







 超级会员免费看
超级会员免费看
 本文记录了在大数据环境中,通过MapReduce实现词频统计时如何使用Combiner来提高效率的过程。首先提出了任务,然后详细阐述了启动Hadoop服务、上传数据、创建并配置Maven项目等准备工作。接着,逐步讲解了创建Mapper、Reducer、Driver,并在Driver中设置Combiner。通过运行程序,展示了Combiner在map任务和reduce任务之间的合并效果。最后,通过将数据拆分成多个文件,进一步演示了Combiner在提高数据处理效率方面的优势。
本文记录了在大数据环境中,通过MapReduce实现词频统计时如何使用Combiner来提高效率的过程。首先提出了任务,然后详细阐述了启动Hadoop服务、上传数据、创建并配置Maven项目等准备工作。接着,逐步讲解了创建Mapper、Reducer、Driver,并在Driver中设置Combiner。通过运行程序,展示了Combiner在map任务和reduce任务之间的合并效果。最后,通过将数据拆分成多个文件,进一步演示了Combiner在提高数据处理效率方面的优势。
一、提出任务
原始数据:
Hello World Bye World
Hello Hadoop Bye Hadoop
Bye Hadoop Hello Hadoop
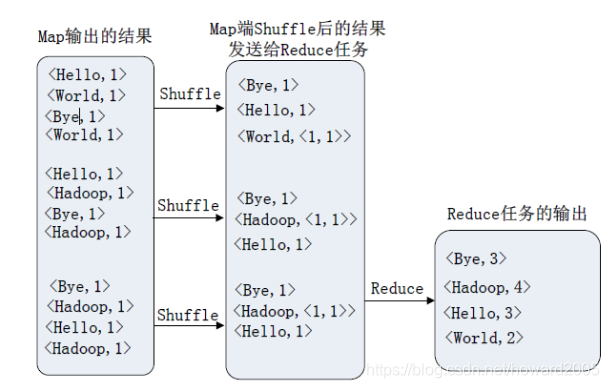
在大数据学习笔记10:MR案例——词频统计中,我们没有采用Combiner做词频统计:
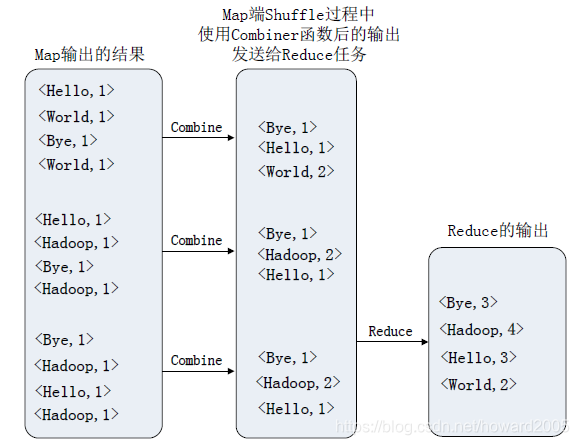
本次学习笔记,采用Combiner做词频统计:
二、准备工作
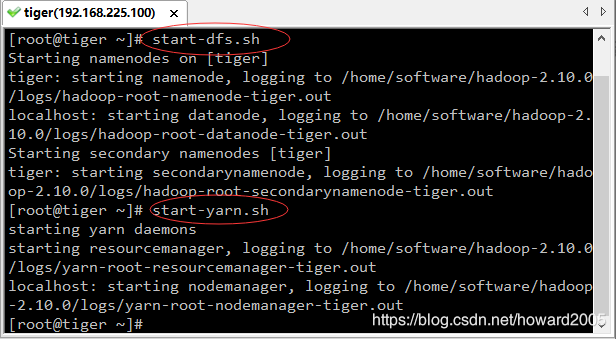
1、启动hadoop服务
原始数据:
Hello World Bye World
Hello Hadoop Bye Hadoop
Bye Hadoop Hello Hadoop
在大数据学习笔记10:MR案例——词频统计中,我们没有采用Combiner做词频统计:
本次学习笔记,采用Combiner做词频统计:
 1838
1838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























