







 超级会员免费看
超级会员免费看
 本文详细介绍了Spark中的RDD分区,包括分区原则、影响分区的因素,如parallelize()和textFile()方法创建RDD时的分区数量。深入讲解了Spark的Partitioner抽象类以及默认的HashPartitioner,探讨了自定义分区器的创建和使用,以解决特定场景下分区需求的问题。
本文详细介绍了Spark中的RDD分区,包括分区原则、影响分区的因素,如parallelize()和textFile()方法创建RDD时的分区数量。深入讲解了Spark的Partitioner抽象类以及默认的HashPartitioner,探讨了自定义分区器的创建和使用,以解决特定场景下分区需求的问题。
零、本讲学习目标
- 学会如何指定分区数量
- 会定义与使用自定义分区器
一、RRD分区
- RDD是一个大的数据集合,该集合被划分成多个子集合分布到了不同的节点上,而每一个子集合就称为分区(Partition)。因此,也可以说,RDD是由若干个分区组成的。
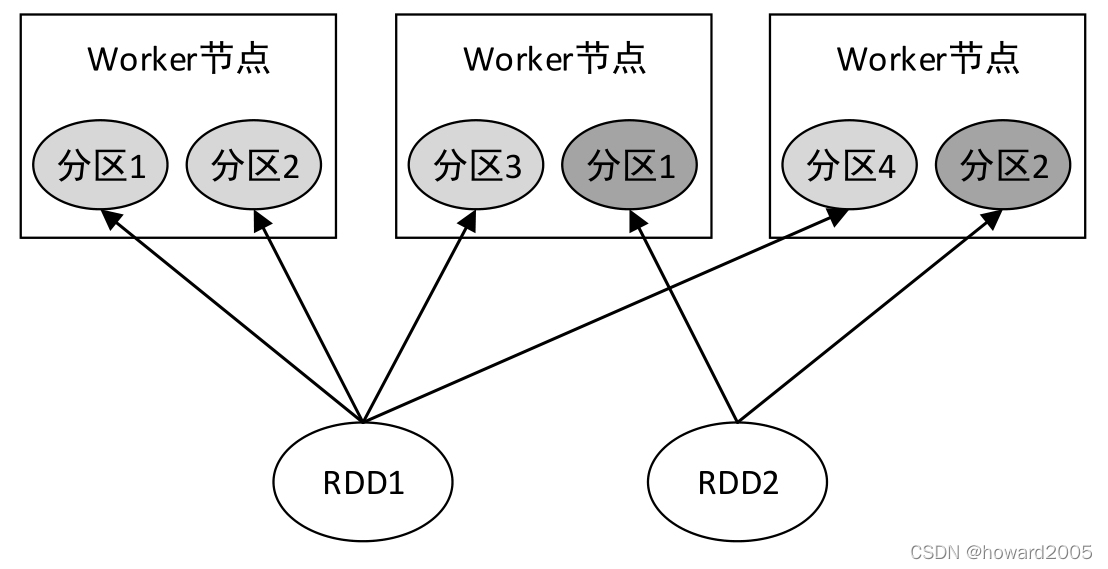
二、RDD分区数量
(一)RDD分区原则
- RDD各个分区中的数据可以并行计算,因此分区的数量决定了并行计算的粒度。Spark会给每一个分区分配一个单独的Task任务对其进行计算,因此并行Task的数量是由分区的数量决定的。RDD分区的一个分区原则是使得分区的数量尽量等于集群中CPU核心数量。
(二)影响分区的因素
- RDD的创建有两种方式:一种是使用parallelize()方法从对象集合创建;另一种是使用textFile()方法从外部存储系统创建。而RDD分区的数量与RDD的创建方式以及Spark集群的运行模式有关。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2057
2057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











