶点信息完整。 -
查询图的边,执行命令:
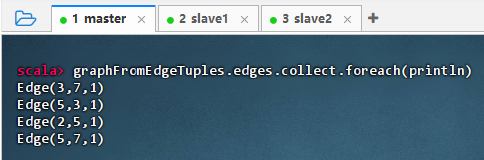
graphFromEdgeTuples.edges.collect.foreach(println)
-
结果说明:该命令输出了图中所有边的结构,显示每条边的源点、目标点及默认属性值(1),表明
Graph.fromEdgeTuples成功构建了边集合,且边数据完整保留,验证了图的边信息正确加载并可访问。
2.3.2 缓存与释放图
2.3.2.1 缓存与释放图概述
- 在 Spark GraphX 中,缓存图是提升性能的重要手段。通过调用
cache()方法(等价于persist(StorageLevel.MEMORY_ONLY)),可将图的顶点和边 RDD 持久化到内存中,从而加速多次访问或迭代计算过程,避免重复的数据加载与转换开销。当图不再需要时,可通过unpersist()主动释放缓存,以回收集群资源;需要注意的是,unpersist()是一个惰性操作,实际的内存释放通常发生在后续任务调度或垃圾回收(GC)时。合理使用缓存机制对 PageRank、连通分量、最短路径等需要多轮迭代的图算法尤为重要,能显著提高执行效率并优化资源利用。
2.3.2.2 缓存与释放图实操
- 缓存级别 -
StorageLevel.MEMORY_ONLY- 执行代码
// 创建图对象引用 val graph = graph_urelate // 1. 缓存图(默认存储级别:MEMORY_ONLY) graph.cache() // 2. 执行多次图操作(缓存生效) println("第一次遍历顶点数: " + graph.vertices.count()) println("第二次遍历顶点数: " + graph.vertices.count()) // 此次将从缓存读取,更快 // 3. 释放图缓存(释放顶点和边的RDD) graph.unpersist()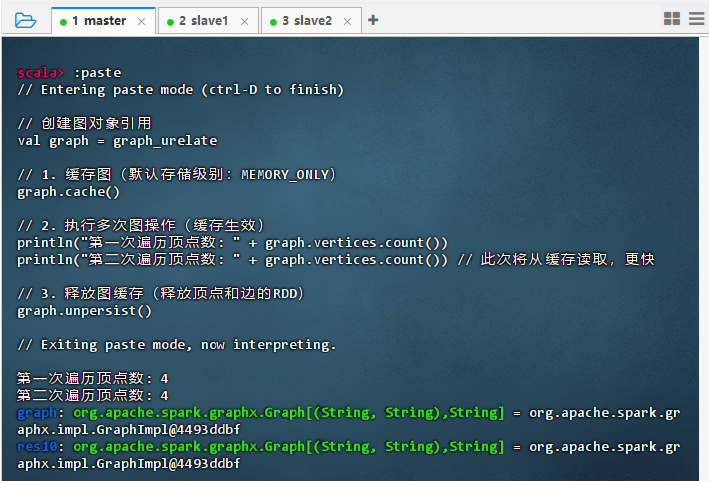
- 结果说明:代码成功创建图对象引用并缓存图,首次遍历顶点数时触发计算并持久化数据,第二次遍历直接从缓存读取,执行更快,验证了缓存机制的有效性;最后通过
unpersist()释放缓存,释放集群资源,表明缓存与释放操作均正确执行。
- 执行代码
- 缓存级别 -
StorageLevel.MEMORY_AND_DISK_SER- 执行代码
// 创建图对象引用 val graph = graph_urelate // 1. 显式指定存储级别(序列化后存入内存和磁盘) import org.apache.spark.storage.StorageLevel graph.persist(StorageLevel.MEMORY_AND_DISK_SER) // 2. 执行多次图操作(缓存生效) println("第一次遍历顶点数: " + graph.vertices.count()) println("第二次遍历顶点数: " + graph.vertices.count()) // 此次将从缓存读取,更快 // 3. 释放图缓存(释放顶点和边的RDD) graph.unpersist()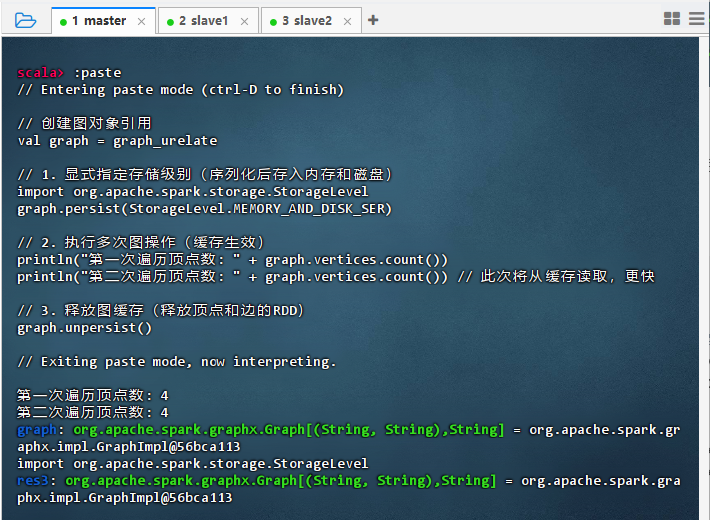
- 结果说明:代码成功创建图对象引用,并显式设置存储级别为
MEMORY_AND_DISK_SER,首次遍历顶点数触发计算并持久化数据,第二次遍历直接从缓存读取,执行更快,验证了序列化缓存机制的有效性;最后通过unpersist()释放缓存,资源回收正常。
- 执行代码
2.4 查询与转换数据
2.4.1 数据查询
2.4.1.1 数据查询概述
- 数据查询用于从图中提取特定顶点或边的信息,包括遍历全部节点/边、按属性过滤(如查找所有教授)、统计数量等操作。通过
vertices、edges等接口结合filter、collect等 RDD 算子,可高效获取所需结构化信息,为分析用户关系提供基础支持。
2.4.1.2 数据查询实操
-
设置图缓存
- 执行命令:
graph.cache()

- 执行命令:
-
查询所有顶点(Vertex)
- 执行代码
graph.vertices.collect().foreach { case (id, attr) => println(s"Vertex ID: $id, Attributes: ${attr._1}, ${attr._2}") }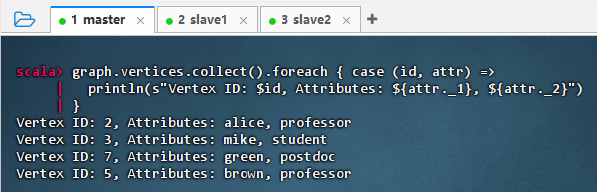
- 结果说明:该命令成功遍历图中所有顶点,输出每个节点的 ID 及其属性(如姓名和角色),显示了 alice 是 professor、mike 是 student 等信息,验证了顶点数据已正确加载并可访问,图结构完整。
- 执行代码
-
查询所有边(Edge)
- 执行代码
graph.edges.collect().foreach { edge => println(s"Edge from ${edge.srcId} to ${edge.dstId} with attribute '${edge.attr}'") }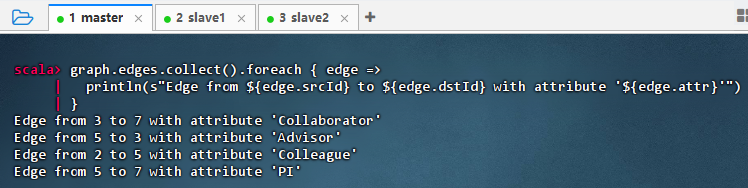
- 结果说明:该命令成功遍历图中所有边,输出每条边的源点、目标点及关系属性(如 Collaborator、Advisor 等),清晰展示了用户之间的关系网络结构,验证了边数据加载完整且可访问。
- 执行代码
-
查询具有特定属性的顶点 - 查找所有教授
- 执行代码
val professors = graph.vertices.filter { case (_, attr) => attr._2 == "professor" } professors.collect().foreach { case (id, attr) => println(s"Vertex ID: $id, Name: ${attr._1}, Role: ${attr._2}") }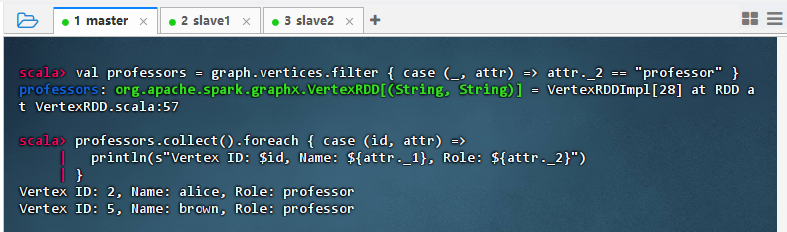
- 结果说明:该命令成功筛选出图中所有角色为 “professor” 的顶点,输出了对应节点的 ID、姓名和角色信息,显示 alice 和 brown 均为教授,验证了基于属性的顶点过滤功能正确有效,数据查询准确。
- 执行代码
2.4.2 数据转换
2.4.2.1 数据转换概述
- 数据转换是指对图的顶点或边属性进行映射、过滤、聚合等操作,生成新图或衍生数据。GraphX 提供
mapVertices、mapEdges、subgraph等方法,支持灵活修改节点角色、更新关系权重、剔除无效连接等,为图分析和算法应用提供结构化、高质量的数据基础。
2.4.2.1 数据转换实操
-
更新顶点属性:在原 role 前添加前缀 “Academic-”
- 执行代码
val graphWithPrefix = graph.mapVertices { case (id, (name, role)) => (name, s"Academic-$role") } graphWithPrefix.vertices.collect.foreach(println)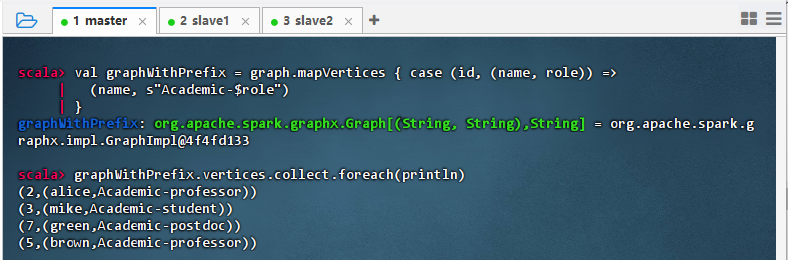
- 结果说明:该命令成功对图中所有顶点的属性进行转换,将角色前缀统一添加为 “Academic-”,输出显示每个节点的姓名与新角色(如 Academic-professor),验证了
mapVertices操作正确执行,顶点属性更新成功且结构完整。
- 执行代码
-
过滤边:仅保留 “Advisor” 关系的边(构建导师子图)
- 执行代码
val advisorSubgraph = graph.subgraph(epred = edge => edge.attr == "Advisor") advisorSubgraph.edges.collect.foreach(println)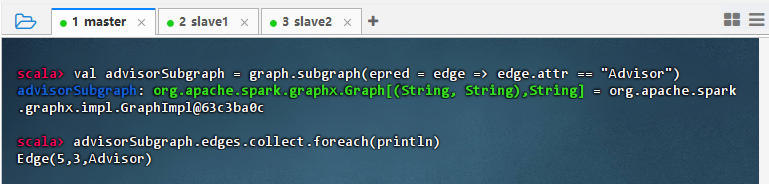
- 结果说明:该命令成功构建了仅包含“Advisor”关系的子图,输出显示边从节点 5 到 3,属性为 “Advisor”,表明导师关系被正确提取,验证了
subgraph方法能有效过滤边并保留指定关系结构,子图构建准确。
- 执行代码
-
转换顶点属性值:将姓名和角色字段统一转为大写形式
- 执行代码
val graphUpper = graph.mapVertices { case (id, (name, role)) => (name.toUpperCase, role.toUpperCase) } graphUpper.vertices.collect.foreach(println)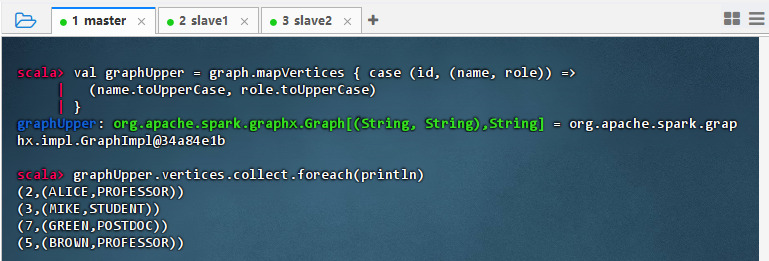
- 结果说明:该命令成功对图中所有顶点的属性进行转换,将姓名和角色字段统一转为大写形式,输出显示每个节点的名称与角色均已标准化(如 ALICE, PROFESSOR),验证了
mapVertices操作正确执行,属性值转换完成且结构保持一致。
- 执行代码
-
添加顶点新属性
- 执行代码
// 定义年龄决定函数 def determineAge(name: String, role: String): Int = { // 根据角色设定年龄 role match { case "student" => 22 case "professor" => 45 case "postdoc" => 30 case _ => 35 // 默认值 } } // 添加新属性age到顶点 val graphWithAge = graph.mapVertices { case (id, (name, role)) => val age = determineAge(name, role) (name, role, age) // 新的顶点属性结构 } // 查看转换后的顶点数据 graphWithAge.vertices.collect().foreach { case (id, attr) => println(s"Vertex ID: $id, Attributes: ${attr._1}, ${attr._2}, ${attr._3}") }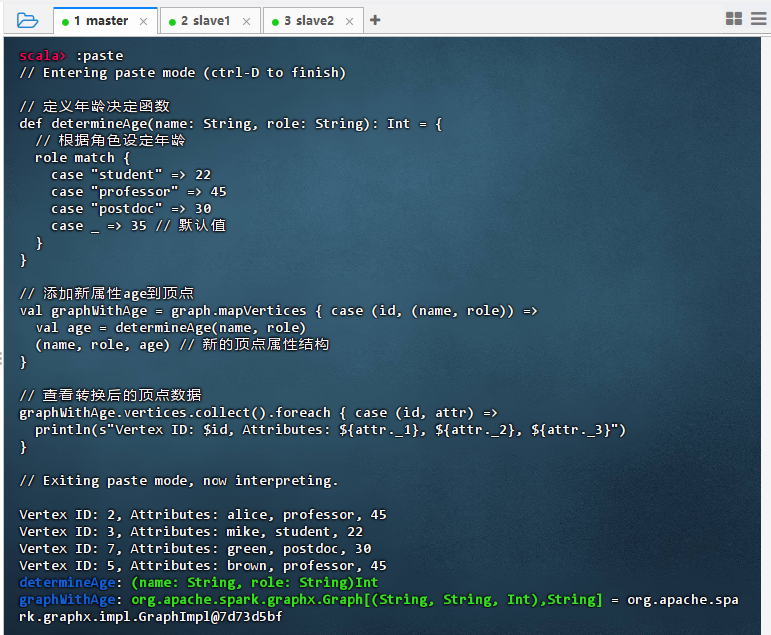
- 结果说明:该代码成功为图中每个顶点添加了新属性
age,根据角色(如 student、professor)设定对应年龄值,输出显示各节点的姓名、角色和年龄信息(如 alice: 45),验证了mapVertices能有效扩展顶点属性结构,实现数据增强。
- 执行代码
-
构建无属性简化图(仅保留结构,顶点属性设为单位值)
- 执行代码
val structuralGraph = Graph.fromEdgeTuples( graph.edges.map(e => (e.srcId, e.dstId)), defaultValue = () ) structuralGraph.vertices.collect.foreach(println)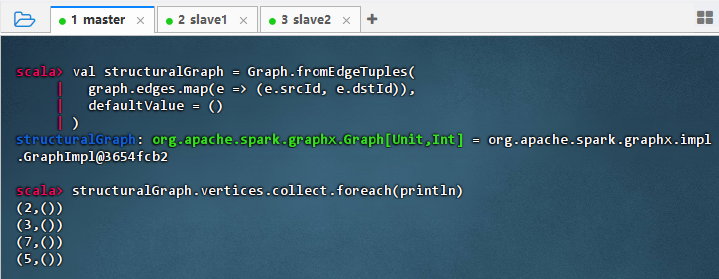
- 结果说明:该代码成功构建了一个仅保留图结构的简化图,顶点属性被统一设为
()(Unit),边信息仅包含源点和目标点,输出显示所有节点 ID 及默认属性,验证了Graph.fromEdgeTuples能有效提取拓扑结构,忽略原始属性,适用于纯结构分析场景。
- 执行代码
-
合并属性:将 name 和 role 合并为单个字符串
- 执行代码
val graphMergedAttr = graph.mapVertices { case (_, (name, role)) => s"$name-$role" } graphMergedAttr.vertices.collect.foreach(println)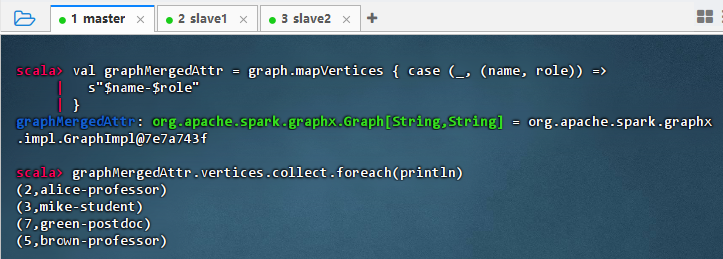
- 结果说明:该代码成功将顶点的姓名和角色属性合并为单一字符串,输出显示每个节点的属性已格式化为“name-role”形式(如 alice-professor),验证了
mapVertices能有效整合多字段信息,简化属性结构,便于后续统一处理或展示。
- 执行代码
2.5 转换结构与关联聚合数据
2.5.1 结构转换
2.5.1.1 结构转换概述
- 结构转换指对图的拓扑结构进行修改,如反转边方向、生成子图、合并顶点或边等,以适应不同分析需求。GraphX 提供
reverse、subgraph、mask等方法,支持灵活调整图的连接关系,在社交网络分析、路径追踪等场景中具有重要作用。
2.5.1.2 结构转换实操
-
反转所有边的方向
- 执行代码
val reversedGraph = graph.reverse graph.edges.collect.foreach(println) reversedGraph.edges.collect.foreach(println)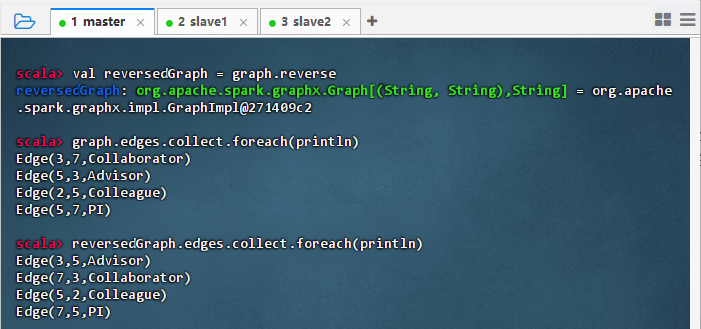
- 结果说明:该命令成功对图进行边方向反转,输出显示原始边如 “5→3” 变为 “3→5”,关系属性保持不变,验证了
reverse方法能有效生成反向图,适用于分析双向关系或逆向路径追踪等场景。
- 执行代码
-
构建仅包含教授和博士后的子图(过滤顶点 + 边)
- 执行代码
val academicSubgraph = graph.subgraph( vpred = { case (id, (name, role)) => role == "professor" || role == "postdoc" }, epred = e => true // 保留所有符合条件顶点之间的边 ) academicSubgraph.vertices.collect.foreach(println) academicSubgraph.edges.collect.foreach(println)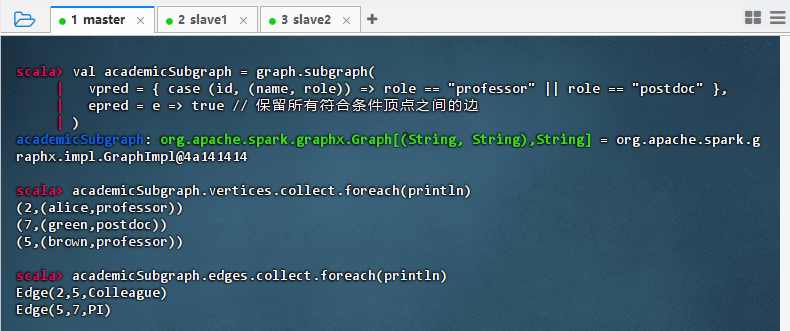
- 结果说明:该命令成功构建了仅包含教授和博士后的子图,输出显示顶点保留了 alice、brown(教授)和 green(博士后),边保留了他们之间的同事与 PI 关系,验证了
subgraph能根据角色条件精准筛选节点并保留其连接结构,适用于聚焦学术核心人员网络分析。
- 执行代码
-
保留原始图中与另一个图共有的结构(mask 操作)
- 执行代码
val smallGraph = graph.subgraph( vpred = { case (id, (name, role)) => role == "professor" || role == "student" }, epred = e => true // 保留所有符合条件顶点之间的边 ) smallGraph.vertices.collect.foreach(println) smallGraph.edges.collect.foreach(println) val maskedGraph = smallGraph.mask(academicSubgraph) maskedGraph.vertices.collect.foreach(println) maskedGraph.edges.collect.foreach(println)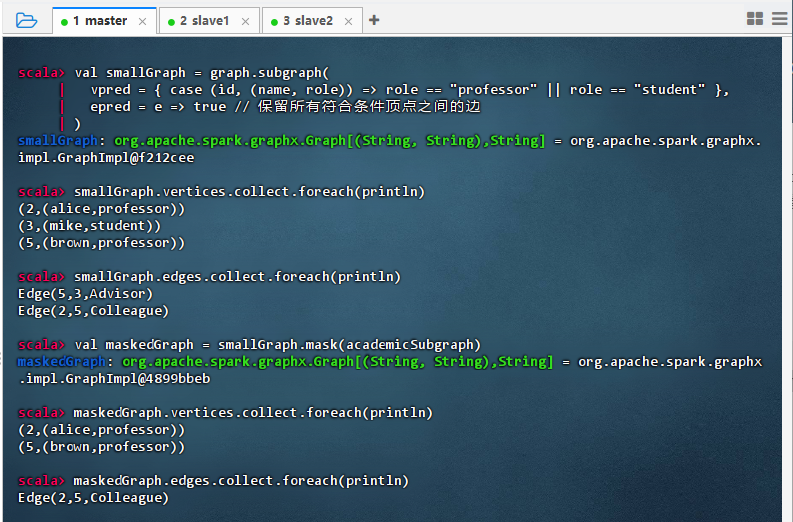
- 结果说明:该命令先构建包含教授和学生的子图,再用学术子图(教授与博士后)进行掩码操作,输出显示仅保留了两个子图的公共顶点(alice、brown)及它们之间的同事边,验证了
mask能实现图结构的交集运算,用于提取多维度关系的重叠部分。
- 执行代码
-
提取图的边方向无关版本(无向图近似)
- 将每条有向边 (src, dst) 补充其反向边 (dst, src)
- 执行代码
val vertices = graph.vertices val undirectedEdges = graph.edges.flatMap { e => Iterator(e, Edge(e.dstId, e.srcId, e.attr)) } val undirectedGraph = Graph(vertices, undirectedEdges, ("Unknown", "Unknown")) undirectedGraph.vertices.collect.foreach(println) undirectedGraph.edges.collect.foreach(println)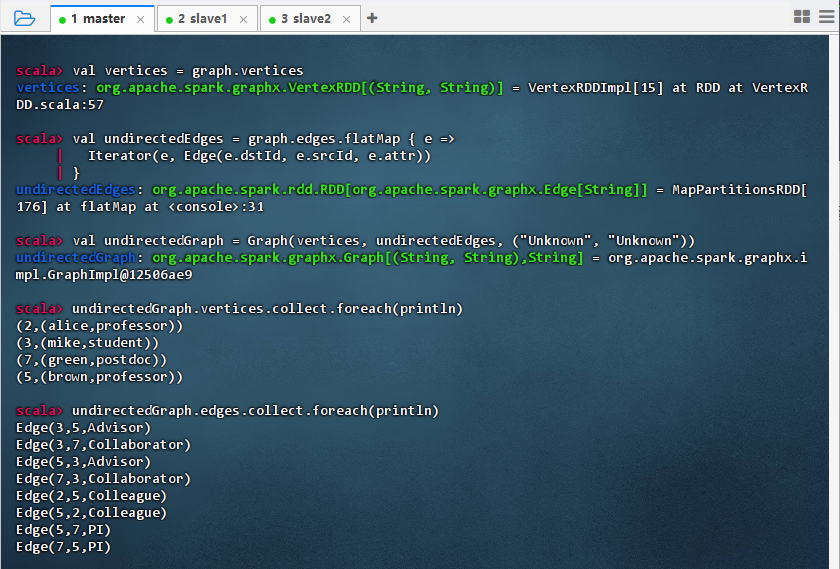
- 结果说明:该命令成功构建了无向图,通过显式传入原始顶点 RDD 保留了所有节点的属性(如 alice-professor、mike-student),并生成双向边(如 Advisor 和其反向),输出显示顶点信息完整保留,边结构对称,验证了在构造无向图时可同时保持原图顶点属性和关系完整性。
2.5.2 数据关联聚合
2.5.2.1 数据关联聚合概述
- 数据关联聚合指将外部数据与图的顶点或边进行连接,并对属性进行统计、汇总或衍生计算。GraphX 提供
joinVertices、outerJoinVertices等方法,支持按顶点 ID 关联新数据(如年龄、评分),并可结合aggregateMessages实现高效的消息传递与聚合,广泛应用于特征增强与图神经网络预处理。
2.5.2.2 数据关联聚合实操
- 准备外部数据:顶点ID -> 年龄
- 执行代码
val ageData: RDD[(VertexId, Int)] = sc.parallelize(Seq( (2L, 45), // alice (3L, 22), // mike (5L, 50), // brown (7L, 30) // green ))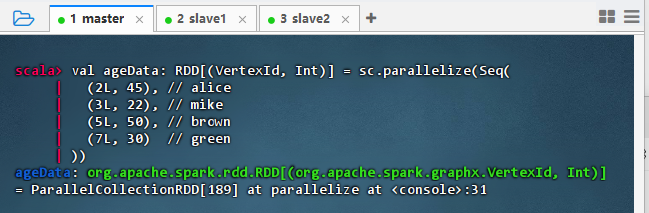
- 结果说明:该命令成功创建了一个包含顶点ID与年龄映射的RDD,输出显示每个用户节点(如alice、mike等)对应其年龄值,验证了外部数据可被正确加载为RDD结构,为后续与图进行关联聚合操作(如joinVertices)提供了基础数据支持。
- 执行代码
- 关联年龄到顶点属性
- 执行代码
val graphWithAge = graph.outerJoinVertices(ageData) { case (id, (name, role), Some(age)) => (name, role, age) // 类型变为三元组 case (id, (name, role), None) => (name, role, -1) // 处理缺失 } graphWithAge.vertices.collect.foreach(println)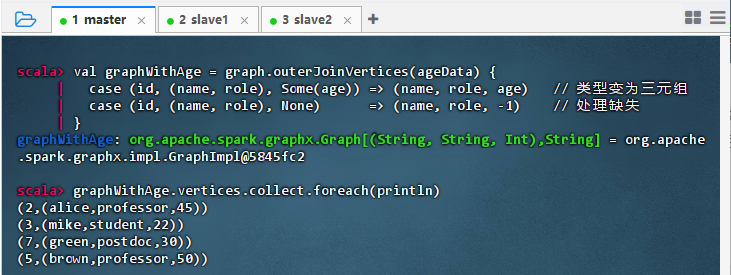
- 结果说明:该命令成功使用
outerJoinVertices将年龄数据关联到图的顶点,输出显示每个节点属性扩展为三元组(如 alice → (alice, professor, 45)),并妥善处理了缺失值(用 -1 填充),验证了外部数据可安全、完整地与图结构融合,实现顶点属性的动态增强。
- 执行代码
- 聚合:统计每个顶点的出度(即“指导/合作人数”)
- 执行代码
// 获取每个顶点的出度 val outDegrees = graph.outDegrees // 使用 outerJoinVertices 添加出度信息到顶点属性中 val graphWithOutDegree = graph.outerJoinVertices(outDegrees) { // 匹配存在的出度信息 case (id, (name, role), Some(deg)) => (name, role, deg) // 处理没有出度信息的情况(理论上图中所有顶点都应该有出度) case (id, (name, role), None) => (name, role, 0) } // 打印结果以验证 graphWithOutDegree.vertices.collect.foreach(println)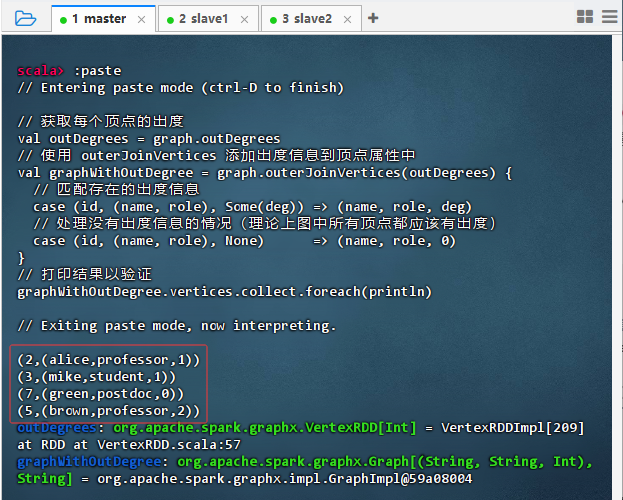
- 结果说明:该命令成功将图中每个顶点的出度信息通过
outerJoinVertices关联到其属性中,输出显示各节点(如 alice、mike 等)的出度值(如 1、1、0、2),验证了顶点属性可动态扩展为三元组(name, role, outDegree),并正确处理了所有节点的连接关系统计。
- 执行代码
- 消息传递聚合:发送“角色+关系”组合信息
- 执行代码
val neighborInfo = graph.aggregateMessages[String]( ctx => { // 向目标节点发送:"[源角色] via [边关系]" ctx.sendToDst(s"[${ctx.srcAttr._2}] via ${ctx.attr}") // 向源节点发送:"[目标角色] via [边关系]" ctx.sendToSrc(s"[${ctx.dstAttr._2}] via ${ctx.attr}") }, (a, b) => a + "; " + b // 用分号分隔多条消息 ) neighborInfo.collect.foreach(println)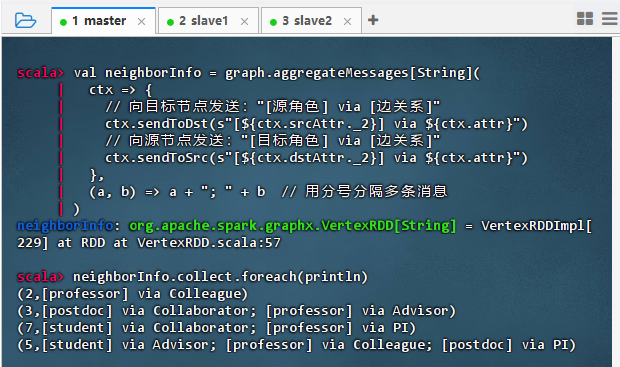
- 结果说明:该命令通过
aggregateMessages成功聚合了每个节点的邻居信息,输出显示每个顶点(如 alice、mike)接收到来自其连接节点的角色与关系描述(如 “[student] via Advisor”),验证了消息传递机制可有效收集并整合图中上下文关联信息,为后续分析提供丰富的语义支持。
- 执行代码
3. 实战总结
- 本次 GraphX 实战系统性地完成了从数据准备到高级图计算的全流程。首先,成功将本地顶点与边数据上传至 HDFS 并构建多种图结构;其次,通过缓存机制优化性能,利用
vertices与edges接口实现灵活查询与过滤;接着,借助mapVertices、subgraph、reverse等方法完成属性增强与拓扑变换;最后,结合outerJoinVertices和aggregateMessages实现外部数据融合与语义化邻居信息聚合。整个过程不仅验证了图结构的正确性与完整性,也展示了 GraphX 在学术关系网络分析中的强大表达力,为后续开展 PageRank、社区发现或图神经网络等高级任务奠定了坚实的数据与技术基础。


















 1344
1344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











