




1. 实战概述
- 本次实战围绕 Hive 的
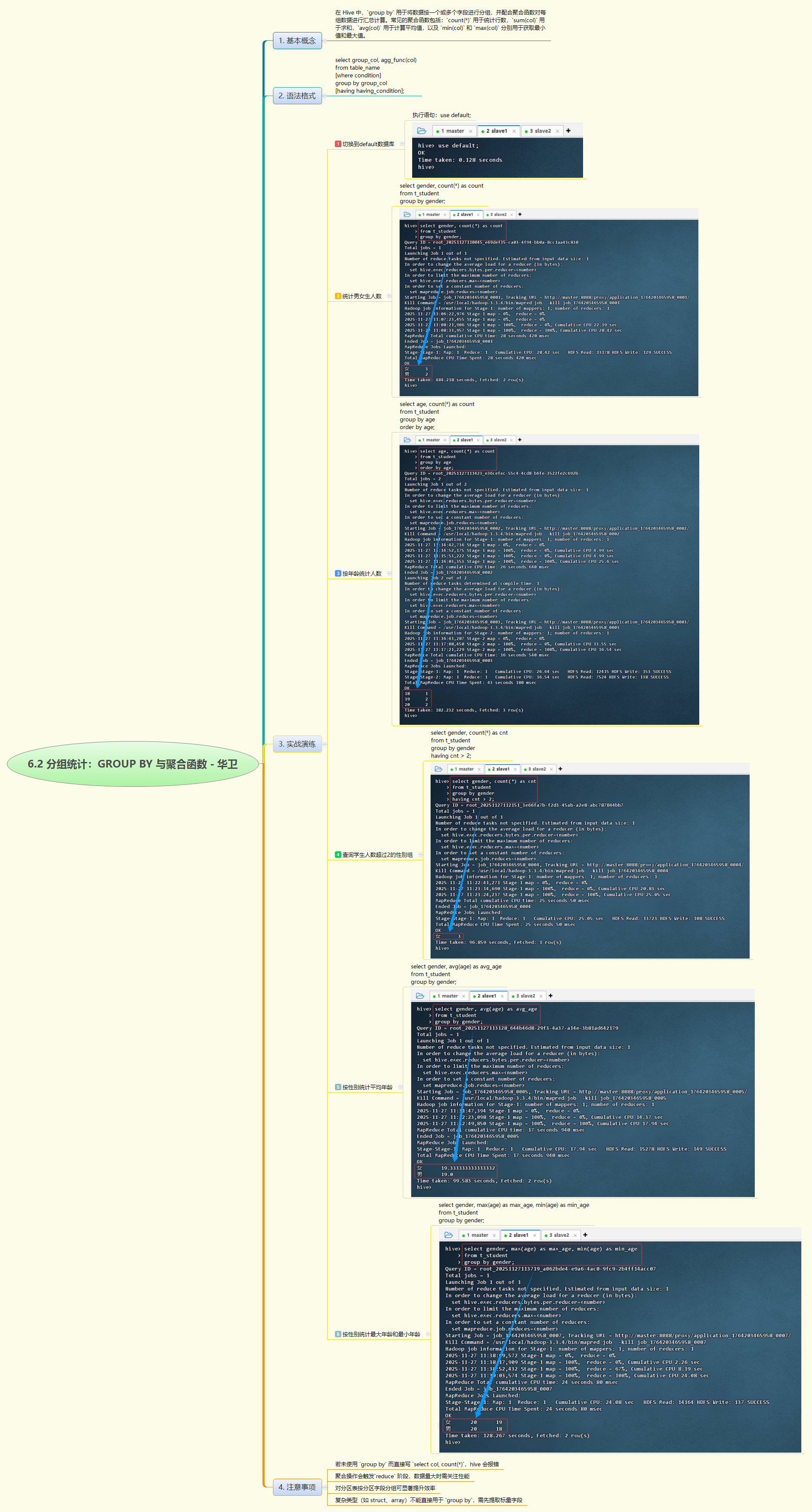
GROUP BY与聚合函数展开,基于学生表t_student进行多维度分组统计,包括按性别、年龄统计人数,使用HAVING筛选分组结果,并计算各性别的平均、最大和最小年龄,全面展示了分组聚合在数据汇总与分析中的核心应用。
2. 实战步骤
3. 实战总结
- 本次 Hive 分组统计实战围绕学生表
t_student,系统演练了GROUP BY与常用聚合函数的结合使用。通过按性别、年龄分组,完成了人数统计、平均年龄计算及最值分析,并借助HAVING子句实现对聚合结果的二次过滤(如筛选人数超过2的性别组)。所有查询均符合语法规则,验证了“非聚合字段必须出现在 GROUP BY 中”的约束机制。实验过程中,Hive 正确生成 MapReduce 任务完成聚合计算,体现了其对结构化数据分析的良好支持。整个过程不仅巩固了分组统计的核心语法,也强化了对执行逻辑(先 WHERE 过滤、再 GROUP BY 分组、最后 HAVING 筛选)的理解,为后续复杂报表开发和数据洞察奠定了坚实基础。


















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











