




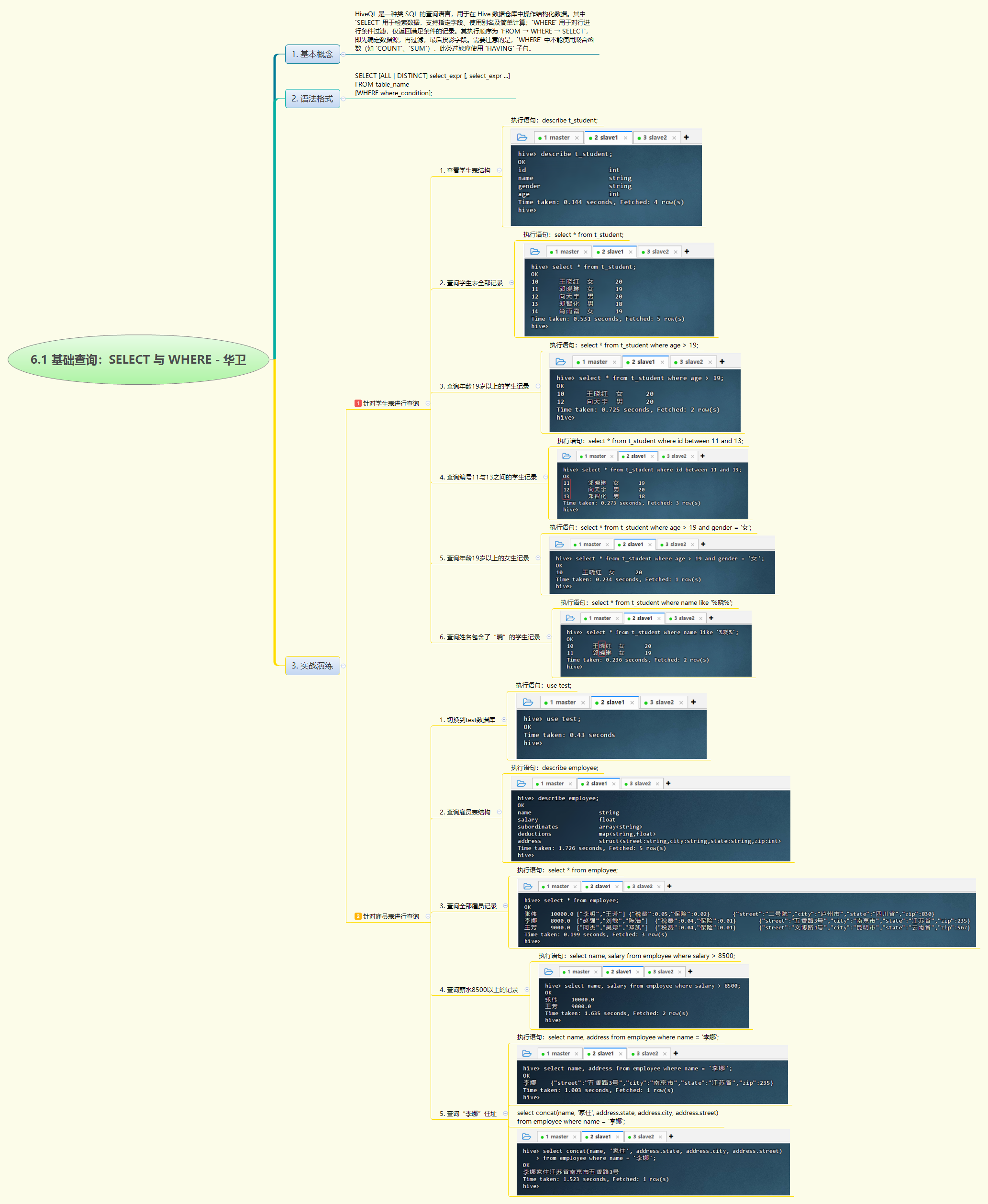
1. 实战概述
- 本次实战围绕Hive基础查询展开,通过学生表和雇员表,演示了
SELECT与WHERE的多种用法,包括全表查询、数值/字符串条件过滤、范围查询(BETWEEN)、集合查询(IN)、模糊匹配(LIKE)及复杂字段(如struct类型)处理,验证了HiveQL在结构化数据检索中的灵活性与高效性。
2. 实战步骤
3. 实战总结
- 本次Hive基础查询实战系统演练了
SELECT与WHERE子句的核心用法。通过对学生表t_student和雇员表employee的操作,全面实践了全表查询、数值比较(如年龄>19)、范围筛选(BETWEEN)、集合匹配(IN)、模糊查询(LIKE)以及复合条件(AND/OR)等常见场景,并成功处理了嵌套结构字段(如address.struct)。实验验证了HiveQL语法与标准SQL的高度兼容性,同时体现了分区裁剪优化潜力及对复杂数据类型的解析能力。所有查询均正确返回预期结果,说明Hive能高效支持日常数据分析任务。整个过程夯实了基础查询技能,为后续聚合、连接等高级操作奠定了坚实基础。


















 7578
7578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











